Недавно завершился «
Deep Learning in Natural Language Processing», открытый образовательный курс по обработке естественного языка. По традиции кураторы курса — сотрудники проекта
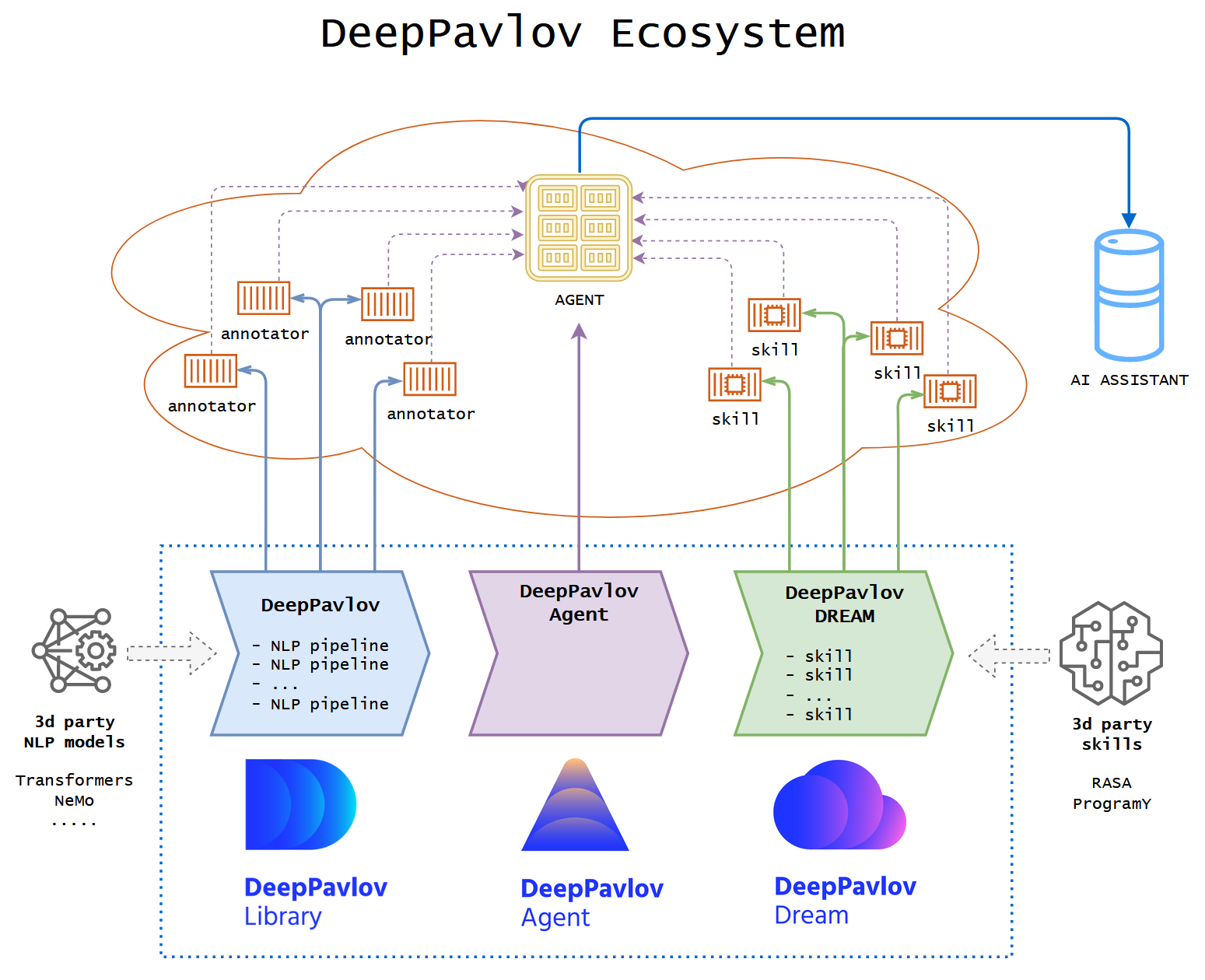
DeepPavlov, открытой библиотеки для разговорного искусственного интеллекта, которую разрабатывают в лаборатории нейронных систем и глубокого обучения МФТИ. Курс проводился при информационной поддержке сообщества
Open Data Science. Если нужно больше деталей по формату курса, то вам
сюда. Один из ключевых элементов «DL in NLP» — это возможность почувствовать себя исследователем и реализовать собственный проект.
Периодически мы рассказываем на
Medium о проектах, которые участники создают в рамках наших образовательных программ, например о том,
как построить разговорного оракула. Сегодня мы готовы поделиться итогами весеннего семестрового курса 2020 года.

Немного данных и аналитики
В этом году мы побили все рекорды по численности курса: в начале февраля записавшихся было около
800 человек. Скажем честно, мы не были готовы к такому количеству участников, поэтому многие моменты придумывали на ходу вместе с ними. Но об этом мы напишем в следующий раз.
Вернемся к участникам. Неужели все окончили курс? Ответ, конечно, очевиден. С каждым новым заданием желающих становилось все меньше и меньше. Как итог — то ли из-за карантина, то ли по другим причинам, но к середине курса осталась только половина. Ну что ж, а дальше пришлось определяться с проектами. В качестве итоговых участниками было заявлено семьдесят работ. А самый популярный проект — Tweet sentiment extraction — девятнадцать команд пытались выполнить задание на
Kaggle.
Подробнее про представленные проекты
На прошлой неделе мы провели заключительное занятие курса, где несколько команд представили свои проекты.
Если вы пропустили открытый семинар, то мы подготовили запись. А ниже мы постараемся кратко описать реализованные кейсы.












 Недавно завершился «
Недавно завершился «

