
Что нового в Midjourney 6? 5 видимых отличий от 5.2
Простой
3 мин
Обзор
Recovery Mode
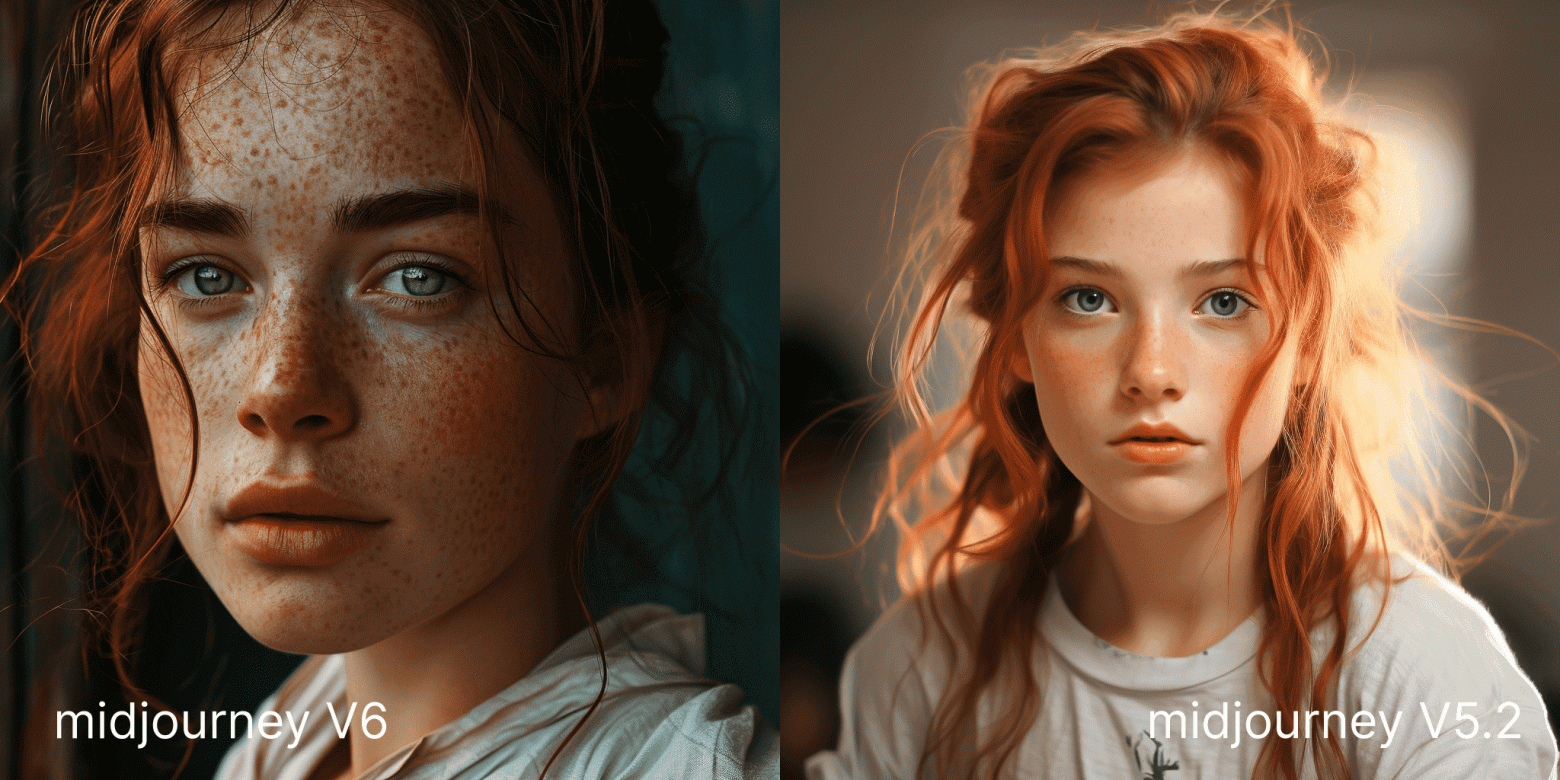
Теперь изображения сложно отличить от реальных фото - морщины, складки, красные глаза, текстура кожи — генерации выглядят почти идеально.
Теперь изображения сложно отличить от реальных фото - морщины, складки, красные глаза, текстура кожи — генерации выглядят почти идеально.

Когда впервые на ПК стали работать с фотографиями? Какие из этих систем вошли в историю, а какие остались практически неизвестными? Следующий обзор - это попытка ответа на эти и сопутствующие вопросы с техническими деталями. Конечно, это про Амигу, но не только.

Привет, Хабр. На пороге Новый год. Как всегда в конце года хочется понять, а чем же был для нас, компании Smart Engines, год уходящий? Продуктивным - да, и бизнес-результаты, и научные достижения, и технологии - как игрушки на елке - радуют. А где же игрушки - спросите вы и будете правы. Ведь один их сверкающий вид открывает двери празднику. А ниже они обязательно будут. Сегодня мы поделимся с вами нашим взглядом на 12 месяцев, а поможет в этом наш STE. Тот самый продукт для томографической реконструкции, над которым мы не устаем трудиться, дополняя, стабилизируя и запуская, как проходческий щит, в неосвоенные туннели условий томографической съемки.
Результат наших трудов покажем на томографии 12 объектов, каждый из которых символизирует один из 12 месяцев года. Да-да, интересная задача перед нами стояла в декабре - собрать 12 объектов, сфотографировать, сделать томографию и соорудить календарь из них. Кстати, и ты, дорогой читатель, можешь стать обладателем календаря от Smart Engines, но обо всем по порядку!

Изучая графику на Dribbble или Behance, вы найдёте там дизайнеров, использующих простую технику добавления в изображения текстур: шум. Добавление шума делает сплошные цвета или плавные градиенты, например, тени, более реалистичными. Но несмотря на любовь дизайнеров к текстурам, шум редко применяется в веб-дизайне.
В этой статье мы при помощи CSS и SVG сгенерируем цветной шум, позволяющий добавлять текстуру к градиенту.

Привет, Хабр!
Сегодня с вами участники профессионального сообщества NTA Промкин Михаил, Мымрин Дмитрий и Господарикова Ирина.
Одной из областей применения ИИ сегодня является автоматизация контроля за сотрудниками. В данном посте мы рассмотрим приложение технологий ML к задаче детектирования спящих людей (в частности, охранников на рабочем месте) по видеозаписям камер наблюдения.
Обсудим технические аспекты этого процесса, а также потенциальные преимущества и перспективы, которые предоставляет применение искусственного интеллекта в обеспечении безопасности на рабочем месте.

Прошло 3 года с момента когда я обучал StyleGAN на панельках и мне стало интересно что там сейчас с генерацией картинок. А там - ого - можно дообучить целый stable diffusion на любом стиле любого художника! Как? А вот щас расскажу

В 2023 году первой российской коммерческой технологии распознавания текста исполнилось ровно 30 лет. В честь этой знаковой даты мы решили подготовить серию материалов о том, когда появились и что из себя представляли первые отечественные OCR. Кто был главными участниками в гонке по созданию систем распознаванию? Как так вышло, что в середине 90-х OCR была признана второй по значимости софтовой разработкой после ОС? Как выглядела первая OCR-ка для Mac? Ответим на эти и многие другие вопросы, присаживайтесь поудобнее.
Во время подготовки текстов мы побеседовали с директором по науке и душой нашей компании, доктором технических наук, профессором, членом-корреспондентом РАН Владимиром Львовичем Арлазаровым. Он – как, кстати, и еще несколько членов нашей команды Smart Engines – принимал непосредственное участие в создании первых систем автоматического ввода текста.
Сегодня речь пойдет про OCR Tiger и про то, как эта система работает.

Привет, я Дима Абакумов, разработчик в диджитал-агентстве ДАЛЕЕ. Расскажу, как я написал бота на Python, который находит дубли мемов в нашем мем-чате, и какие методы сравнения изображений для этого использовал.

Всем привет! Меня зовут Капитанов Александр, я отвечаю за направление компьютерного зрения в SberDevices. В этой статье я расскажу о том, как моя команда Vision RnD разработала серию моделей SignFlow, обеспечивающих перевод с жестового языка на русский и американский английский в реальном времени с высокой метрикой качества. На основе этих моделей мы реализовали прототип общения с генеративной языковой моделью GigaChat, что является первым в мире открытым решением задачи общения с искусственным интеллектом при помощи русского жестового языка (РЖЯ). Далее я расскажу о разработке модели, тонкостях обучения, демо-стенде и интеграции с GigaChat.

Про QR код на том же Хабре есть огромное количество информации. Ничего удивительного: сейчас сложно найти отрасль, где бы он не применялся. Тут и банковские операции, и идентификация товаров, и цифровые визитки. Преимущества очевидны: считывается мгновенно любым смартфоном, причем даже если треть QR кода повреждена, а еще хранит до 2935 байт двоичного кода.
Но сегодня поговорим не про технические нюансы. Вы знали, что его придумали благодаря любви к играм и небоскребам? Если не знали, устраивайтесь поудобнее — поговорим об истории появления QR кода.

Если несколько предметов, постоянно меняющих форму и положение, будут последовательно возникать перед глазами через очень короткие промежутки времени и на маленьком расстоянии друг от друга, то изображения, которые они вызывают на сетчатке, сольются, не смешиваясь, и человеку покажется, что он видел предмет, постоянно меняющий форму и положение.
Жозеф Плато, август 1833 года
В недавней статье мы рассказали о возможности создания анимированных видеороликов на основе комбинации синтеза изображений и различных способов преобразования этих изображений (сдвиги в стороны, масштабирование и т. д.). Сегодня же речь пойдёт про нашу новую технологию синтеза полноценного видео по текстовому описанию, которую мы назвали Kandinsky Video (для затравки пара примеров приведена на рисунке 1).

В прошлом году на АI Journey мы представили модель Kandinsky 2.0 — первую диффузионную мультиязычную модель генерации изображений по тексту, которая может генерировать изображения на основе русскоязычного текста. За ней последовали новые версии — Kandinsky 2.1 и Kandinsky 2.2, которые значительно отличались по качеству и своим возможностям от версии 2.0, и стали для нашей команды серьёзными вехами на пути к достижению лучшего качества генерации.
Спустя год после релиза нашей первой диффузионной модели мы представляем новую версию модели генерации изображений по тексту — Kandinsky 3.0! Это результат длительной работы нашей команды, которую мы вели параллельно с разработками версий Kandinsky 2.1 и 2.2. Мы провели много экспериментов по выбору архитектуры и проделали большую работу с данными, чтобы сделать понимание текста и качество генераций лучше, а саму архитектуру — проще и лаконичнее. Также мы сделали нашу модель более «отечественной»: теперь она значительно лучше ориентируется в российском и советском культурном поле.
В этой статье я кратко опишу ключевые моменты новой архитектуры, стратегию работы с данными и, конечно, продемонстрирую возможности нашей модели на примере генераций.



Привет! Я занимаюсь разметкой данных для ИИ: экспертно и с большой любовью. Задачи компьютерного зрения — одни из самых популярных и поэтому поговорим про них.
Прочитав статью вы узнаете как алгоритму отличить гейшу от китаянки, кто такая майко, как не перепутать лапшу с автобусом и правильно найти тунца.
Практически сразу после выхода zero-shot модели SAM (Segment Anything Model) для компьютерного зрения мы с командой активно ее внедрили в свою платформу разметки данных и стали использовали в разных задачах.
Хочется поделиться опытом и ответить на самый популярный вопрос — насколько SAM ускоряет разметку данных?
В статье будет очень много гифок и интерактива.
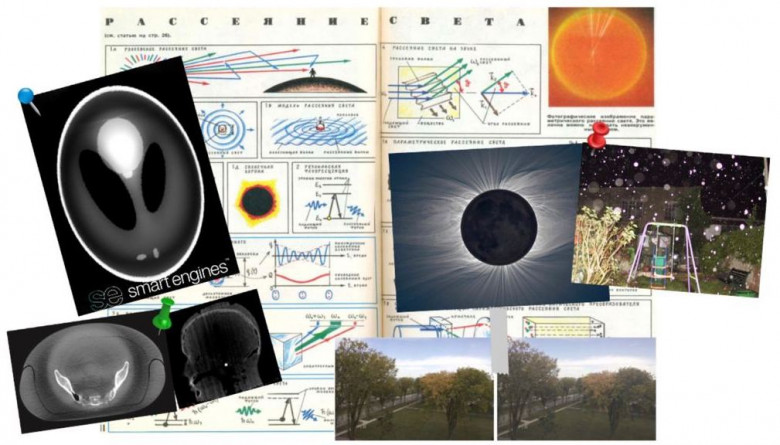
Мы в компании Smart Engines разрабатываем томографическое программное обеспечение и стараемся делать это как можно качественнее, без появления на изображении реконструкции визуальных искажений, так называемых артефактов. Одной из причин возникновения артефактов является несоответствие модели формирования изображения в измерениях и модели описания данных для алгоритмов томографической реконструкции.
В классической постановке КТ описанием внутренней структуры образца служит пространственное распределение коэффициента ослабления рентгеновского излучения, причем зондирующее излучение считается монохроматическим. Однако в реальных установках это не так, существенное влияние на изменение модели формирования изображений оказывают эффекты второго порядка. Одним из которых является рассеянное излучение. Что такое рассеяние, каким оно бывает и как выглядят артефакты рассеяния в томографии, - расскажем в сегодняшней нашей статье.

Фото до (слева) и после (справа) калибровки камеры
В первой части статьи мы немного поупражнялись на яблоках, чтобы понять, как 3D-объекты проецируются на 2D-плоскость фотографии. Заодно мы описали математическую модель камеры и ее параметры.
Знаешь параметры — живешь в Сочи можешь восстановить 3D-сцену или ее характеристики: высоту здания, расстояние до пешехода, загруженность самосвала. Словом, сплошная польза для целого ряда отраслей.
А вот как именно определить эти заветные параметры, так и осталось за кадром. К тому же мы рассматривали простейшую модель pinhole, но в реальной жизни все сложнее. У большинства камер есть линзы, которые искажают изображения (вспомните эффект fisheye). Все эти «рыбьи глаза» и другие отклонения нужно как-то корректировать.
О том, как восстанавливать параметры камеры (калибровать ее) и нивелировать искажения (дисторсию), читайте в этой публикации.
Также из нее вы узнаете:
• как выглядит математическая модель калибровки и дисторсии;
• как собрать датасет для калибровки;
• какие есть методы калибровки;
• детали одного из этих методов.

Развитие text2image-моделей открывает новые интересные возможности для создания креативного контента. Функция inpainting в Kandinsky позволяет создавать видео zoom in и zoom out с иллюзией приближения или отдаления от единого изображения. Таким образом Sber AI с коллегами из SberDevices продолжают развивать генеративные модели и расширяют творческие возможности умных устройств семейства "Салют".
В разговорах с коллегами, а также по отдельным постам на форумах я заметил, что даже относительно опытные разработчики порой не достаточно глубоко понимают особенности хранения изображений в памяти. Если вы знаете, что такое выравнивание на границу 64-x байт, а также термины типа «длина или шаг строки (LineWidth/StepWidth, Stride)», «зазоры выравнивания (Alignment Gaps)», кроме того в курсе размеров линий кэша и страниц памяти на вашем компьютере, то вам, вероятно, не будет интересно, а остальные, особенно те, кто интересуется обработкой изображений — могут ознакомиться с предлагаемым материалом, и, возможно найдут для себя что-то новое и полезное. Под катом будет немножко кода на Си и ассемблере, пара LabVIEW скриншотов, предполагается также, что у читателя есть базовые знания OpenCV. Для экспериментов понадобится компьютер с камушком, поддерживающим AVX2.