Практический гайд по процессам и потокам (и не только) в Python
Средний
5 мин
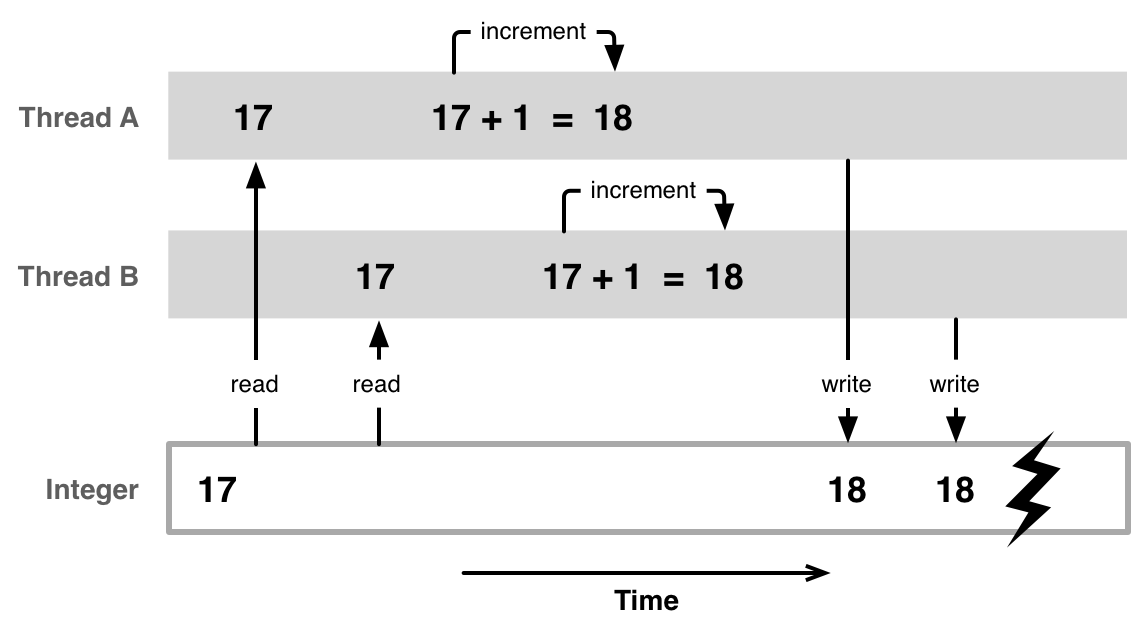
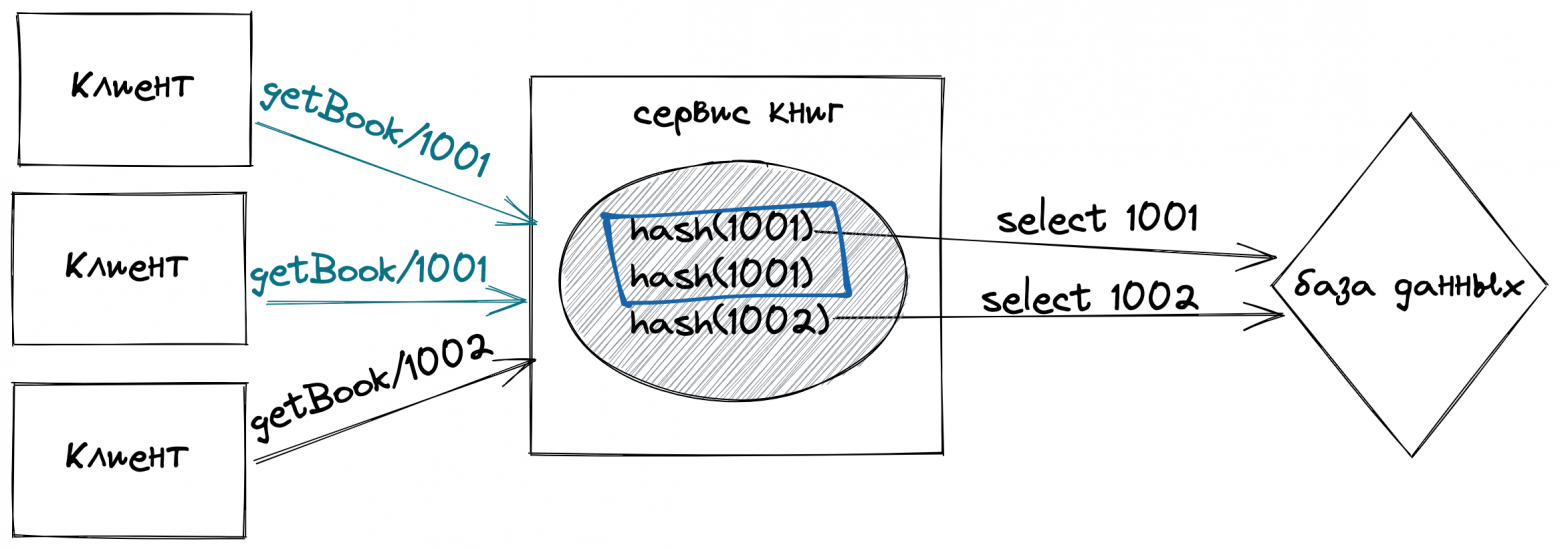
За то время что я занимаюсь менторством я заметил, что большинство вопросов новичков связаны с темами: конкурентность, параллелизм, асинхронность. Подобные вопросы часто задают на собеседованиях, в работе эти знания позволяют писать более эффективные и производительные системы.
Цель статьи - понятно и доходчиво, используя примеры кода и бенчмарки рассказать о том какие инструменты есть в Python и как с их помощью добиться высокой производительности.