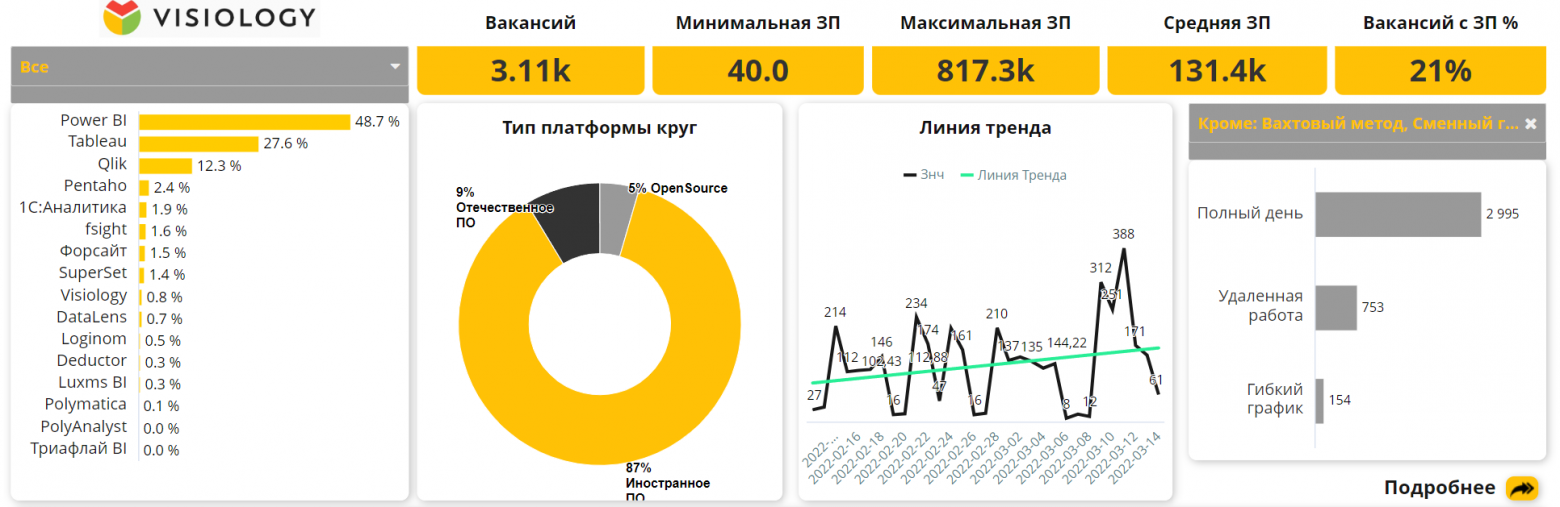
Осенью 2021 года я задумался о бесплатных инструментах аналитики и построения отчетности, доступных простым пользователям. В том или ином виде можно использовать Power BI или Tableau, но почему бы не попробовать что-то более простое?
Небольшой дисклеймер: датасет, о котором далее пойдет речь, был загружен осенью 2021 года. Сейчас датасет другой, возможно более чистый. Загружать новые данные счел нерациональным, поскольку серия постов будет про простейшие визуализации, а не про актуальные исследования или сложные диаграммы. И нет, это не подробная методичка по возможностям GDS, это только общий обзор решения и разбор одного кейса.
Нас интересует только сторона работы обычного аналитика, насколько это возможно (и насколько я себе это представляю), поэтому я буду стараться искать самые простые пути решения проблемы. Понимаю, что некоторые методы вроде использования промежуточной базы данных не выглядят простыми для кого-то, но с тем же успехом можно использовать таблицы от Google. У меня БД просто была под рукой, да и выстроить полноценный ETL-процесс без неё не выйдет.