Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель "убить" CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — "понять", так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой "лисп"/"питон"/"ваш абсолютно новый синтаксис" на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github'е. Тегами обозначены начало и концы статей для удобства.




 PVS-Studio — статический анализатор исходного кода для поиска ошибок и уязвимостей в программах на языке C, C++ и C#. В этой статье я хочу дать обзор технологий, которые мы используем в анализаторе PVS-Studio для выявления ошибок в коде программ. Помимо общей теоретической информации я буду на практических примерах показывать, как та или иная технология позволяет выявлять ошибки.
PVS-Studio — статический анализатор исходного кода для поиска ошибок и уязвимостей в программах на языке C, C++ и C#. В этой статье я хочу дать обзор технологий, которые мы используем в анализаторе PVS-Studio для выявления ошибок в коде программ. Помимо общей теоретической информации я буду на практических примерах показывать, как та или иная технология позволяет выявлять ошибки. Привет, Хабр! Меня зовут Марко Кевац, я системный программист Badoo в команде «
Привет, Хабр! Меня зовут Марко Кевац, я системный программист Badoo в команде «

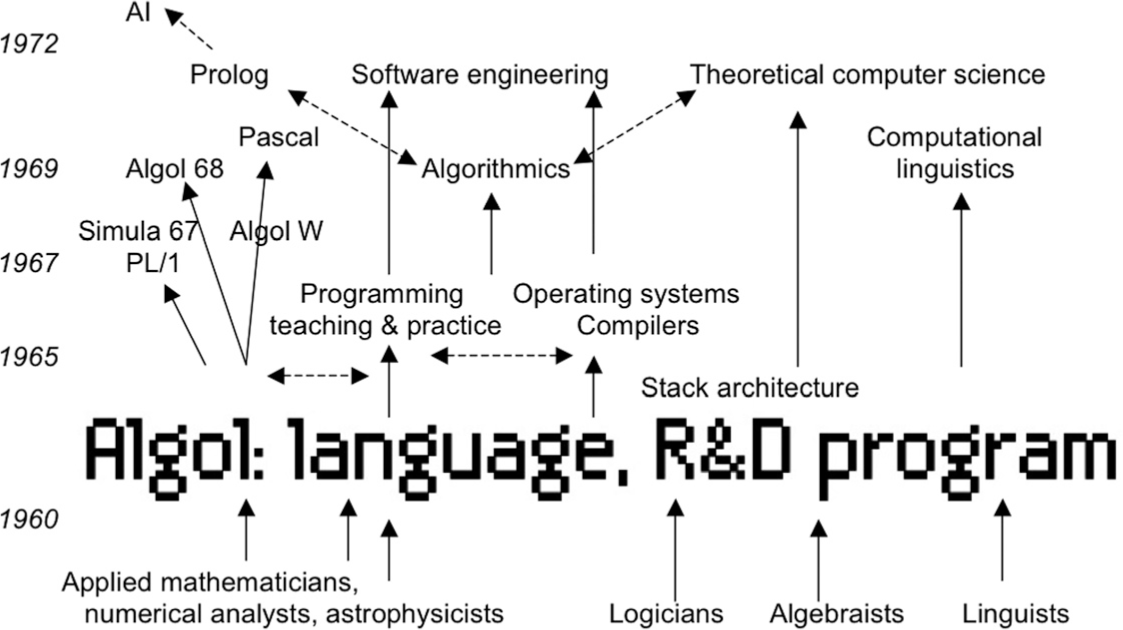

 В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы
В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы 

