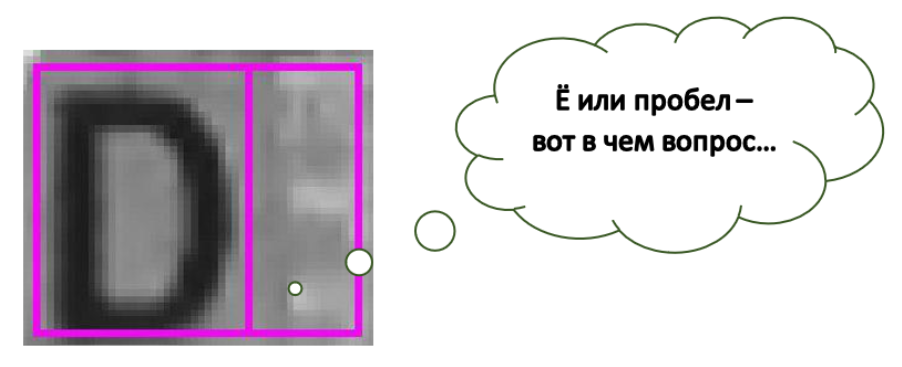
Как думаете, часто ли встречаются рукописные паспорта в нашей стране? Когда мы в
Smart Engines начинали проектировать систему распознавания паспортов, казалось, что достаточно научить систему качественно распознавать машинописные документы. На тот момент наличие рукописных паспортов, которые не поддавались автоматическому распознаванию, не представлялось важной проблемой: нерешенных задач хватало и без этого. Год назад, анализируя качество работы
Smart IDReader, мы поняли, что добрались до того уровня, когда рукописные паспорта составляют значимый класс ошибок. В соответствии с научным подходом, изучили проблему и принялись за решение. Сегодня будет рассказ о том, как мы сделали распознавание рукописного общегражданского паспорта РФ, успешно решив тем самым последнюю задачу на пути полной автоматизации ввода паспортных данных.









 Больше пяти лет мы публикуем на Хабре статьи на различные темы компьютерного зрения. Чаще всего они связаны с распознаванием документов, потому что нам всегда очень не терпится поделиться с вами всем крутым и новым, что мы сделали в
Больше пяти лет мы публикуем на Хабре статьи на различные темы компьютерного зрения. Чаще всего они связаны с распознаванием документов, потому что нам всегда очень не терпится поделиться с вами всем крутым и новым, что мы сделали в