
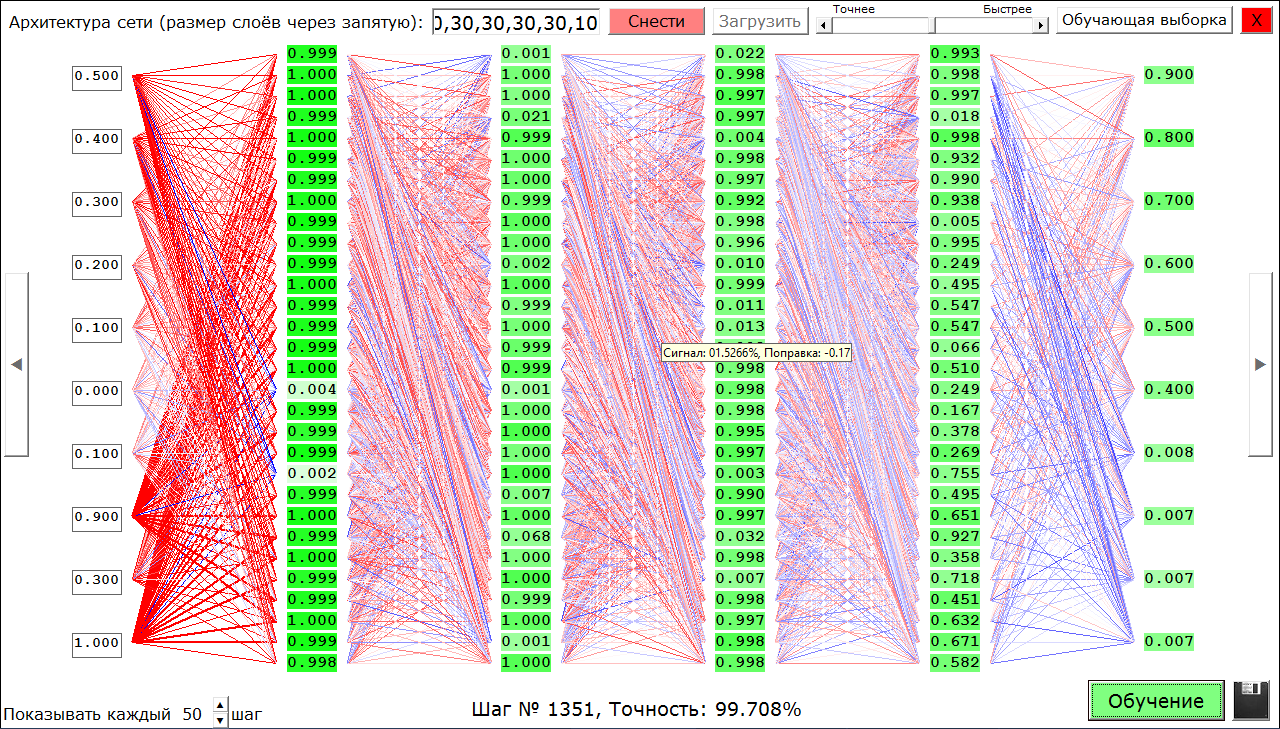
«Cделать красиво». Визуализация обучения с Tensorboard от Google
5 мин
Туториал

Красота, как известно, требует жертв, но и мир обещает спасти. Достаточно свежий (2015г) визуализатор от Google призван помочь разобраться с процессами, происходящими в сетях глубокого обучения. Звучит заманчиво.
Красочный интерфейс и громкие обещания затянули на разбор этого дизайнерского шайтана, с неинтуитивно отлаживающимися глюками. API непривычно скудный и часто обновляющийся, примеры в сети однотипны (глаза уже не могут смотреть на заезженный MNIST).
Чтобы опыт не прошел зря, решила поделиться максимально простым описанием инсайтов с хабравчанами, ибо рускоязычных гайдов мало, а англоязычные все как на одно лицо. Может, такое введение поможет вам сократить время на знакомство с Tensorboard и количество ругательных слов на старте. Также буду рада узнать, какие результаты он дал в вашем проекте и помог ли в реальной задаче.










 Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат.
Если отвлечься от съемки с помощью беспилотных летательных аппаратов (БПЛА) свадеб, торжеств и юбилеев, то становится очевидным, что в арсенале специалистов по картографированию территорий, экологов и военных появился мощный инструмент в работе — промышленные беспилотные аппараты, которые способны решать различные задачи по построению качественной картографической информации, подробных ортофотопланов территорий, лесов, сельскохозяйственных угодий и городских территорий. Учитывая тот факт, что получить качественный фотографический материал для построения 3D моделей местности только с первого взгляда кажется простым делом, в действительности — задача имеет массу всяческих особенностей. Захотелось поделиться собственным опытом организации промышленной аэрофотосъемки, местом расположения граблей, на которые пришлось наступить, а вернее — на которые пришлось налететь. За всеми подробностями прошу под кат. 
 Я думаю многие задавались вопросом как отключить триггеры в zabbix на время прогнозируемой нагрузки, например на момент выполнения бэкапов. И я думаю многие легко решили этот вопрос, ну а те, кто ещё не придумал как это реализовать, добро пожаловать под кат!
Я думаю многие задавались вопросом как отключить триггеры в zabbix на время прогнозируемой нагрузки, например на момент выполнения бэкапов. И я думаю многие легко решили этот вопрос, ну а те, кто ещё не придумал как это реализовать, добро пожаловать под кат!