Открываем историю Большого театра. Часть первая
7 мин

Вы когда-нибудь собирали театральные программки? Если да, то, наверное, в вашей коллекции их десятки, а может, наберется и сотня. А теперь представьте, что в вашем распоряжении 120 тысяч программок, 48 тысяч афиш и 100 тысяч исторических фотографий. Столько бумажных документов сохранил с середины XIX века Большой театр. Самые древние и ценные из них уже пожелтели и стали ветхими, а на поиск информации в театральном архиве уходили часы. Чтобы сохранить эти сокровища, сотрудники театрального музея начали вручную переводить документы в электронный вид, но оказалось, что на это могут уйти годы.
Поэтому в сентябре 2016 года вместе с Большим театром и при активной поддержке Феклы Толстой, праправнучки Льва Николаевича Толстого, мы запустили краудсорсинговый проект по оцифровке истории главного театра страны. В этом посте мы расскажем о подробностях первого этапа проекта и о его технических деталях: как мы оцифровывали уникальные документы с помощью ABBYY FineReader и как волонтеры помогали проверять результаты распознавания.



 , и добро пожаловать под кат.
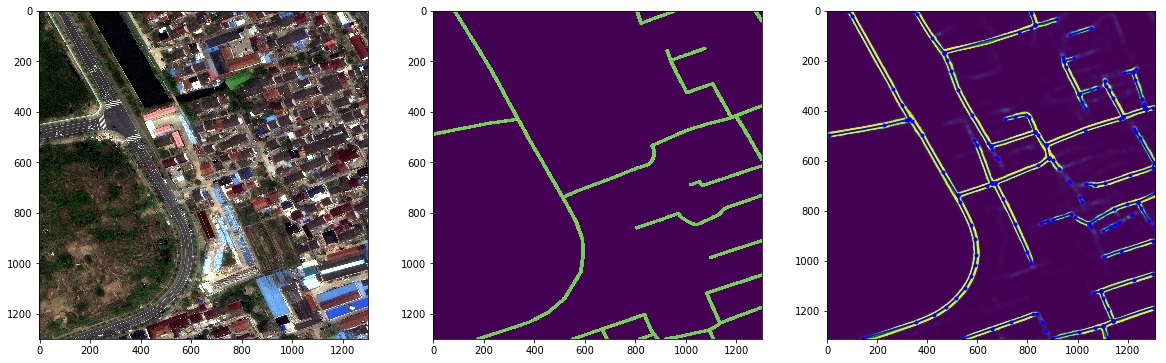
, и добро пожаловать под кат. С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
С развитием компьютерных мощностей и появлением множества технологий обработки изображений всё чаще стал возникать вопрос: а можно ли научить машину видеть и распознавать образы? Например, отличать кошку от собаки или даже бладхаунда от бассета? О точности распознавания говорить не приходится: наш мозг несравнимо быстрее может понять, что перед нами, при условии, что раньше мы получили достаточно сведений об объекте. Т.е. даже видя только часть собаки, мы можем с уверенностью сказать, что это собака. А если ты — собаковод, то легко определишь и породу собаки. Но как научить машину различать их? Какие существуют алгоритмы? А можно ли обмануть машину? (Спойлер: конечно можно! Точно так же, как и наш мозг.) Попробуем осмыслить все эти вопросы и по возможности ответить на них. Итак, приступим.
 В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить?
В последнее время машины одержали ряд убедительных побед над людьми: они уже лучше играют в го, шахматы и даже в Dota 2. Алгоритмы сочиняют музыку и пишут стихи. Учёные и предприниматели всего мира дают прогнозы по поводу будущего, в котором искусственный интеллект сильно превзойдёт человека. С большой вероятностью через несколько десятков лет мы будем жить в мире, в котором роботы не только водят автомобили и работают на заводах, но и развлекают нас. Одна из важных составляющих нашей жизни — юмор. Принято считать, что только человек может придумывать шутки. Несмотря на это, многие ученые, инженеры и даже простые обыватели задаются вопросом: можно ли научить компьютер шутить?