В этом цикле статей речь пойдет о параллельном программировании. Довольно часто самые сложные алгоритмы требуют огромного количества вычислительных ресурсов в реальных задачах, когда программист пишет код в стандартном его понимании процедурного или Объектно Ориентированного Программирования(ООП), то для особо требовательных алгоритмических задач, которые работают с большим количеством данных и требуют минимизировать время выполнения задачи, необходимо производить оптимизацию.
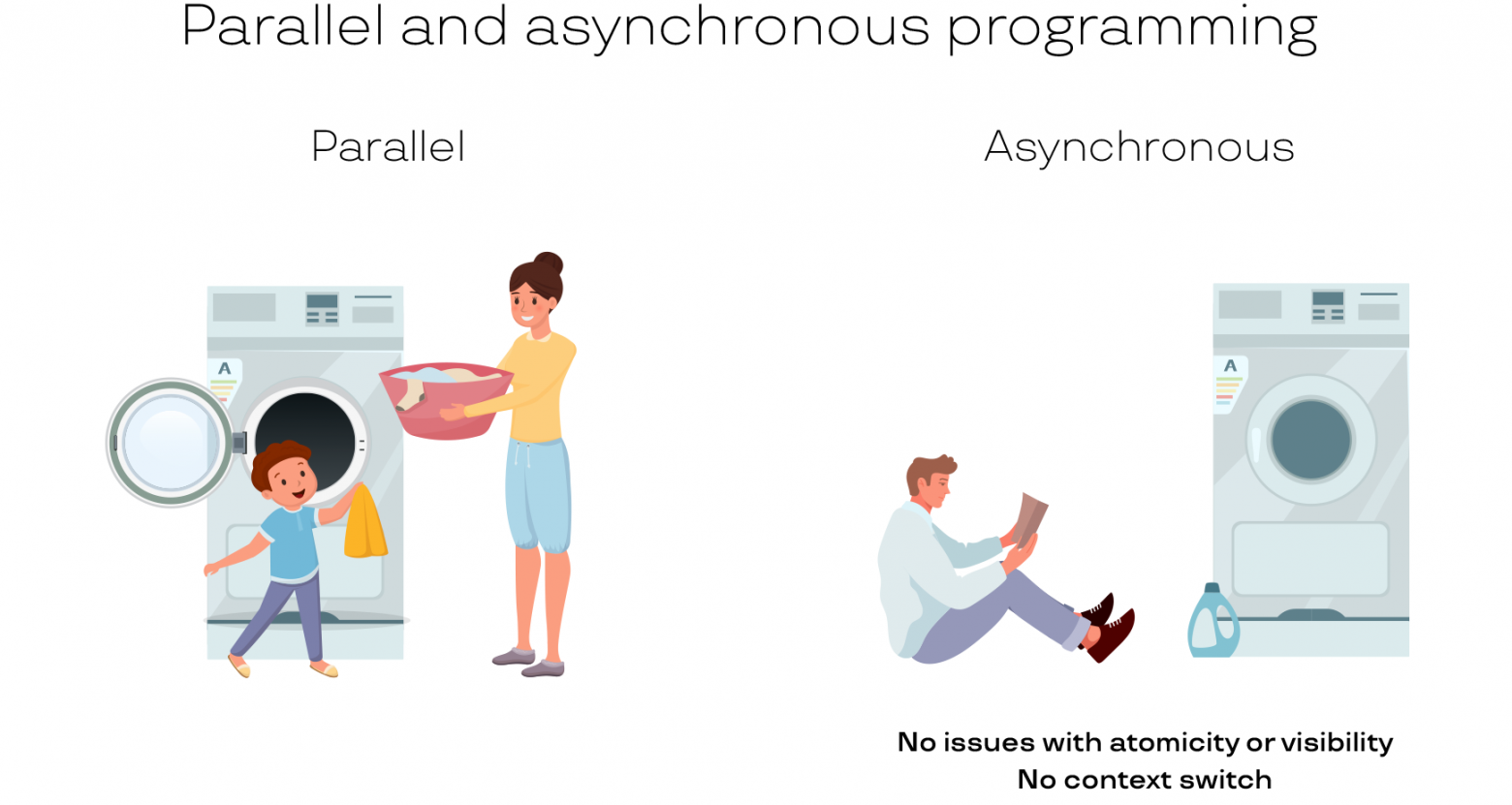
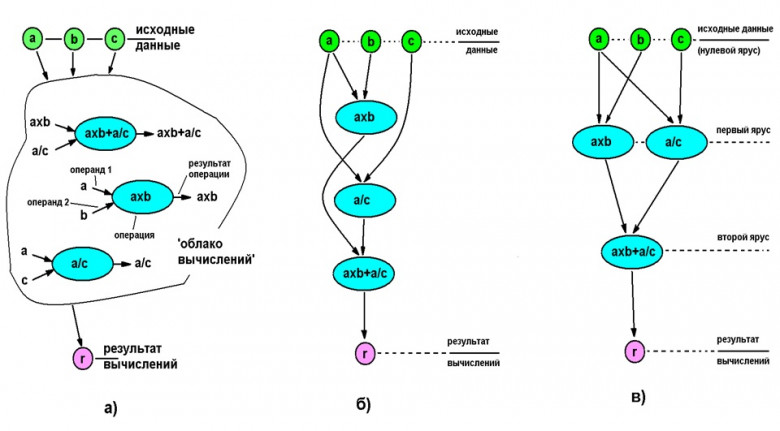
В основном используют 2 типа оптимизации, либо их смесь: Векторизация и распараллеливание вычислений. Чем же они отличаются?
Вычисления производятся на процессоре, процессор пользуется специальными "хранилищами" данных называемыми регистрами. Регистры процессора напрямую подключены к логическим элементам и требуют гораздо меньшее время для выполнения операций над данными, чем данные из оперативной памяти, а тем более на жестком диске, так как для последних довольно большую часть времени занимает пересылка данных. Так же в процессорах существует область памяти называемая Кэшем, в нем хранятся те значения, которые в данный момент участвуют в вычислениях или будут участвовать в них в ближайшее время, то есть самые важные данные.
Задача оптимизации алгоритма сводится к тому, чтобы правильно выстроить последовательность операций и оптимально разместить данные в Кэше, минимизировав количество возможных пересылок данных из памяти.
Далее вы узнаете, что такое параллелизация и как пользоваться MPI на практике.