Интернет вещей (IoT) — новая реальность, которая уже не кажется социальным и технологическим чудом. Но умные лампочки и роботы-пылесосы уже мало кого удивляют. Настоящие возможности IoT раскрываются в сфере анализа больших данных или при использовании алгоритмов искусственного интеллекта.
По данным IDC, собственные стратегии цифровизации уже выстроили 2/3 компаний из списка Global 2000, а безусловными лидерами в этой области являются Сингапур, Китай, Новая Зеландия, Дания и Южная Корея. Что касается РФ, по оценке IDC, более 50% российских компаний освоят IoT-технологии до конца 2021 года.
Одним из драйверов роста затрат на IoT (которые вырастут на 11,3% в 2021-2024 годах, согласно прогнозу IDC) будет рост потребностей:
- в подключенных к интернету устройствах для дистанционного контроля и управления;
- в сценариях использования искусственного интеллекта для мониторинга поведения людей.
Развитие IoT стимулирует развитие концепции Digital First, в рамках которой каждый бизнес должен быть максимально развит в интернет-среде. Это значительно расширяет возможности взаимодействия между сторонами различных процессов, позволяя осуществлять автоматизацию доставки покупок, онлайн-обучение и даже трудоустройство в удаленном формате.





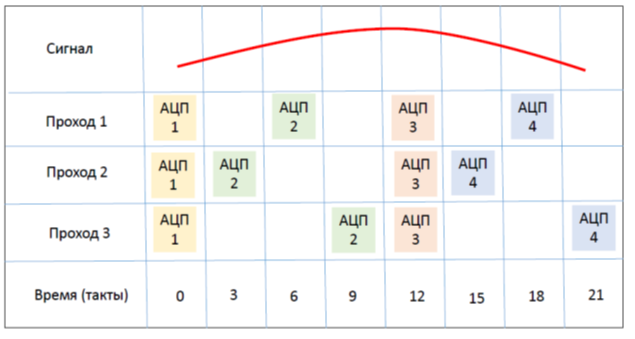













{kind=link}
{kind=link}