
Моя полная петиция на грин-карту по программе талантов EB-1A. 557 страниц, 7 критериев, одобрена с первой попытки без RFE. Все мои рассуждения по выбору критериев, подготовке и описанию доказательств, переводам, оформлению и отправке.

User
Моя полная петиция на грин-карту по программе талантов EB-1A. 557 страниц, 7 критериев, одобрена с первой попытки без RFE. Все мои рассуждения по выбору критериев, подготовке и описанию доказательств, переводам, оформлению и отправке.


О том, как сделать прозрачную синхронизацию заметок Obsidian между устройствами (Desktop, Android, iOS) через GitHub:
1. Без сторонних приложений (вроде iCloud, SyncThing, Termux и пр)
2. Бесплатно
3. Бонусом — резервная копия: как самих заметок, так и истории изменений.
В результате получается полноценная замена Notion: структурированные заметки с автоматической синхронизацией между устройствами.

ChatGPT вышел уже почти два года назад, а датасаентисты до сих пор никак не могут определиться — являются ли нейросети тварями дрожащими, или всё же мыслить умеют? В этой статье мы попробуем разобраться: а как вообще учёные пытаются подойти к этому вопросу, насколько вероятен здесь успех, и что всё это означает для всех нас как для человечества.


За время работы с объектными хранилищами я встречал немало «подводных рифов» на пути к быстрому и эффективному хранению.
В этой статье я покажу, где чаще всего проседает производительность при работе с S3-совместимым хранилищем, — на примерах из реальных кейсов технической поддержки.

Меня зовут Никита Шевченко и однажды я заигрался в красивый инструмент, да так, что в какой-то момент потерял суть и начал терять пользу. А потом начал придерживаться правил ведения заметок и даже придумал несколько своих.
В этой статье я собрал 5 личных ошибок, которые превращали мою личную базу знаний в кладбище заметок.
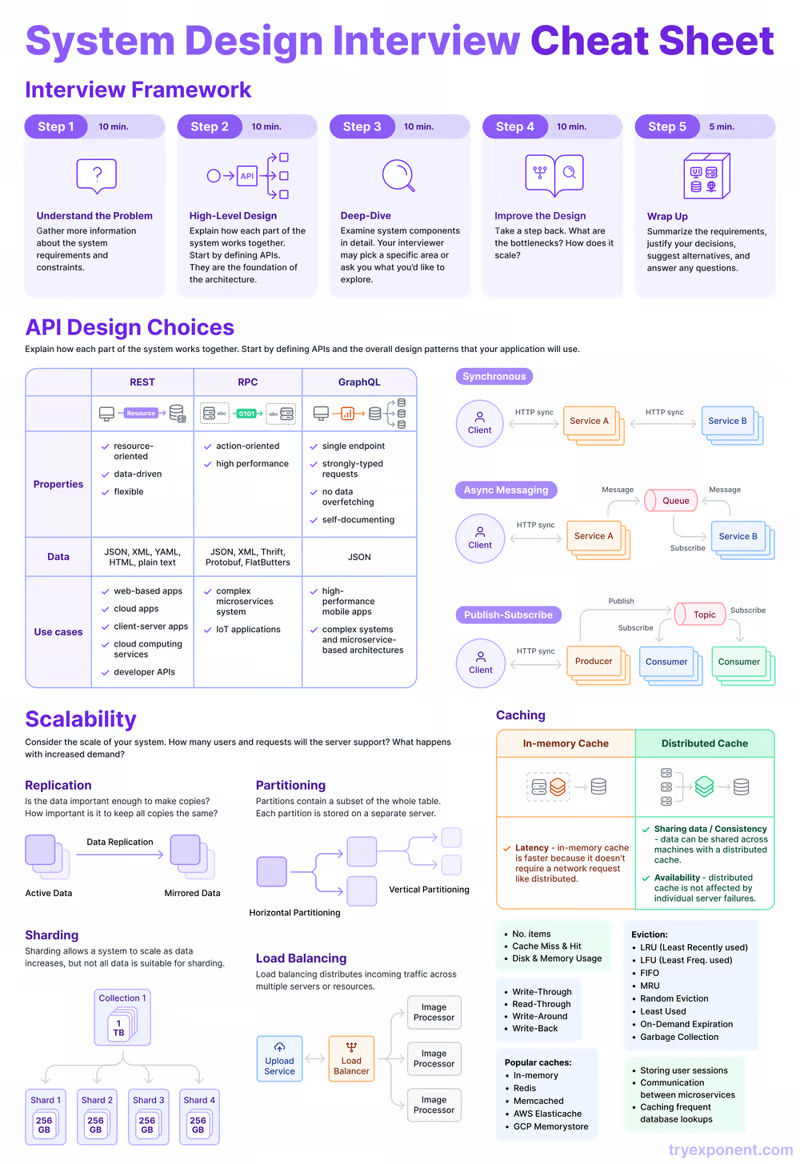
Для любого разработчика глубокое понимание основных принципов системного проектирования является необходимым условием для создания стабильных и масштабируемых программных систем, способных обеспечивать высокую производительность. Системное проектирование (System Design) включает разработку архитектуры и структуры программной системы, направленную на удовлетворение специфических требований и обеспечение требуемых показателей производительности.
С учетом стремительного прогресса в области технологий и возрастающей сложности программных приложений, овладение принципами системного проектирования становится критически важным для разработчиков, стремящихся создавать эффективные системы. Не имеет значения новичок вы или опытный специалист: освоение этих принципов позволит вам разрабатывать надежные и масштабируемые программные системы, отвечающие требованиям современных приложений.
Далее мы рассмотрим каждый из принципов более детально, чтобы понять их суть и способы применения в разработке приложений.

Я снимаю кинофестивали, шины от поставщика Формулы-1 и даже робота-хирурга прямо в операционной. Но снимал и из багажника, в студии-каморке, и начинал с подручных средств. Поэтому решил собрать 3 комплекта для съемок под разный бюджет: от бабушкиной пенсии до зарплаты айтишника.

Мы, разработчики ПО, пользуемся git каждый день, однако большинство из нас применяет только самые основные команды, например, add, commit, push и pull, как будто на дворе по-прежнему 2005 год.
С тех пор в Git появилось множество фич, пользование которыми может сильно упросить вашу жизнь. Так давайте исследуем некоторые из недавно добавленных современных команд git, о которых вам стоит знать.

Доброго времени суток. Основываясь на своём опыте хочу представить некоторые рекомендации при разработке кодовой базы на SQL.
Данные рекомендации получены горьким опытом, так что надеюсь, они Вам помогут :)

Если ты DevOps, который работает с adult‑проектами, то твой типичный «взрослый контент» будет выглядеть примерно так.
Одна из самых традиционных тем на Хабре — это внезапные карьерные перемещения из различных профессий в IT и обратно. У меня, вот, чудесный коллега — профессиональный мясник с соответствующим образованием. Мониторинг настраивает как боженька и умеет убедительно отстаивать свою точку зрения. Образование позволяет.
Меня тоже можете принимать в свои ряды людей со странной сменой профессии. Как многие помнят по моим старым постам — я изначально врач, который свернул в направлении фундаментальной науки и тканевой инженерии. Все вот эти развлечения со стволовыми клетками, выращиванием органов в биореакторах и прочими нетиповыми экспериментальными задачами. И вот тут меня внезапно позвали на собеседование в крупный телеком… Короче, очнулся я уже будучи DevOps в компании, которая занимается сложными проектами, некоторые из которых про adult‑видео. Ну вот те самые специальные обучающие фильмы для взрослых, которые двигатель прогресса. С петабайтами отданного трафика, набегами миллионов пользователей и прочими радостями.
Работает у нас это примерно так — у бизнеса наступает момент, когда приходит осознание, что все. Приехали. Инфраструктура работает, вроде бы все в порядке, но построена на костылях, которые заботливо укладывали три поколения сотрудников назад. Документации нет, как все это работает — никто не помнит. Если сервер сдохнет, воскресить в случае чего никто не сможет.
И вот где‑то в этот момент обычно появляемся мы с командой WiseOps и начинаем перебирать по винтику все археологические слои кода, архитектуры и бизнес‑логики. У нас уже есть несколько десятков клиентов и три из них про видеоконтент.
Предлагаю перейти под кат, а я попробую рассказать, как выглядит вся эта индустрия глазами врача/био‑инженера/DevOps.

Всем привет, я Алан, разработчик-исследователь в MTS AI. В команде фундаментальных исследований мы занимаемся исследованием LLM, реализацией DPO и валидацией наших собственных языковых моделей. В рамках этих задач у нас возникла потребность в генерации большого количества данных с помощью LLM. Такая генерация обычно занимает много времени. Однако за последний год, с ростом популярности LLM, стали появляться различные инструменты для развертывания таких моделей. Одной из самых эффективных библиотек для инференса языковых моделей является библиотека vLLM. В статье показывается, как с помощью асинхронных запросов и встроенных особенностей vLLM можно увеличить скорость генерации примерно в 20 раз. Приятного чтения!


В статье «Ускоряем анализ данных в 180 000 раз с помощью Rust» показано, как неоптимизированный код на Python, после переписывания и оптимизации на Rust, ускоряется в 180 000 раз. Автор отмечает: «есть множество способов сделать код на Python быстрее, но смысл этого поста не в том, чтобы сравнить высокооптимизированный Python с высокооптимизированным Rust. Смысл в том, чтобы сравнить "стандартный-Jupyter-notebook" Python с высокооптимизированным Rust».
Возникает вопрос: какого ускорения мы могли бы достичь, если бы остановились на Python?
Под катом разработчик Сидни Рэдклифф* проходит путь профилирования и итеративного ускорения кода на Python, чтобы выяснить это.
*Обращаем ваше внимание, что позиция автора может не всегда совпадать с мнением МойОфис.

Чем больше у backend‑разработчика знаний в своей области, тем лучшим специалистом он является. Но опыт показывает: самые классные программисты подобны Сократу, который не стеснялся заявлять во всеуслышание «scio me nihil scire», что в переводе на общенародный — «я знаю, что ничего не знаю». Сомневаясь во всём и вся, вы никогда не упустите из виду то, что многие считают «банальным» и «общеизвестным», а потому легко избежите проблем, которые возникают у слишком уверенных себе. Рассказываю о вопросах которые, могут упустить из виду даже самые крутые backend‑программисты, и даю советы по защитите себя от нежелательных трудностей до того, как они станут критичными.

В этой статье мы расскажем вам про самые важные фичи, внедренные за последние полгода в ChatGPT (самую мощную нейросетку в мире), а также обсудим – каким видением будущего поделился Сэм Альтман на прошедшей 7 ноября конференции от OpenAI. Спойлер: они хотят запилить «агентов Смитов», которые смогут самостоятельно взаимодействовать с миром!

Галлюцинации — это явление, которое до недавнего времени было привилегией человеческого сознания. Однако, с развитием текстовых генеративных моделей, таких как GigaChat и ChatGPT, возникла возможность наблюдать подобные "иллюзии" и в мире искусственного интеллекта.
Есть случаи, когда галлюцинации генеративной модели вполне уместны. Например, если вы попросите модель сгенерировать детскую сказку, то наличие в ней выдуманных персонажей и событий будет весьма кстати и понравится малышу.
Но мы точно не хотим получать выдуманную информацию про реальных людей или события. Кому интересно почитать о том, как мы боремся с галлюцинациями в GigaChat — добро пожаловать под кат.