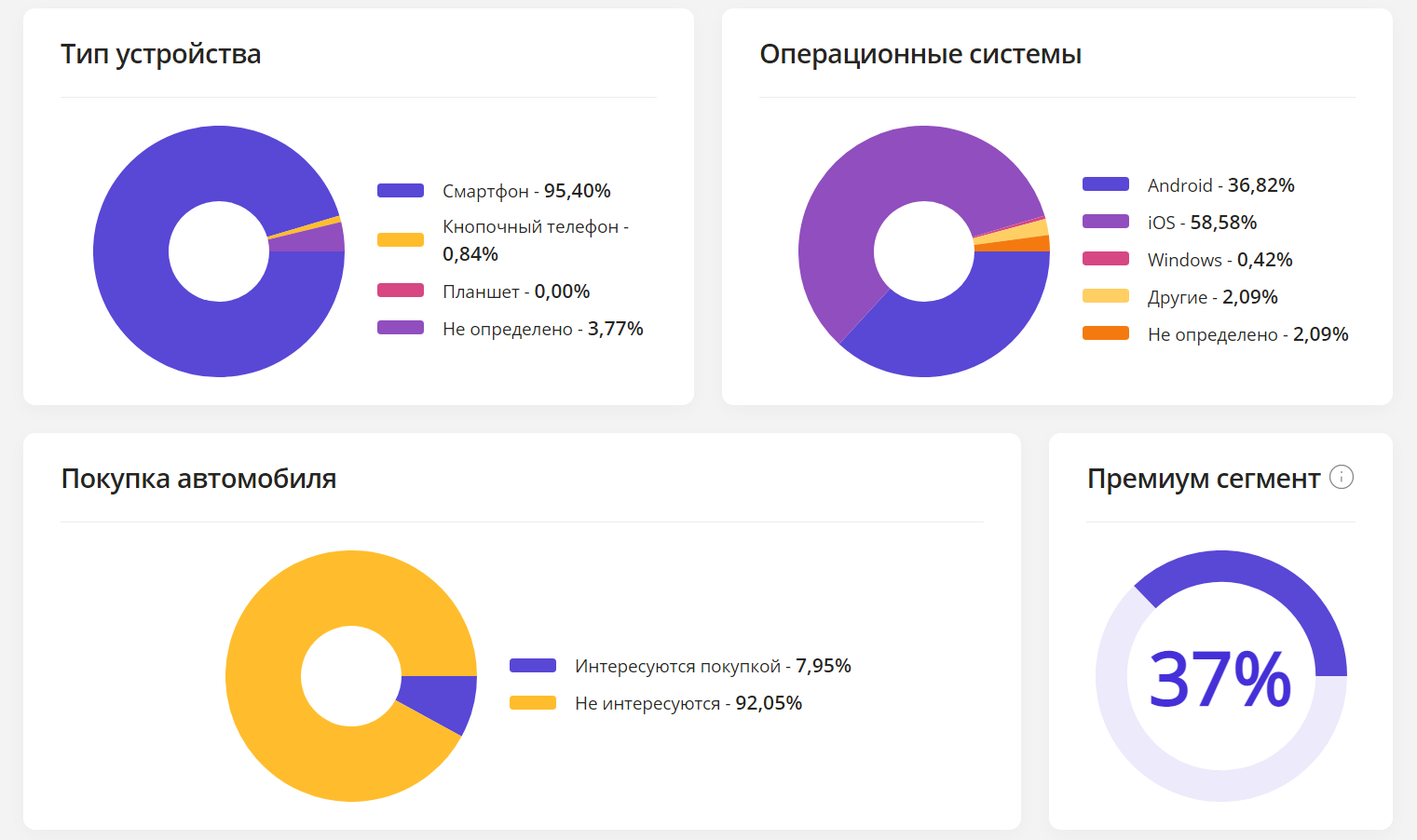
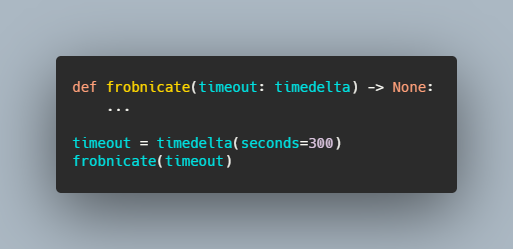
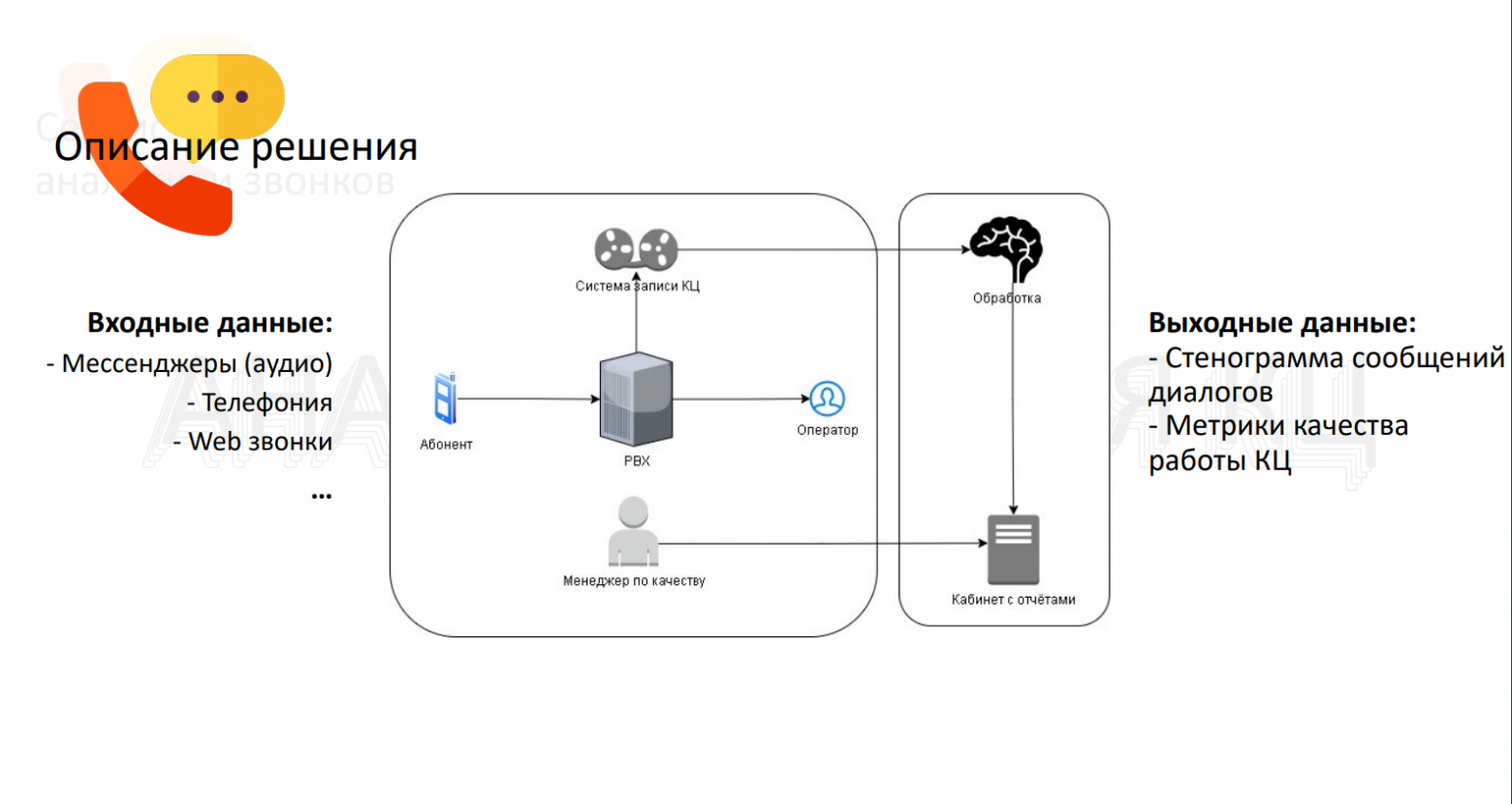
Десятилетнее сидение в офисе и перекладывание бумажек не сделают вас мастером программирования. На это способно только написание программ.
В свете недавних событий, связанных с производительностью терминала Windows [см. https://github.com/microsoft/terminal/issues/10362], я решил, что стоит немного порассуждать на эту тему, поскольку она раскрывает некоторые проблемы, мучающие отрасль разработки ПО.
Ситуация представляет собой стандартную мыльную интернет-оперу, запечатлённую на Github. Опытный программист опубликовал баг-репорт о медленном рендеринге текста в терминале и после долгого общения с мейнтейнерами один из них выдал следующее заявление:
— Я считаю то, что вы называете целый исследовательский проект на соискание докторской степени в эмуляции высокопроизводительного терминала «чрезвычайно простой» работой, выглядит довольно агрессивно...
Несколько часов спустя ещё один программист опубликовал прототип гораздо более быстрого рендерера терминала, доказав тем самым, что для опытного программиста рендерер терминала — это просто забавный проект на выходные, совсем не требующий многолетних долгих исследований. Как бы ни унизительно это было для Microsoft, которая, несмотря на владение платформой и API, по-прежнему испытывает трудности в создании ПО с удовлетворительной скоростью, мне кажется, что частично эта проблема вызвана корпоративной системой стимулов.
На основании моих ограниченных знаний, сложившихся из услышанных историй, я считаю, что отрасль разработки ПО не так сильно ценит совершенство навыков, как она ценит количество рабочей силы. Это, в свою очередь, ограничивает объём опыта, который может получать среднестатистический программист при работе с большими проектами, просто потому, что у него есть стимул как можно скорее уйти с должности создателя реализаций на какую-нибудь руководящую должность.
Тем не менее, крупные корпоративные проекты расширяются быстрее, чем наша Вселенная, и кому-то всё равно приходится программировать все новые фичи. Но кто же будет выполнять всю эту работу?