
Алфавитная идеология и буквенный символизм

Мне попался в руки тематический выпуск «Социолингвистика правописания» (2015) журнала Written Language and Literacy. Проблемы политизации орфографии хорошо знакомы на постсоветском пространстве — Таллин или Таллинн (а в 1930 он и вовсе был Талин!), Чимкент или Шымкент? — но аналогичные противостояния возникали по всему миру, во все времена. Интереснее всего, когда политизированные прения возникают по поводу состава алфавита.
Так, испанцы, владевшие Филиппинами с 1521, перевели тагальский — основной язык Филиппин — на латиницу без использования ⟨k⟩: как и в испанской орфографии, звук [k] обозначался при помощи ⟨c⟩ или ⟨qu⟩. В 1892 филиппинские революционеры назвали свою подпольную организацию KKK (Kataastaasang Kagalang-galang na Katipunan, «высочайшая и самая почётная организация»): символом борьбы против испанской власти они избрали тройную «анти-испанскую» букву. В 1898 в войну за независимость Филиппин включились США, испанцы были разгромлены, филиппинский флаг украсился буквами KKK, а орфография повстанцев стала официальной: алфавит (abakada) принял вид ⟨a, b, k, d, e…⟩ — тогда как «колониальные» буквы ⟨c⟩ и ⟨q⟩ из него были исключены. В 1987, когда антиколониальная борьба осталась далеко позади, филиппинский алфавит вновь гармонизировали с испанским: поставили ⟨k⟩ на привычное место перед ⟨l⟩, и разрешили использовать ⟨c, f, j, ñ, q, v, x, z⟩ в собственных именах и заимствованиях.











 Когда-то давно у меня была
Когда-то давно у меня была 


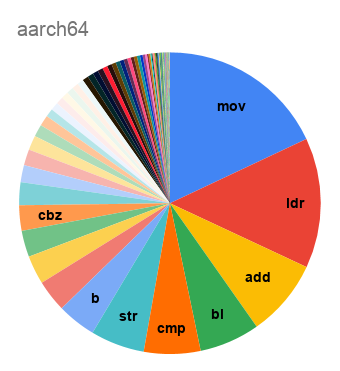

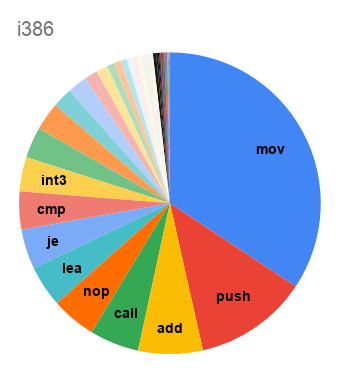
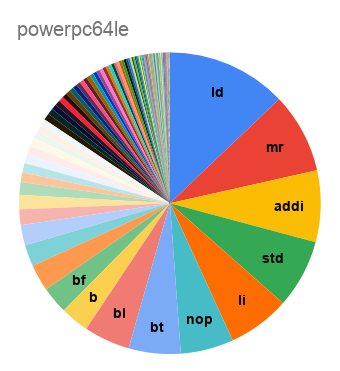
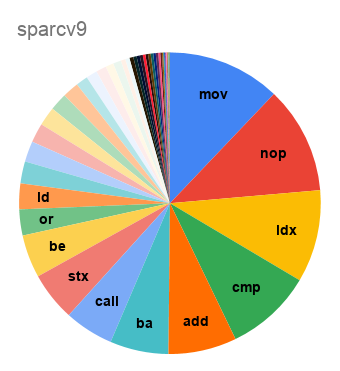

{kind=link}