Yandex Data Proc для ML: ускоряем Embedding на Spark
Сложный
9 мин
Туториал

Меня зовут Дмитрий Курганский, я Tech Lead команды MLOps в Банки.ру.
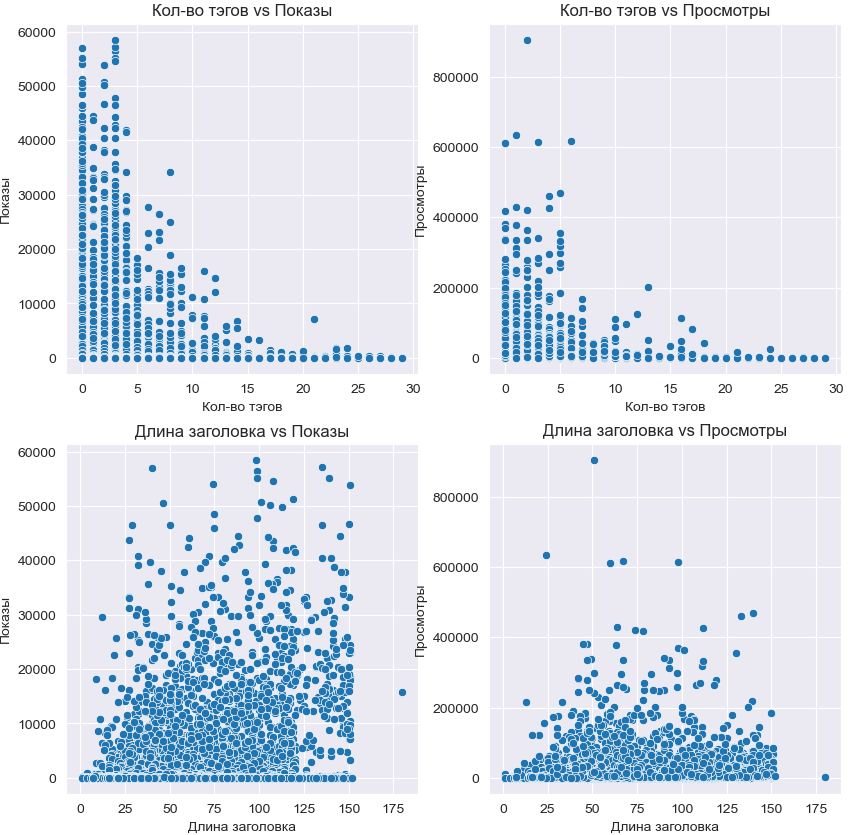
Мы работаем над тем, чтобы грамотно организовать и ускорить этапы жизненного цикла ML. В этой статье поделюсь нашим опытом применения Embedding: от запуска Яндекс Data Proc кластера через Airflow до оптимизации этапа применения Embedding с помощью Spark.
Материал в целом будет актуален для этапа применения (inference) любых моделей для больших наборов данных, работающих в batch режиме по расписанию.