
Исследования никогда не утоляют мой голод к изучению, поэтому в этот раз, они подтолкнули меня к написанию статьи. Тут постарался ответить на возможные насущные вопросы о микросервисной архитектуре.

System Administrator
Исследования никогда не утоляют мой голод к изучению, поэтому в этот раз, они подтолкнули меня к написанию статьи. Тут постарался ответить на возможные насущные вопросы о микросервисной архитектуре.
За последние несколько лет я очень полюбил GitLab CI. В основном за его простоту и функциональность. Достаточно просто создать в корне репозитория файл .gitlab-ci.yml , добавить туда несколько строчек кода и при следующем коммите запустится пайплайн с набором джобов, которые будут выполнять указанные команды.
А если добавить к этому возможности include и extends, можно делать достаточно интересные вещи: создавать шаблонные джобы и пайплайны, выносить их в отдельные репозитории и повторно использовать в разных проектах без копирования кода.
Но к сожалению, не всё так радужно, как хотелось бы. Инструкция script в GitLab CI очень низкоуровневая. Она просто выполняет те команды, которые ей переданы в виде строк. Писать большие скрипты внутри YAML не очень удобно. По мере усложнения логики количество скриптов увеличивается, они перемешиваются с YAML делая конфиги нечитаемыми и усложняя их поддержку.
Мне очень не хватало какого-то механизма, который бы упростил разработку больших скриптов. В результате у меня родился микрофреймворк для разработки GitLab CI, про который я и хочу рассказать в этой статье (на примере простого пайплайна для сборки docker-образов).

Существует огромное количество руководств, статей, видеоуроков по bash. И это очень здорово, но есть одна проблема с ними. Процент материала "для начинающих" среди всего этого богатства стремится к 100, а вот по-настоящему интересных тонкостей касаются не только лишь все.
Я всегда любил bash-скриптинг, и сейчас пишу довольно много кода на bash. Периодически наталкиваюсь на неочевидные моменты; решил, что настала пора поделиться опытом с уважаемым хабрасообществом.
Кому интересно разобраться, что же может быть не так с bash/zsh на этот раз -- добро пожаловать под кат.

Однажды к нам пришёл клиент с просьбой настроить approve rules для merge request в бесплатной версии GitLab CE. В статье я подробно расскажу, как мы подошли к решению этой задачи, какие проблемы нам пришлось преодолеть и каким образом мы смогли обеспечить соблюдение всех необходимых процессов проверки и апрувов без перехода на платную версию GitLab.

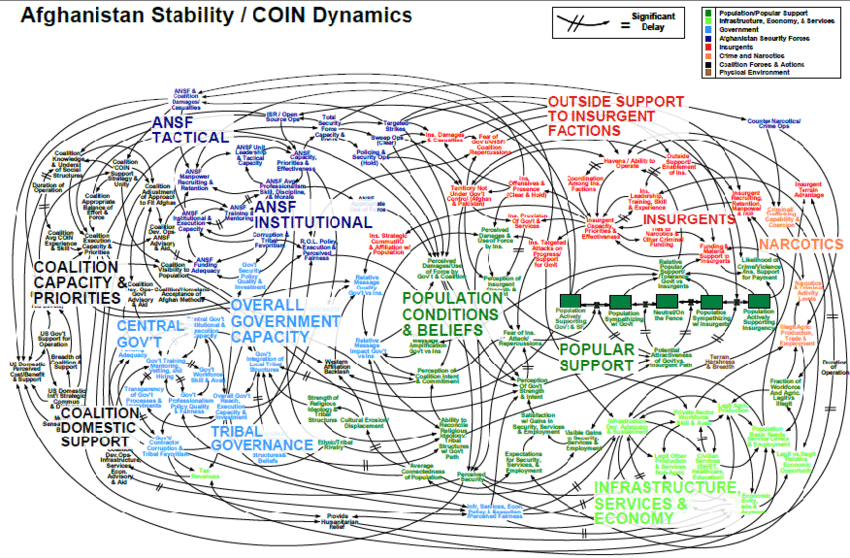
Периодически общаюсь с разработчиками о микросервисах, монолитах и прочих мифических существах. Удивляет, какая эзотерика живёт в головах у людей, иногда слышишь такое, что ёжики в тумане нервно курят в сторонке.
Когда спрашиваю у людей на собесах, или когда в команде решаем, как клепать очередной проект, такое порой слышу, что становится страшновато. Мне кажется, лет через 5 все компании будут обитать в мультивселенной безумия из “микросервисов”, которую они себе радостно построили, уходя от этих ваших страшных “монолитов”.
Дай думаю поделюсь инфой, чтобы наше с вами будущее не было наполнено болью, страданием и борьбой с последствиями тех дурацких решений, которые можно напринимать прямо сейчас с той кашей в голове, которую я вижу у людей по этой теме.

Мартышка и АйТи: Парадокс сложной эффективности
Вы когда-нибудь задумывались, почему в IT всё циклично? Почему старые методы и технологии, которые когда-то были на пике популярности, возвращаются на сцену?
Давайте разберёмся, что такое Парадокс сложной эффективности на простом примере, а также посмотрим, как это работает в IT последние 30 лет.

Привет всем! В предыдущей статье мы подробно рассмотрели реализацию непрерывной доставки CD в платформе Gitorion на базе Jenkins. В данной статье мы подробно рассмотрим тонкости внедрения системы единого входа Single Sign-On (SSO) во все сервисы платформы Gitorion при помощи Keycloak.

Если вам доводилось использовать HAProxy для балансировки трафика, вы наверняка как минимум слышали, что этот продукт умеет отслеживать показатели активности сервиса и пользователей и реагировать на них по предопределённым условиям. Обычно в статьях на эту тему приводится пример ограничения пользователя по исходному IP-адресу, если частота запросов с него превышает некоторый предопределённый заранее лимит. Вот, к примеру, такая статья с сайта разработчиков.
Я бы хотел немного углубиться в тематику использованного механизма stick tables, но поговорить не про пользователей, активно интересующихся вашим сайтом, а про нагрузочную способность, или ёмкость, всего сайта (ну или каких-то его путей). Во-первых, любой сервис ограничен в количестве одновременных запросов, которые возможно обслужить на существующих ресурсах. Во-вторых, чаще всего у сервиса не одна площадка или хотя бы не один экземпляр балансёра. А это значит, что поймать одинокого пользователя — это, конечно, здорово, но хотелось бы решить и другую интересную задачу: защитить сервис от перегрузки в целом и в случае, если балансёров более одного. Бонусом поговорим о проблеме умного перераспределения нагрузки между локациями.

Представим ситуацию, что мы деплоим по push-модели. В качестве платформы для запуска деплоя у нас используется Gitlab: в нём настроен пайплайн и джобы, разворачивающие приложения в разные окружения в Kubernetes
Какой бы инструмент мы не использовали (kubectl, helm), для манипуляций с ресурсами API нам в любом случае будет необходимо аутентифицироваться при выполнении запросов к Kubernetes. Для этого в запросе надо передать данные для аутентификации, будь то токен или сертификат. И тут возникает несколько вопросов:
1. Где хранить эти креды?
Хранить креды от кластера можно, например, в Gitlab CI/CD Variables и подставлять в джобу деплоя, но тогда потенциально все пользователи будут деплоить с одними и теми же доступами
2. Как сделать так, чтобы у каждого пользователя были свои данные для доступа в кластер?
Можно было бы вручную запускать джобы деплоя и в параметры каждый раз подставлять свои аутентификационные данные, но, очевидно, такой подход неудобен и подходит далеко не всем
А что если сделать так, чтобы в качестве провайдера аутентификационных данных для Kubernetes выступал сам Gitlab? Тогда не надо было бы нигде хранить креды, и каждый пользователь мог бы аутентифицироваться в кубере под своей учёткой при запуске деплоя
Как мы к этому пришли? Как мы стали вместо решения наших задач, тратить кучи денег на решение проблем, которых у нас нет?

Используя Ansible в качестве инструмента автоматизации, часть приходится сталкиваться с задачей обработки и фильтрации структурированных данных. Как правило, это набор фактов, полученных с управляемых серверов, или ответ на запрос к внешним API, которые возвращают данные в виде стандартного json. Многие неопытные инженеры, используя Ansible в таких случаях, начинают прибегать к помощи привычных консольных команд и начинают городить то, что среди специалистов получило название bashsible. В общем, вспоминается известный мем:

«Мы хотим сделать систему по учету персонала. Только у наших архитекторов есть требование, что все у нас должно быть на микросервисах». Это, пожалуй, самый бесячий заход, который нам приходится слышать, как разработчику Jmix – платформы быстрой разработки корпоративных веб-приложений. Почему только микросервисы? Какие проблемы, кроме независимого развертывания они решают? Это действительно необходимо для всех типов приложений? Мы, для полного понимания, ни в коем случае не являемся противниками микросервисной архитектуры, однако неистово сопротивляемся слепому следованию «карго культа». Часто случается, что ничего, кроме удорожания разработки, поддержки и эксплуатации такие решения не приносят. Собственно, об этом и пишет Nikolas Frankel, автор статьи, перевод которой представлен ниже.

Во время технических презентаций нашей технологии – платформы быстрой разработки Jmix – мы, как правило, доходим до вопроса архитектуры создаваемых приложений и часто встречаем грусть в глазах разработчиков, когда сообщаем, что создаваемое приложение имеет монолитную архитектуру. Удивительно, но случается, что команды разработки приложений на Delphi или Oraсle EBS непременно заинтересованы в реализации микросервисной архитектуры, отождествляя ее с чем-то очень современным и самым продвинутым. К счастью, хайп вокруг микросервисов постепенно начал замещаться новой информационной повесткой о необходимости рационального использования ресурсов и выбора типа архитектуры приложений на основе компетенций команд разработчиков и масштабов создаваемого решения. В Jmix есть все необходимое, чтобы создавать современные корпоративные информационные системы в рекордные сроки и с минимальными затратами. Мы понимаем, что монолитная архитектура приложений Jmix не может закрыть все кейсы, но мы верим, что для каждой задачи есть подходящий инструмент. Прочитайте перевод статьи из блога Camunda, возможно, она поможет понять какой тип архитектуры подходит для вашего проекта, чтобы сэкономить время, деньги и нервы.
В статье поговорим об отличиях микросервисной архитектуры от монолитной и разберемся, что лучше подойдет для вашего следующего проекта.

Журнал событий, это компонент systemd, который захватывает сообщения Syslog, логи ядра, все события при инициализации системы (RAM, диск, boot, STDOUT/STDERR для всех сервисов), индексирует их и затем предоставляет удобной пользовательский интерфейс для поиска и фильтрации логов. Журнал (systemd journal) можно использовать вместе или вместо syslog или syslog-ng.
Утилита командной строки journalctl, если сравнивать ее с традиционным инструментами для работы с логами в UNIX (tail, grep, sed, awk) более широкие возможности.
Давайте рассмотрим основные возможности которые предоставляет журнал systemd и способы их применения.

Представьте, что есть проект, где 200 разработчиков, 20+ независимых продуктовых команд и у каждой свой собственный DevOps. Они всё автоматизируют — все довольны и занимаются исключительно своей работой. Разработчики даже успевают красить зелёные кнопочки в красный цвет. У DevOps современные инструменты и они помогают автоматизировать релизы. У каждого product owner независимая команда, он никем не блокируется, планирует свой бэклог, быстро двигается и развивается. А “эффективный менеджер” больше не сомневается стоит ли разрешать разработчикам самим катить в продакшен. Представили? Тогда прикинем, что может случиться с ними через год.
Обо всем этом и об интересном подходе к разработке в Ситилинке расскажет Константин Осипов — руководитель DevOps, QA и 140+ backend/fronted-разработчиков. Он познакомит нас с проблемами, которые стояли перед командой разработки и с тем, как они их решили. Поделиться своими мыслями, как не надо делать и объяснит как перестать быть эникейщиком. А главное, как со своими задачами в разработке справляются в Ситилинке.
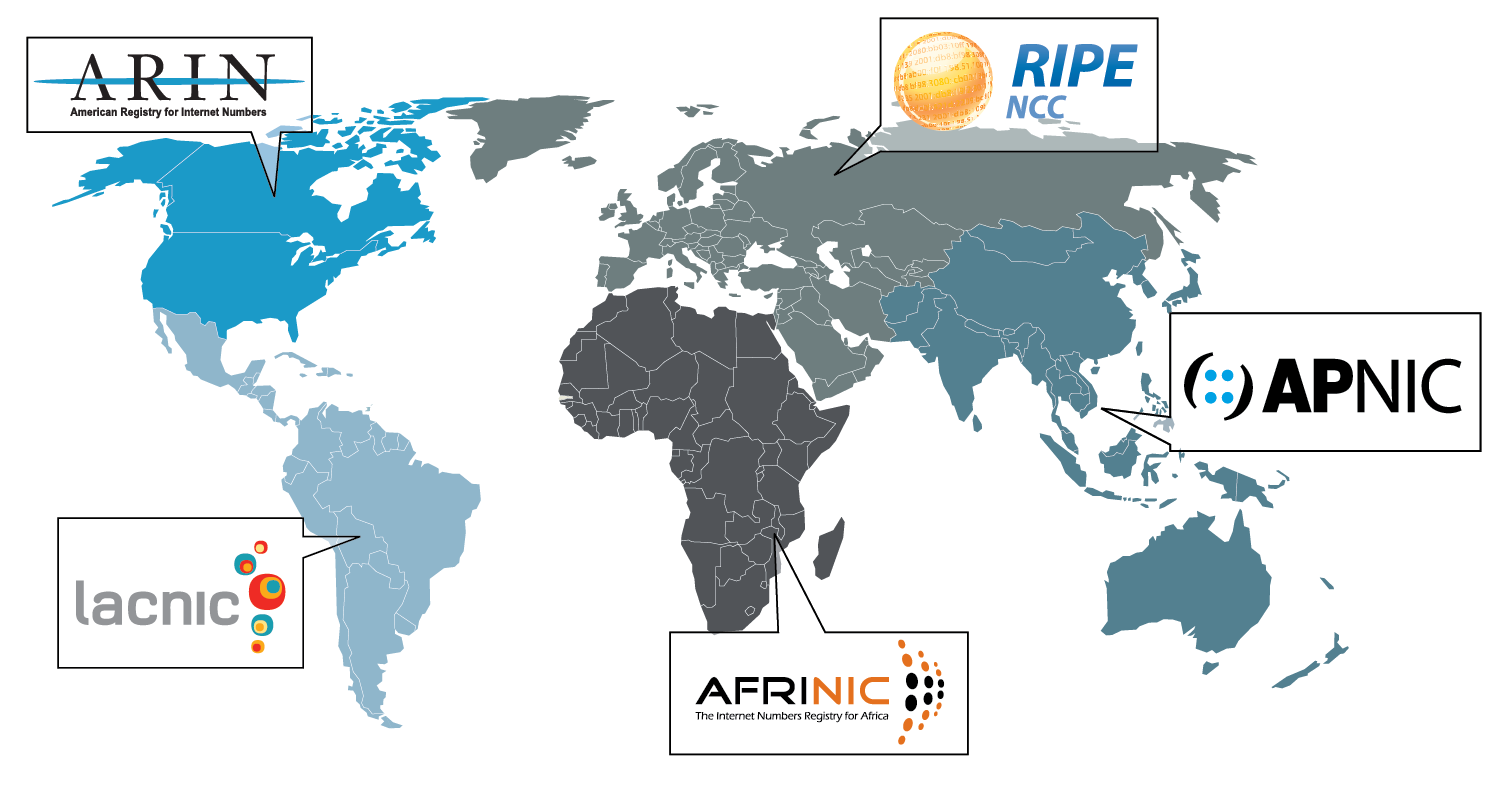
Мир меняется. И в текущей ситуации становится полезным список IP-адресов, условно принадлежащих автономным системам той или иной страны.
В этой статье вы узнаете, как получить список префиксов, анонсируемых автономными системами любой страны. Если вы, конечно, не знали этого раньше.


На эту тему на Хабре была не так давно статья, и там высказывалась мысль, что программирование-де сложная область знаний в принципе и требует некой особой склонности и серьезного бэкграунда.
Однако с этим я согласиться никак не могу. Программирование по содержанию ничуть не сложней многих других отраслей знаний, а в чем-то даже и легче, особенно когда касается прикладных задач. Наткнулся на заметку человека, который высказал весьма небанальную мысль: при обучении программированию "с нуля" этот "ноль" для всех сильно разный. И у меня есть стойкое убеждение, что сложность освоения четко зависит от значения этого нуля. А вот почему он разный и что на него влияет- мне и хотелось бы поразмышлять.

Разбираемся, зачем экранам 500 Гц, почему телевизор не монитор, за сколько часов выгорит OLED и как вообще это всё работает.

Jenkins — один из наиболее популярных инструментов CI/CD. Он позволяет автоматизировать каждый этап жизненного цикла программного обеспечения: от создания до развертывания. В этой статье Кирилл Борисов, Infrastructure Engineer технологического центра Deutsche Bank, расскажет о параметрах в Jenkins и о том, как решить проблему хардкода с их помощью.