Недавно здесь проскакивала тема расписания занятий, и мне захотелось рассказать о своем опыте построения алгоритма составления расписания для ВУЗа, а точнее, больше об эвристике, которую применил.

Штясек Матей @matthew_shtyasek
Пользователь
Генетический алгоритм, нейросеть играет в догонялки
4 мин

Нейронка (#) учится убегать от бота (@). Изначально она вообще не знает - что нужно делать. Однако, с каждым следующим поколением, эволюционным путем формируется требуемый паттерн поведения. На видео можно наглядно пронаблюдать, как с каждым поколением ей это удается все лучше и лучше. Это лишь один из запусков, в другой раз - поведение может быть иным, например - сетка может бегать вдоль стены по кругу.
Моделирование движения космических объектов (симулятор гравитации)
Простой
6 мин
Туториал

Моделирование планетарного ускорения, солнечной системы и взаимодействия любого количества объектов на космической карте в замкнутой системе!
Оптимизация генеративной модели на основе дистилляции
Средний
9 мин

Одним из важнейших направлений работы над моделями машинного обучения является их оптимизация. Оптимизированная модель работает быстрее, требует меньше вычислительных ресурсов, и как следствие — снижает себестоимость работы ПО, использующего модель. Для задач, когда существует ограничение по типам изображений при использование генеративных моделей, возможный путь оптимизации — дистилляция существующих "больших" универсальных моделей. Например Stable Diffusion (далее — SD).Также для некоторых задач, связанных с демонстрацией пользователям изображений, необходимо как можно скорее выводить результат генерации.
Таким образом, нашей целью является сокращение издержки на аренду серверов с GPU и уменьшение времени на генерацию при незначительной потере качества. Одним из возможных вариантов оптимизации SD является метод дистилляции.
Целостность, точность, согласованность: три фактора, обеспечивающие качество машинного обучения
4 мин
Перевод

Эффективность моделей машинного обучения напрямую зависит от обучающих данных. Если данные неполны или размечены неверно, то эти пробелы отразятся на прогнозах модели.
Но как выявлять высококачественные данные и обеспечивать их уровень уже в процессе работы над проектом? И что означает «качество данных» в контексте машинного обучения?
Можно упростить ответ на этот вопрос, сведя качество данных к трём основным характеристикам: целостности (integrity), точности (accuracy) и согласованности (consistency).
- Целостность: надёжность используемого датасета
- Точность: степень валидности и корректности присвоенных аннотаций
- Согласованность: степень согласованности присвоенных аннотаций во всём датасете
Можно воспринимать каждый из этих факторов как часть высокоуровневой дорожной карты для обеспечения качества данных на всех этапах конвейера аннотирования.
Как правильно дифференцировать дискретные функции (Часть 1. Тестируем и улучшаем Numpy)
Простой
6 мин

После того как я реально «подсел» на чтение Хабра, захотелось «освежить» что‑то из своего богатого математического прошлого. Воскресить, так сказать, старые наработки, зайдя, естественно, через дверь с табличкой Python. Предлагаемая публикация посвящена простейшим методам численного дифференцирования дискретных функций (они же решетчатые функции, они же табличные функции, они же функции, заданные набором данных и т. п.). Очень странно, что в библиотеках Python с такой простой темой не все так просто и безоблачно, есть кое‑какие вопросы и проблемы. SciPy, как оказалось, вообще не об этом, а в NumPy «тема не раскрыта». На простейших примерах рассмотрим то, что предлагает NumPy, что там не так и как можно сделать лучше.
Сбор данных для машинного обучения: этапы, методики и рекомендации
15 мин
Перевод

Все успешные компании постоянно собирают данные. Они отслеживают поведение людей в Интернете, организуют опросы, мониторят отзывы, слушают сигналы от умных устройств, извлекают значимые слова из электронных писем и предпринимают другие шаги для накопления фактов и чисел, помогающих им принимать бизнес-решения. Хотя современный мир изобилует данными, сбор ценной информации включает в себя множество организационных и технических трудностей, которые мы и рассмотрим в этой статье. Особое внимание мы уделим методикам сбора данных и инструментам для аналитики и проектов машинного обучения.
Принципы SOLID: как писать хорошо масштабируемый и поддерживаемый код
7 мин
Перевод

Вам когда-нибудь говорили, что вы пишете плохой код?
Здесь стыдиться нечего. Мы все пишем несовершенный код, когда только учимся. Хорошая новость в том, что улучшить его — довольно просто, главное — желание.
Один из лучших способов улучшить свой код — освоить принципы проектирования в объектно-ориентированном программировании. Можно сказать, что принципы программирования — это философия кода или руководство, как стать более крутым программистом.
Существует целый ряд принципов в программировании (я бы даже сказал, что их слишком много), но я расскажу о пяти основных, которые складываются в аббревиатуру SOLID.
Менеджеры контекста в Python
4 мин
Перевод
Почти десять лет назад я показал краткое введение в менеджеры контекста (пункт 2 здесь) и думал, что стану активнее пользоваться такими менеджерами. Но вспомнил я о них только недавно, на фоне того, как много мне приходилось перенастраивать и очищать тестируемый код при опытах по параллелизму (код получался одновременно неприятным и некрасивым).
Посмотрите спецификацию PEP 343: там описано, что суть менеджеров контекста в следующем: «позволить вычленять в отдельные блоки стандартные варианты использования инструкций try/finally». Мне всегда казалось, что finally тяготеет к обработке исключений. Но это не столько обработка ошибок, сколько очистка. Конечно, вы должны быть в состоянии обеспечить качественную очистку в случае, если выброшено исключение, но её к тому же необходимо обеспечить, несмотря на то, что вы покидаете область видимости. Думаю, здесь мы слишком полагались на вызовы функций как на основную рабочую единицу, что отвлекало нас от области видимости как от более общей концепции. Эта тема особенно интересна в сравнении с временами жизни в Rust.
Посмотрите спецификацию PEP 343: там описано, что суть менеджеров контекста в следующем: «позволить вычленять в отдельные блоки стандартные варианты использования инструкций try/finally». Мне всегда казалось, что finally тяготеет к обработке исключений. Но это не столько обработка ошибок, сколько очистка. Конечно, вы должны быть в состоянии обеспечить качественную очистку в случае, если выброшено исключение, но её к тому же необходимо обеспечить, несмотря на то, что вы покидаете область видимости. Думаю, здесь мы слишком полагались на вызовы функций как на основную рабочую единицу, что отвлекало нас от области видимости как от более общей концепции. Эта тема особенно интересна в сравнении с временами жизни в Rust.
Бережем время, деньги, нервы: наш опыт улучшения справочника факторов для ML-моделей оценки риска. Часть 2
12 мин

Всем привет! С вами дата-сайентисты банка «Открытие» Иван Кондраков, Константин Грушин, Станислав Арешин и Алексей Дьяков. Часто даже самые хорошие произведения, будь то фильмы, книги или компьютерные игры, остаются без сиквела. А еще чаще сиквел просто не дотягивает до оригинала… К счастью, это не наш случай! Мы возвращаемся с прямым продолжением нашей статьи о программной генерации длинного списка факторов. И, поверьте, мы следовали всем правилам хорошего сиквела: наш сиквел держит планку качества, продолжает идеи оригинала, при этом полезной информации в нем еще больше!
Что нужно знать нашим ML-сотрудникам
9 мин

Недавно в комментариях к одному из постов в Варим ML меня спросили, какие навыки и знания нужны, чтобы у нас работать. Вопрос на самом деле очень важный - без правильного ответа невозможно нормально выстроить процессы найма и развития сотрудников. Можно быстро набросать дефолтный список - питончик, ML/DL, докер, и на этом закончить, но я решил зарыться в вопрос пообстоятельнее. Конечно, существуют самые разные родмапы, но лично мне они кажутся излишне общими, а я захотел поразмышлять именно про те скиллы, которые необходимы для работы в Цельсе, а главное про их необходимый уровень.
ChatGPT — лучший помощник программиста. Примеры реальных задач. Плагины и инструменты
Простой
9 мин

Языковая модель ChatGPT никогда не заменит программиста, потому что непосредственно редактирование кода — это крохотная часть разработки (5% по времени). Зато ChatGPT великолепно помогает. И чем выше ваш скилл — тем больше пользы от «подмастерья», выполняющего мелкие задания и черновой кодинг. Он пишет простые функции, генерирует документацию, находит и объясняет ошибки, выполняет кучу других задач (полный список под катом).
Сегодня не использовать ChatGPT просто глупо… Это действительно универсальный помощник, который сильно облегчает жизнь и выводит программирование на принципиально новый уровень. Одно из величайших изобретений в IT за десятилетия, после GUI и интернета.
Пожалуй, никогда программирование не было настолько приятным и эффективным, как сейчас.
Как сделать торгового робота для Binance
Простой
12 мин
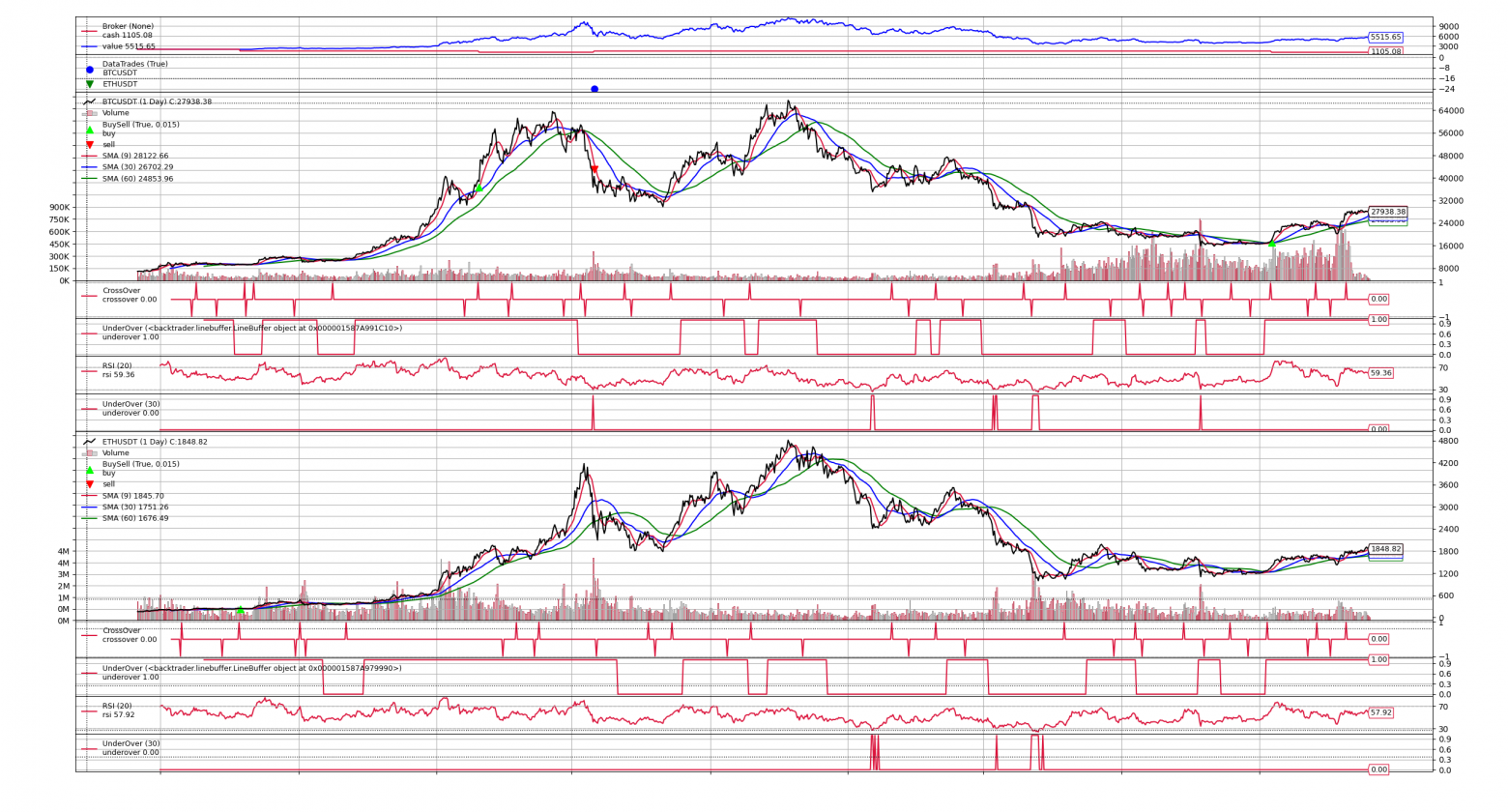
Программирование для меня это хобби и любимое дело. А так я сертифицированный системный архитектор. Поэтому прошу не особо ругать за код :-)
В настоящее время я увлекаюсь написанием торговых роботов. Постепенно изучаю нейросети для их применения к анализу цен/объемов акций/фьючерсов.
Обычно я писал торговых роботов для работы с Брокерами и делал авто-торговлю Акциями или Фьючерсами, но вдруг возникла мысль:
- А что, если уже готовый код можно применять и на других активах??? Например на крипто активах для Биткоина или Эфира или других?
Уже изучив много библиотек и примеров за долгое время написания своих торговых роботов, решил сделать небольшую библиотеку backtrader_binance для интеграции API Binance и библиотеки тестирования торговых стратегий Backtrader.
Вот с помощью backtrader_binance, сейчас и создадим алго-робота для торговли BTC и ETH.
Регрессионный анализ в DataScience. Часть 3. Аппроксимация
Средний
72 мин
Туториал
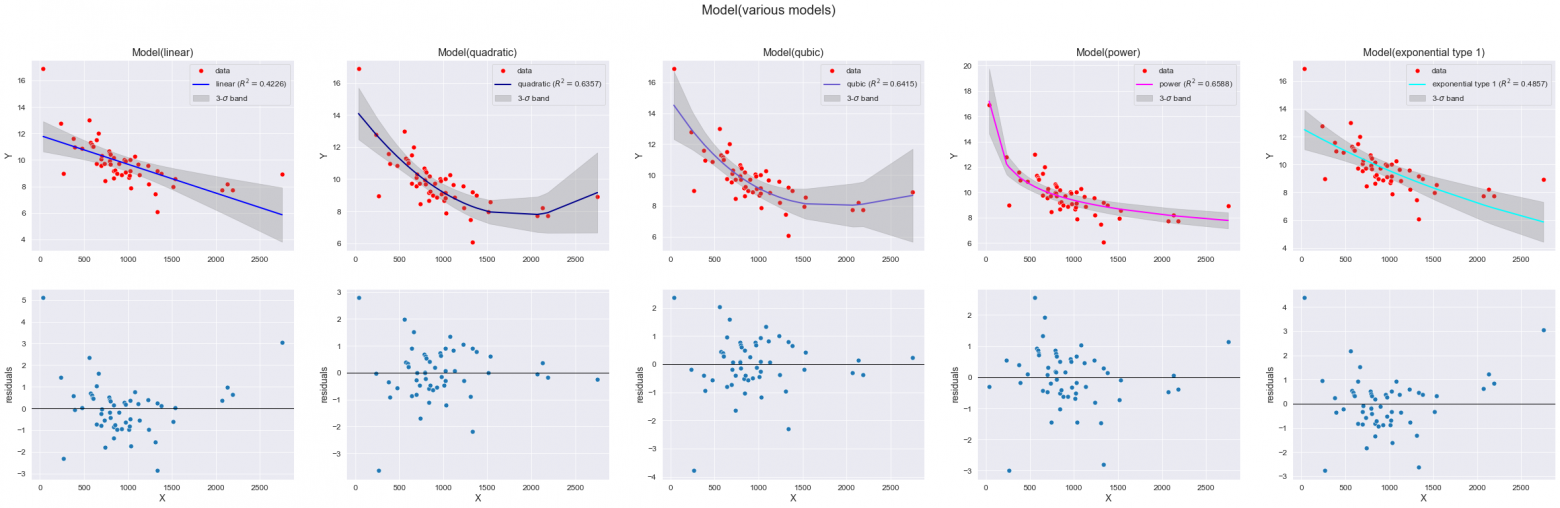
В предыдущих обзорах (https://habr.com/ru/articles/690414/, https://habr.com/ru/articles/695556/) мы рассматривали линейную регрессию. Пришло время переходить к нелинейным моделями. Однако, прежде чем рассматривать полноценный нелинейный регрессионный анализ, остановимся на аппроксимации зависимостей.
Про аппроксимацию написано так много, что, кажется, и добавить уже нечего. Однако, кое-что добавить попытаемся.
При выполнении анализа данных может возникнуть потребность оперативно построить аналитическую зависимость. Подчеркиваю - речь не идет о полноценном регрессионном анализе со всеми его этапами, проверкой гипотез и т.д., а только лишь о подборе уравнения и оценке ошибки аппроксимации. Например, мы хотим оценить характер зависимости между какими-либо показателями в датасете и принять решение о целесообразности более глубокого исследования. Подобный инструмент предоставляет нам тот же Excel - все мы помним, как добавить линию тренда на точечном графике:
BlackMamba или как ChatGPT пишет вредоносы
Простой
6 мин

Скорее всего не для кого уже не новость, что ChatGPT от OpenAI способен не только генерировать статьи, идеи, писать код вместо разработчика, но также писать всякого рода вирусы и прочие вредоносные программы. Специалисты кибербезопасности из компании Hyas решили продемонстрировать, на что способно вредоносное программное обеспечении на основе ChatGPT.
По итогу получился интеллектуальный вирус, способный сам принимать решения и генерировать концы своего исходного кода, который не обнаруживают антивирусные решения.
Я решил сам убедиться, возможно ли такое, и вот что вышло.
SQL-инъекции для самых маленьких. Часть 3
5 мин
Перевод
И это заключительная часть цикла статей про SQL-инъекции. В ней мы с вами узнаем, как можно собирать информацию о БД путем применения инъекций и затронем тему слепых SQL-инъекций.
Локальные нейросети (генерация картинок, локальный chatGPT). Запуск Stable Diffusion на AMD видеокартах
Простой
5 мин

Многие слышали про Midjourney, но про то, что есть локальная Stable Diffusion, которая может даже больше, знает уже куда меньше людей, или они не знают, что она локальная. И если они пробовали её онлайн, то быстро приходили к выводу, что она сильно хуже чем Midjourney и не стоит обращать на неё более внимания. И да, SD появился раньше Midjourney. Для запуска хватит и cpu или 4гб видеопамяти.
Аналогично с chatGPT, про попытку сделать его локальную версию, не требующую супер компьютер, тоже мало кто слышал и знает, несмотря на то, что выходило несколько статей.
Интеграция и кастомизация OpenAPI в Django/Django Rest Framework
Средний
7 мин

Рассмотрим способы интеграции OpenAPI схемы в экосистему Django/DRF с помощью библиотеки drf-spectacular, а также некоторые проблемы, возникающие при кастомизации API и, соответственно, их решения.
Оценка качества кластеризации: свойства, метрики, код на GitHub
11 мин
Кластеризация — это такая магическая штука: она превращает большой объём неструктурированных данных в потенциально обозримый набор кластеров, анализ которых позволяет делать выводы о содержании этих данных.
Приложений у методов кластеризации огромное количество. Например, мы кластеризуем поисковые запросы для того, чтобы повышать обобщающую способность алгоритмов ранжирования: любая статистика, вычисленная по группе похожих запросов, надёжнее той же статистики, вычисленной для одного отдельного запроса. Кластеризация позволяет повышать качество на запросах с редко встречающимися формулировками. Другой понятный пример — Яндекс.Новости, которые автоматически формируют сюжеты из новостных сообщений.
В далёком 2013 году мне повезло поучаствовать в разработке очень сложного алгоритма кластеризации. Требовалось с очень высоким качеством кластеризовать сотни тысяч объектов и делать это быстро: за десятки секунд на одной машине. Первым делом нужно было построить систему оценки качества, и в этой статье я расскажу именно о ней.

GPT-апокалипсис отменяется
Простой
4 мин
Мнение

Читая с утра новостную ленту – я обнаружил в ней очередное апокалипсическое предсказание. На этот раз от Элиезера Юдковского – известного рационального блогера, сооснователя Института Исследования Искусственного Интеллекта, более известного на Хабре как автор научно-популярного фанфика «Гарри Поттер и методы рационализма».
Наиболее вероятным результатом создания сверхчеловечески умного ИИ в условиях, отдаленно напоминающих нынешние, будет гибель буквально всех людей на Земле. Не в смысле «возможно, есть какая-то отдаленная вероятность», а в смысле «это очевидная вещь, которая произойдет». Дело не в том, что вы в принципе не можете выжить, создав что-то гораздо более умное, чем вы.
Чтобы визуализировать враждебный сверхчеловеческий ИИ, не надо представлять себе неживого умного мыслителя, обитающего в Интернете и рассылающего злонамеренные электронные письма. Представьте себе целую инопланетную цивилизацию, мыслящую в миллионы раз быстрее человека и изначально ограниченную компьютерами в мире существ, которые, с её точки зрения, очень глупы и очень медлительны.
Прочитанное заставило меня отложить на время написание своей статьи про взаимоотношения полов. Я уважаю Элиезера, но этот прогноз, по-моему, полная ерунда. По моему скромному мнению, клоны GPT не являются угрозой для человечества.