Перенос молекулярной динамики на CUDA. Часть III: Внутримолекулярное взаимодействие
17 мин
До этого мы рассматривали молекулярную динамику, где законы взаимодействия между частицами зависели исключительно от типа частиц или от их заряда. Для веществ молекулярной природы взаимодействие между частицами (атомами) сильно зависит от того, принадлежат ли атомы одной молекуле или нет (точнее, связаны ли они химической связью).
Например, вода:
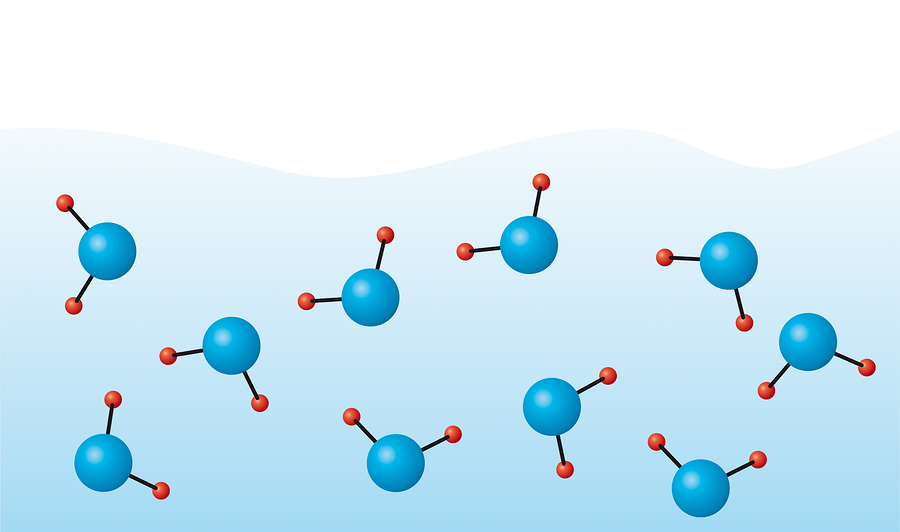
очевидно, что водород с кислородом внутри одной молекулы взаимодействуют совсем по-другому, нежели тот же кислород с водородом соседней молекулы. Таким образом, разделяют ВНУТРИмолекулярное (intramolecular) и МЕЖмолекулярное (intermolecular) взаимодействие. Межмолекулярное взаимодействие можно задать короткодействующими и Кулоновскими парными потенциалами, о которых речь шла в предыдущих статьях. Здесь же сконцентрируемся на внутримолекулярном.
Например, вода:
очевидно, что водород с кислородом внутри одной молекулы взаимодействуют совсем по-другому, нежели тот же кислород с водородом соседней молекулы. Таким образом, разделяют ВНУТРИмолекулярное (intramolecular) и МЕЖмолекулярное (intermolecular) взаимодействие. Межмолекулярное взаимодействие можно задать короткодействующими и Кулоновскими парными потенциалами, о которых речь шла в предыдущих статьях. Здесь же сконцентрируемся на внутримолекулярном.