От Style Transfer до диффузии: эволюция визуальных эффектов на смартфонах
Средний
11 мин

Четыре года я занимаюсь разработкой различных спецэффектов для фото и видео в мобильных приложениях. Вроде бы это локальная и как бы несерьезная тема, но одну только плачущую маску в Snapchat посмотрели 9 млрд раз. Такие штуки пользуются бешеной популярностью и здорово повышают виральность мобильных приложений, но с каждым годом удивлять людей становится все сложнее.
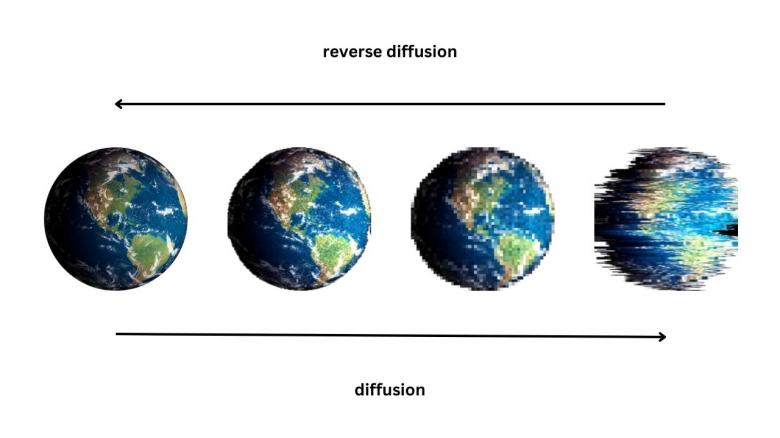
В этой статье я разберу эволюцию видеоэффектов, поделюсь наблюдениями и раскрою пару инсайдов о том, как перенести стилизацию изображения из StableDiffusion на смартфоны.