
Продолжает расти популярность решений на основе PKI — всё больше сайтов переходят на HTTPS, предприятия внедряют цифровые сертификаты для аутентификации пользователей и компьютеров, S/MIME доказывает свою состоятельность и для шифрования электронной почты, и как способ проверки источника сообщений для противодействия фишингу. Но шифрование и аутентификация в этих приложениях практически бессмысленны без правильного управления ключами.
Каждый раз при выдаче цифрового сертификата от центра сертификации (ЦС) или самоподписанного сертификата нужно сгенерировать
пару из закрытого и открытого ключей. Согласно лучшим практикам, ваши секретные ключи должны быть защищены и быть, ну… секретными! Если кто-то их получит, то сможет, в зависимости от типа сертификата, создавать фишинговые сайты с сертификатом вашей организации в адресной строке, аутентифицироваться в корпоративных сетях, выдавая себя за вас, подписывать приложения или документы от вашего лица или читать ваши зашифрованные электронные письма.
Во многих случаях секретные ключи — личные удостоверения ваших сотрудников (и, следовательно, часть персональных данных организации), так что их защита приравнивается к защите отпечатков пальцев при использовании биометрических учётных данных. Вы же не позволите хакеру добыть отпечаток своего пальца? То же самое и с секретными ключами.
В этой статье мы обсудим варианты защиты и хранения закрытых ключей. Как вы увидите, эти варианты могут незначительно отличаться в зависимости от типа сертификата(ов) и от того, как вы его используете (например, рекомендации для сертификатов SSL/TLS отличаются от рекомендаций для сертификатов конечных пользователей).

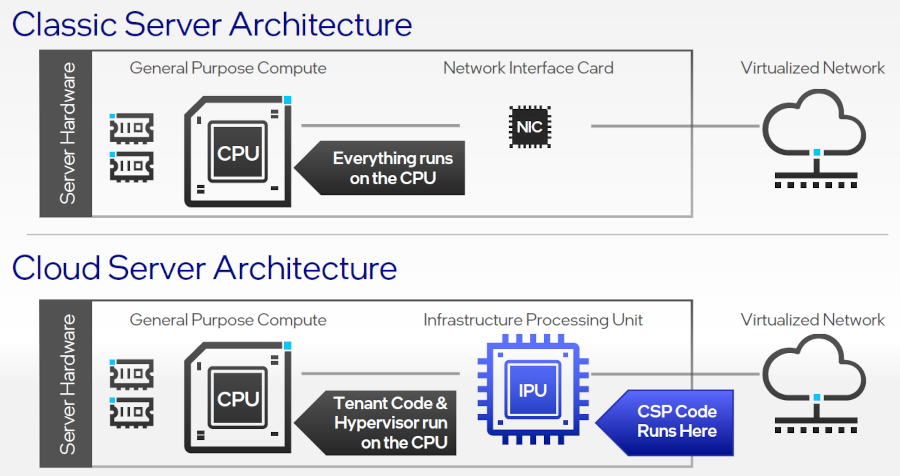
















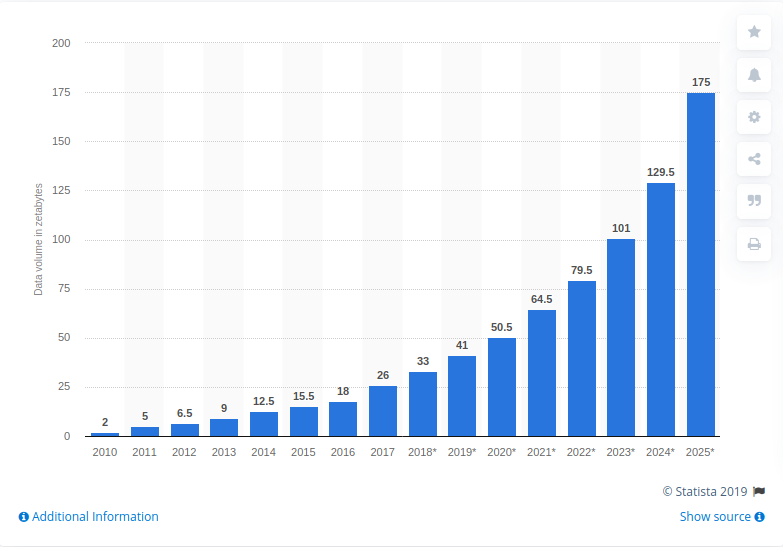{kind=link}