
Многие материалы по нейронным сетям сразу начинаются с демонстрации довольно сложных архитектур. При этом самые базовые вещи, касающиеся функций активаций, инициализации весов, выбора количества слоёв в сети и т.д. если и рассматриваются, то вскользь. Получается начинающему практику нейронных сетей приходится брать типовые конфигурации и работать с ними фактически вслепую.
В статье мы пойдём по другому пути. Начнём с самой простой конфигурации — одного нейрона с одним входом и одним выходом, без активации. Далее будем маленькими итерациями усложнять конфигурацию сети и попробуем выжать из каждой из них разумный максимум. Это позволит подёргать сети за ниточки и наработать практическую интуицию в построении архитектур нейросетей, которая на практике оказывается очень ценным активом.
В статье мы пойдём по другому пути. Начнём с самой простой конфигурации — одного нейрона с одним входом и одним выходом, без активации. Далее будем маленькими итерациями усложнять конфигурацию сети и попробуем выжать из каждой из них разумный максимум. Это позволит подёргать сети за ниточки и наработать практическую интуицию в построении архитектур нейросетей, которая на практике оказывается очень ценным активом.



 Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей 




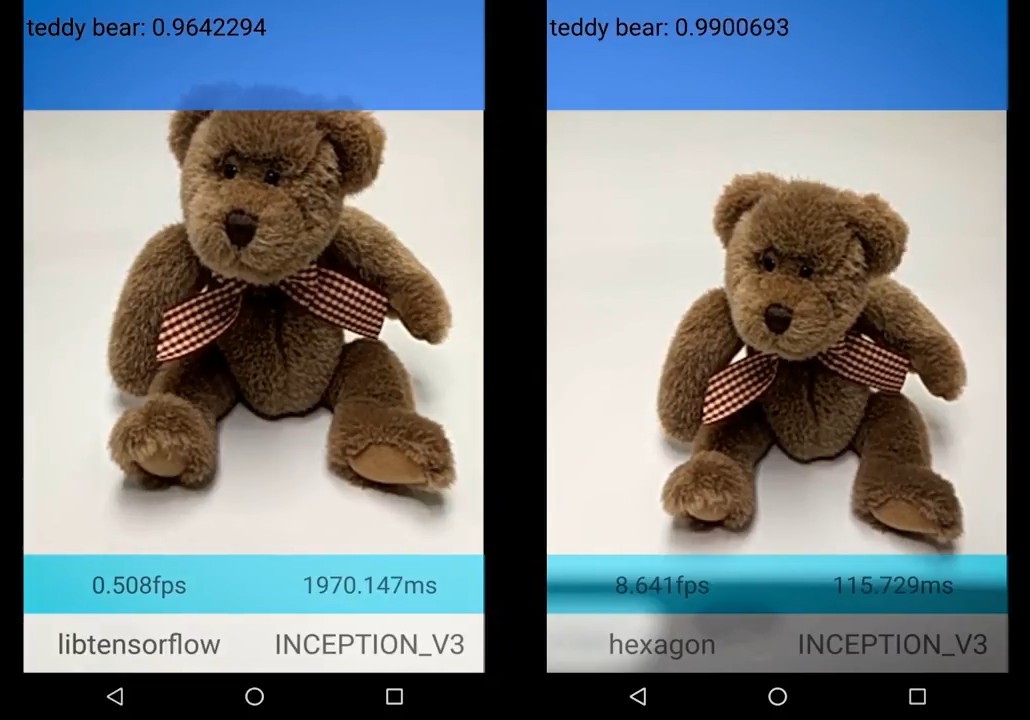

 В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой.
В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой.