За недолгое время моего процесса обучения я понял одну вещь – знаниями нужно делиться. Осознал я это давно, но лень перебороть и найти время не всегда получается.
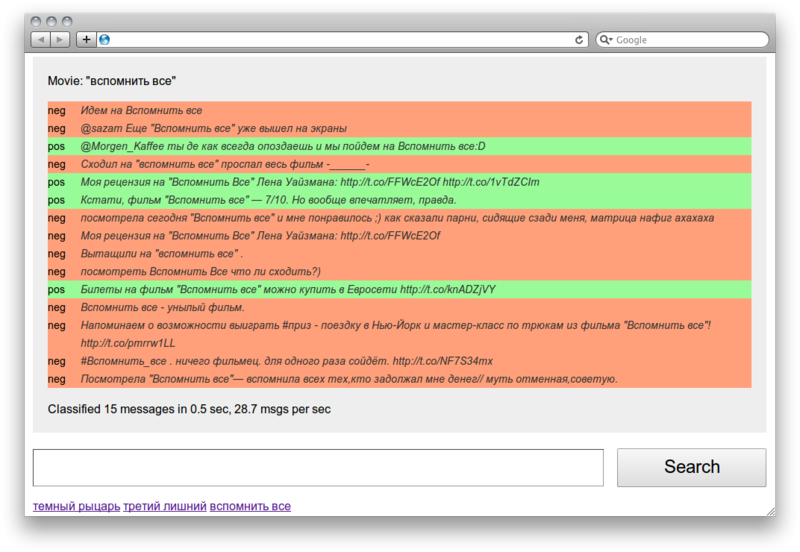
Речь в этой статье пойдет про использование различных методов машинного обучения для решения проблем, связанных с обработкой естественного языка (NLP). Одной из таких проблем является автоматическое определение эмоциональной окраски (позитивный, негативный, нейтральный) текстовых данных, то есть анализа тональности (sentiment analysis). Цель этой задачи состоит в определении, является ли данный текст (допустим обзор фильма или комментарии) положительным, отрицательным или нейтральным по своему влиянию на репутацию конкретного объекта. Трудность анализа тональности заключается в присутствии эмоционально обогащенного языка — сленг, многозначность, неопределенность, сарказм, все эти факторы вводят в заблуждение не только людей, но и компьютеров.

На хабре уже не раз появлялись статьи связанные с определением тональности
1,
2,
3. Да и вообще, эта тема является одной из самых обсуждаемых во всем мире в последнее время [1, 2, 3, 4].
Сразу обговорю, что в этой статье особо никаких новшеств вы не найдете, данный материал скорее всего может послужит туториалом для новичков в сфере машинного обучения и NLP, коим я и являюсь. Основной же материал, который я использовал вы можете найти
по этой ссылке. Весь исходный код вы можете найти
по этой ссылке.
Итак, в чем же состоит проблема и как ее решить?



 Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.
Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.



 Обладатели неновых смартфонов со скромным объемом оперативной памяти (160 в моем случае) очень скоро начинают ощущать тормоза при работе. Поставил буквально несколько программ, а переключение между ними уже сопровождается ощутимыми задержками, и вызов Quick Settings становится уже совсем не «quick».
Обладатели неновых смартфонов со скромным объемом оперативной памяти (160 в моем случае) очень скоро начинают ощущать тормоза при работе. Поставил буквально несколько программ, а переключение между ними уже сопровождается ощутимыми задержками, и вызов Quick Settings становится уже совсем не «quick». 
 Под катом находится небольшое, но полезное описание того, как быстро и просто превратить пришедший JSON-ответ в набор объектов. Никакого ручного парсинга. А если вы сталкивались с OutOfMemory проблемой на старых смартфонах – и для этого есть решение, поддерживающее Android 2.X версий.
Под катом находится небольшое, но полезное описание того, как быстро и просто превратить пришедший JSON-ответ в набор объектов. Никакого ручного парсинга. А если вы сталкивались с OutOfMemory проблемой на старых смартфонах – и для этого есть решение, поддерживающее Android 2.X версий.