Сжатие данных управляет Интернетом. Вот как это работает
5 мин
Перевод
Желание одного студента не сдавать выпускной экзамен привело к появлению вездесущего алгоритма, который сжимает данные, не жертвуя при этом информацией.
Желание одного студента не сдавать выпускной экзамен привело к появлению вездесущего алгоритма, который сжимает данные, не жертвуя при этом информацией.

Автор статьи: Артем Михайлов


Меня давно заинтриговала тема дедупликации данных. Это произошло в далеком 2016 году, когда передо мной встала задача впихнуть не впихуемое, на продакшн-серверах. Но обнаружить доступное решение оказалось невероятно сложно (на тот момент невозможно). Со временем у меня возникли и личные задачи, когда я хотел уменьшить объем третьей или четвертой копии данных, чтобы сэкономить место на диске. Но, возможно, я просто одержим датахордингом, и это тоже не исключено.
CassandraDB – она же просто Кассандра – хорошо зарекомендовала себя в нише высокопроизводительных NoSQL баз данных. Но, вот, её активно стала вытеснять ещё более быстрая, надежная и легко масштабируемая ScyllaDB - этакая Кассандра++. Как тут удержаться и не проверить, так ли прекрасна эта зверушка, как про неё говорят её создатели? Тем более вендоры других популярных баз данных того и гляди закроют поддержку для российских пользователей. Нужно иметь под рукой пару-тройку запасных вариантов. Сегодня мы рассмотрим, как одноглазый монстрик приживается в диких условиях кровавого энтерпрайза, и насколько целесообразно его использовать.
Об этом расскажет Илья Орлов, техлид компании STM Labs. Вместе с командой он разрабатывает высоконагруженные решения для всевозможных задач: бизнес-порталов с использованием собственной платформы, мониторинга фискальных данных и прочее. Они любят экспериментировать с разными БД, поэтому статья будет об использовании ScyllaDB на промышленных мощностях.


Добрый день! Меня зовут Дмитрий Грязнов, я студент УрФу и начинающий разработчик.
Вместе с товарищами мы подумали, что всем студентам и школьникам, которые ищут в интернете информацию, был бы полезен сервис, который может делать смысловую выжимку из текста любого объёма. Мы решили разработать именно такое приложение и выступить с этой идеей на конкурсе «Большие вызовы для студентов». Собрали ансамбль моделей, изучили, много чего переработали.
Коротко: мы используем пайплайн из сжимающих T5, Pegasus, экстракции TextRank, парафразер Bart. Сначала один алгоритм определяет вес каждого предложения и передаёт на вход абстрактивной модели 20% самых значимых предложений. А затем второй перефразирует полученный текст, чтобы сделать его более связанным. Очень много интеграционного кода и тюнинга, чтобы это всё заработало нормально. Сейчас расскажу, как дело было.


rsync, которые вроде бы работают идеально. Но нет, всегда можно придумать что-то получше.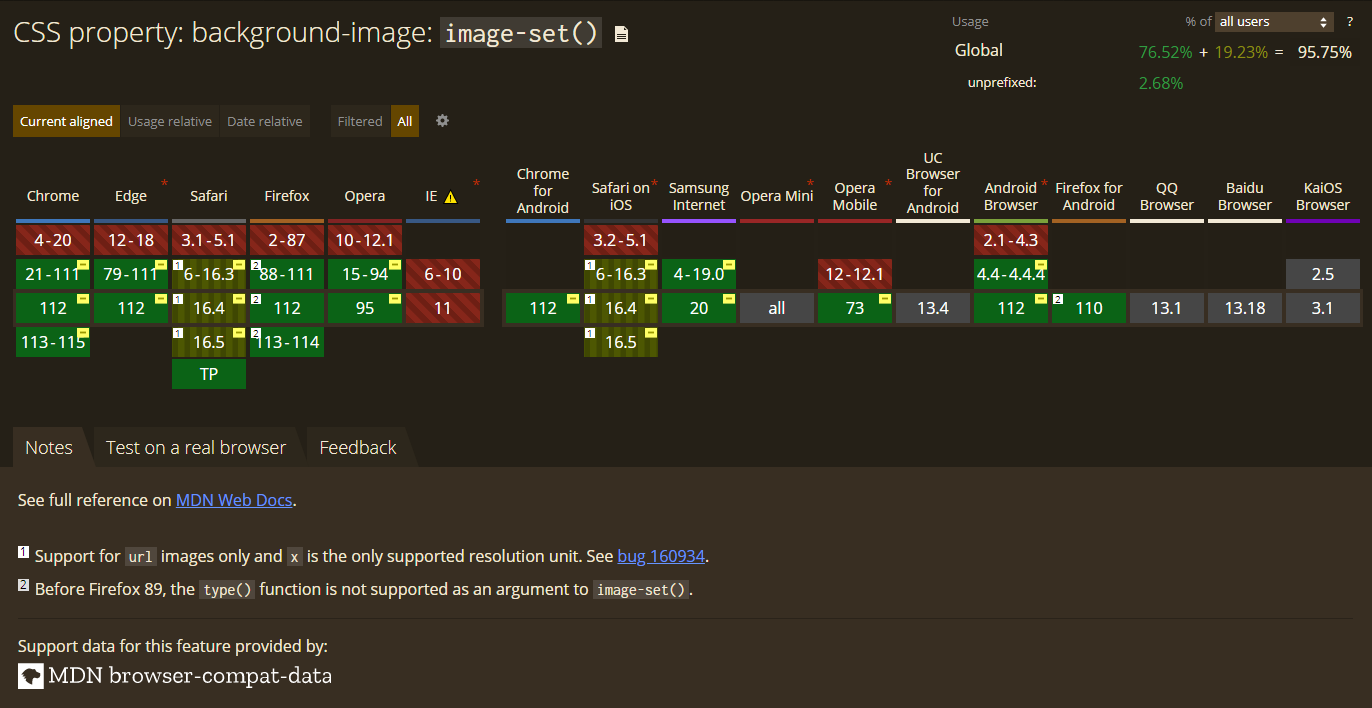
Как вы знаете, формат изображений WebP в большинстве случаев имеет меньший вес, по сравнению со своими братьями: png и jpeg. Поэтому использовать его в своих приложениях - это хорошая практика.

Каждый из нас сталкивался с необходимостью настройки сложного ПО, интенсивно потребляющего ресурсы компьютера. Как правило, у такого софта довольно объёмная конфигурация, и из-за этого бывает трудно подобрать комбинацию параметров, при которой этот софт демонстрировал бы высокую производительность при минимальной утилизации железа.
Одна из наиболее ресурсоемких категорий софта сегодня — это системы хранения данных. К ним можно отнести как классические СУБД, так и хранилища различного назначения. В корпоративной почтовой системе Mailion мы используем объектное хранилище собственной разработки — Dispersed Object Store (DOS). Mailion поддерживает одновременную работу до миллиона пользователей, и подобный уровень нагрузки выдвигает существенные требования к производительности и экономической эффективности системы.
Под катом рассказываем, как мы искали оптимальную конфигурацию нашего объектного хранилища, и какие уроки извлекли из этого поиска.
 Пару дней назад на Хабре обсуждали, что сжатие информации — главная концепция нашей жизни. И вот перед нами представитель этой самой индустрии. Человек, который видит мир через призму теории информации, энтропии, хаоса и закономерностей.
Пару дней назад на Хабре обсуждали, что сжатие информации — главная концепция нашей жизни. И вот перед нами представитель этой самой индустрии. Человек, который видит мир через призму теории информации, энтропии, хаоса и закономерностей.

 ]
]
Одна из самых приятных вещей в жизни разработчика архитектуры ПО и технологического эксперта Intel — возможность наблюдать за фантастическими достижениями Центров передового опыта (CoE) OneAPI по всему миру. Недавно лаборатория UC Davis Visualization & Interface Design Innovation (VIDI) Lab поделилась опытом применения глубокого обучения в создании интерактивной визуализации для науки. Подробности — к старту флагмансокго курса по Data Science.

Сейчас модно писать, что ML пришел туда и все стало отлично, DL пришел сюда и все стало замечательно. А к кому-то пришел сам AI, и там все стало просто сказочно! Возможна ли ситуация, когда к нам пришел волшебный ML/DL и все стало сложнее, тяжелее и на порядок запутаннее? Безусловно! Разберем такой пример.
Десятки лет при сравнении кодеков и алгоритмов обработки видео исследователи использовали старые добрые метрики PSNR и SSIM с довольно простыми формулами и были счастливы. Но прогресс невозможно остановить! На их место пришли новые метрики и… тут выяснилось, что они взламываются.
— Погодите, погодите… — скажет взволнованный читатель, — А как это вообще выглядит, взломать метрику???
— Добро пожаловать в 21 век, дорогой товарищ! Благодаря неудержимому прогрессу, сегодня можно хакнуть не только утюг, колонку, автопилот машины и домашний пылесос, но и метрику качества видео.
В этот момент собеседники обычно дружно спрашивают, кому это надо? О, поверьте, есть люди, которым не просто надо, а сильно надо! Представьте себе, что вы руководитель подразделения и у вас жесткие KPI (маркетинг требует обогнать конкурентов, от этого зависят нехилые годовые бонусы у всех сотрудников и особенно у вас). Чтобы улучшить видеокодек на условные 4%, требуются десятки человеко-месяцев труда весьма высокооплачиваемых инженеров, причем, бывает, получается, а бывает, не очень. И тут выясняется, что можно за пару недель работы одного зеленого стажера подшаманить метрику на 7%. Ваши действия? Вспоминается жизненный анекдот «тут-то мне карта и поперла»…
Далее мы популярно затронем взлом методом черного ящика, белого ящика, взлом недифференцируемых метрик (привет дистилляция!) и цирк с дифференцируемыми.
Впрочем обо всем по порядку…
Кому интересен цирк с конями взлом метрик — го под кат.
Аргументы в защиту формата в лонгриде под катом — к старту курса по Fullstack-разработке на Python.

Разработчики Chrome недавно анонсировали своё решение о прекращении поддержки формата JPEG XL, который ранее был «убран за флажок». Это решение объясняется так:

Привет, Хабр! Сегодня я предлагаю поговорить о скорости восстановления из резервной копии. Иногда именно этот параметр оказывается критически недооцененным при внедрении систем резервного копирования для небольших отделов и не самых критичных задач (ведь для критичных RTO и RPO прописывают еще на этапе проектирования). В этом посте мы остановимся на 10 способах сократить время, которое ваши системы будут простаивать, если вдруг не дай бог чего случится. А если вы знаете еще и другие методы, делитесь ими в комментариях.
{kind=link}