

В начале апреля в Рэдиссон-Славянской в Москве пройдёт очередная конференция постгрессистов. Программному комитету удалось собрать много интересных докладов, часть из которых я хотел бы анонсировать тут.
В начале апреля в Рэдиссон-Славянской в Москве пройдёт очередная конференция постгрессистов. Программному комитету удалось собрать много интересных докладов, часть из которых я хотел бы анонсировать тут.

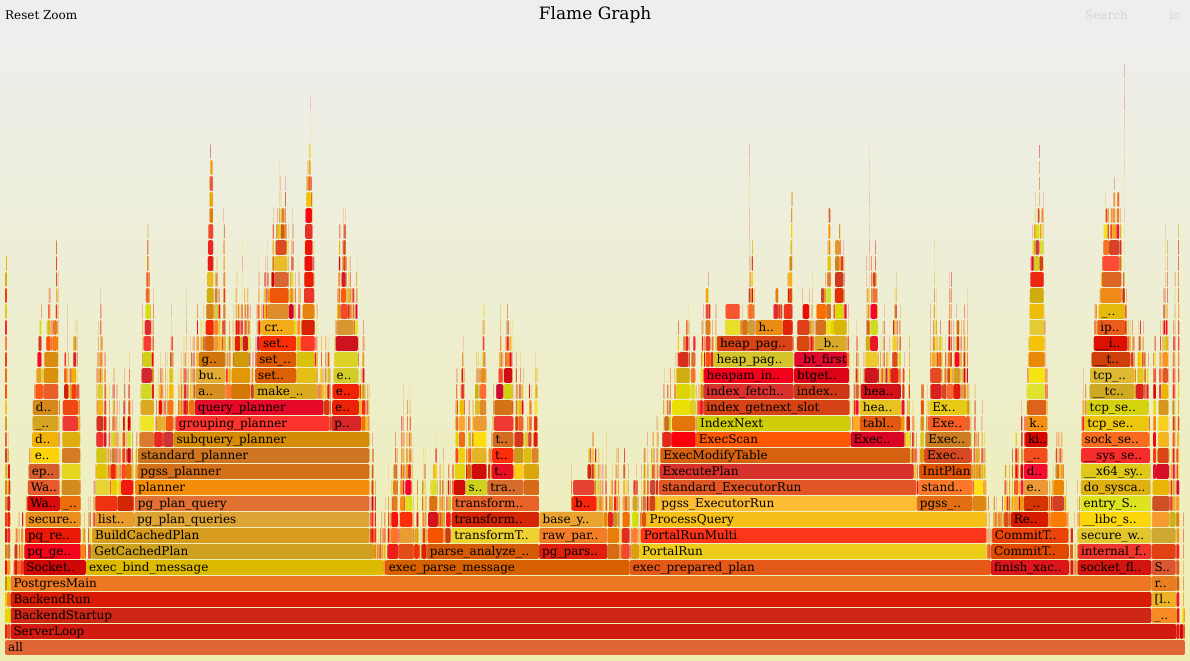
В этой статье мы разберём несколько аномальных случаев высокой нагрузки в СУБД PostgreSQL. Что это такое? Обычно PostgreSQL хорошо показывает себя под нагрузкой и оправдывает ожидания в отношении производительности — она остаётся высокой. Но при определённых профилях нагрузки СУБД может вести себя не так, как мы ожидаем. Это и есть аномалии, на которых мы сосредоточимся в данной статье (для тех, кто предпочитает видео, эта информация доступна в виде записи доклада на HighLoad++).
Наша компания помогает обслуживать мультитерабайтные базы данных в крупных проектах, поэтому мой рассказ об аномалиях основан на реальном опыте промышленной эксплуатации СУБД в Postgres Professional — порой мы сталкиваемся с тем, что СУБД ведёт себя не так, как мы ожидали.
Также в рамках статьи мы рассмотрим следующее:

Большие данные — вещь относительная. Посмотрите на любого блогера: он генерирует кучу данных, в его телефоне десятки, а то и сотни гигабайтов изображений и видео. Если он не может обработать их с помощью подручных средств, их вполне можно считать большими данными.
При этом оцифрованная Библиотека конгресса в США совсем маленькая, хранить ее у себя дома может любой. Телескопы, на которых работают в Америке, могут производить несколько десятков терабайт за одну ночь. А радиотелескоп, размер которого квадратный километр, будет производить петабайты.


Привет! Меня зовут Дима Вагин, я бэкенд-инженер в Авито. Сегодня расскажу, как мы работаем с БД PostgreSQL из Go. Покажу, какие библиотеки и пулеры соединений мы используем для доставки в код параметров подключения и как мы их настраиваем. А ещё расскажу про проблемы, к которым приводит отмена контекста, и о том, как мы с ними справляемся.

Продолжу рассказ "Как поместить весь мир в обычный ноутбук: PostgreSQL и OpenStreetMap" секретами о геоданных OpenStreetMap, на которых множество компаний построили бизнес но не все делятся подробностями... Что ж, сегодня приоткроем завесу!
База данных в PosgreSQL после загрузки из дампа занимает больше 587 GB. Это уже по меркам СУБД большая база и одна огромная таблица на каждый тип объектов не сработает. Для управляемости такие данные надо секционировать, хорошо что PostgreSQL поддерживает декларативное секционирование данных. Осталось лишь придумать как разделить географические данные. После поисков и сравнений мне на помощь пришла иерархическая гексагональная геопространственная система индексирования H Все это было реализовано в моем проекте openstreetmap_h3 для быстрой обработки и загрузки мира в базу.

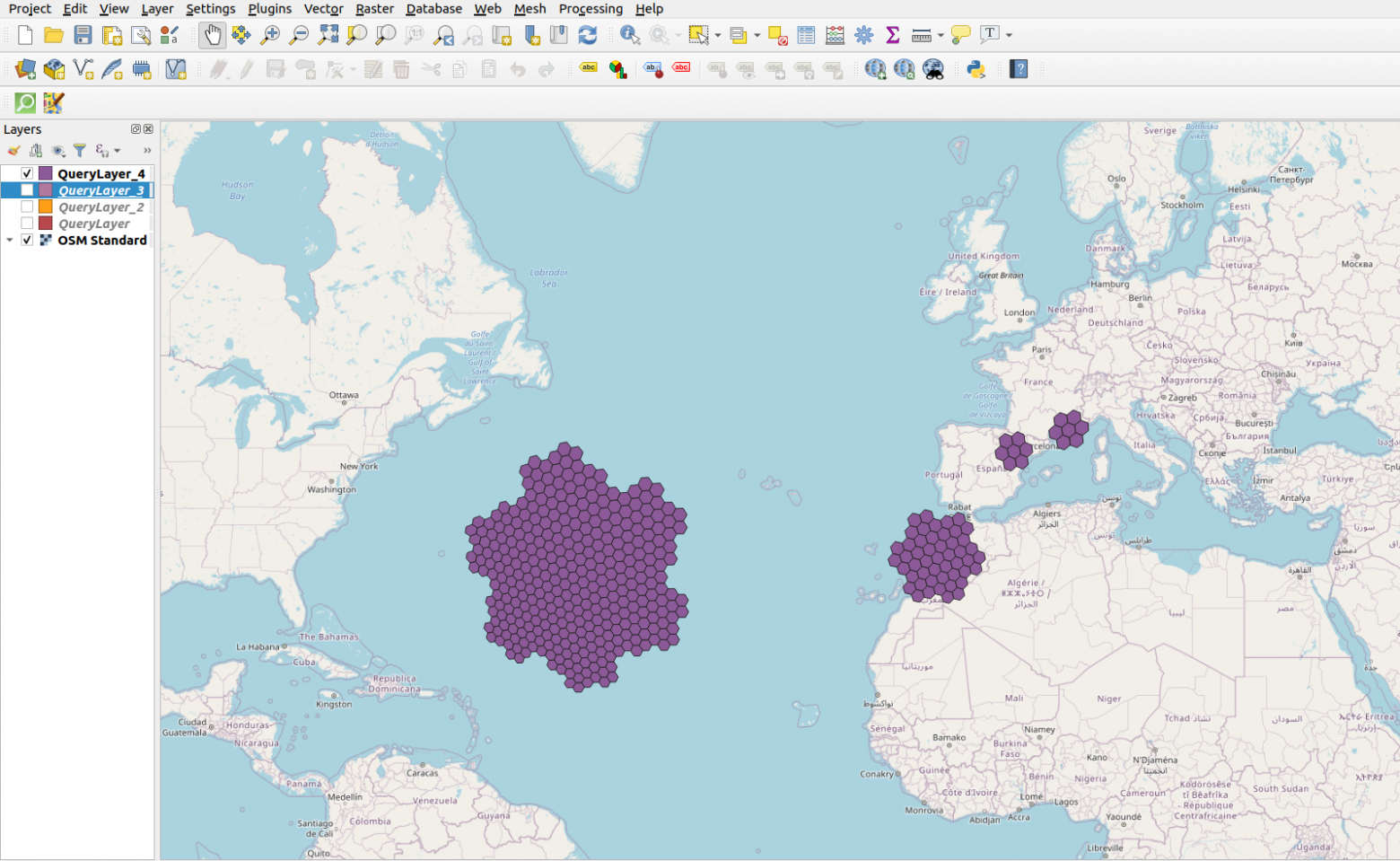
Когда человек раньше говорил что он контролирует весь мир, то его обычно помещали в соседнюю палату с Бонапартом Наполеоном. Надеюсь, что эти времена остались в прошлом и каждый желающий может анализировать геоданные всей земли и получать ответы на свои глобальные вопросы за минуты и секунды. Я опубликовал Openstreetmap_h3 — свой проект, который позволяет производить геоаналитику над данными из OpenStreetMap в PostGIS или в движке запросов, способном работать с Apache Arrow/Parquet.
Первым делом передаю привет хейтерам и скептикам. То что я разработал — действительно уникально и решает проблему преобразования и анализа геоданных используя обычные и привычные инструменты доступные каждому аналитику и датасаенс специалисту без бигдат, GPGPU, FPGA. То что выглядит сейчас простым в использовании и в коде — это мой личный проект в который я инвестировал свои отпуска, выходные, бессонные ночи и уйму личного времени за последние 3 года. Может быть я поделюсь и предысторией проекта и граблями по которым ходил, но сначала я все же опишу конечный результат.
Первый пост не претендует на монографию, начну с краткого обзора...

Можно ли найти конкретного человека, жившего в XVII веке? Выражаясь современным языком «пробить по базам». Оказывается, архивные документы хранят массу информации об обычных людях того периода. Однако существует ряд сложностей, не позволяющих обычному исследователю добраться до этой информации. Во-первых, нужно пройти определённую процедуру по получению доступа в архив. Во-вторых, не всегда можно выйти на нужный документ, используя так называемый научно-справочный аппарат – различные описи и реестры документов, имеющиеся в архиве. Наконец, не имея навыков чтения документов XVII века, которые написаны скорописью, почти нереально ознакомиться с его содержанием.
Данные проблемы предполагается решить с помощью создания базы данных служилых людей XVII века. Об этом небольшая история.
Как всё начиналось.
Привет! Меня зовут Дмитрий и вот уже более 10 лет я изучаю историю южных уездов России XVII века. Территориально – это современные Белгородская, а также соседние Воронежская, Курская, Липецкая и другие области. Населены они были тогда так называемыми служилыми людьми – они получали здесь в качестве служебного жалования земельные наделы, которые сами и обрабатывали. В XVIII веке их потомки стали однодворцами, а затем государственными крестьянами. Большая часть населения Курской, Воронежской и соседних губерний XIX века происходят из тех самых служилых людей XVI–XVII веков.

У нас не подгорит!
Как PostgreSQL хранит большие значения столбцов? Какие явные и неявные ограничения есть у существующего механизма хранения? Что за проблемы вызваны этими ограничениями? И как можно решить эти проблемы, и расширить возможности PostgreSQL? Об этом, и чуть больше - данная статья.
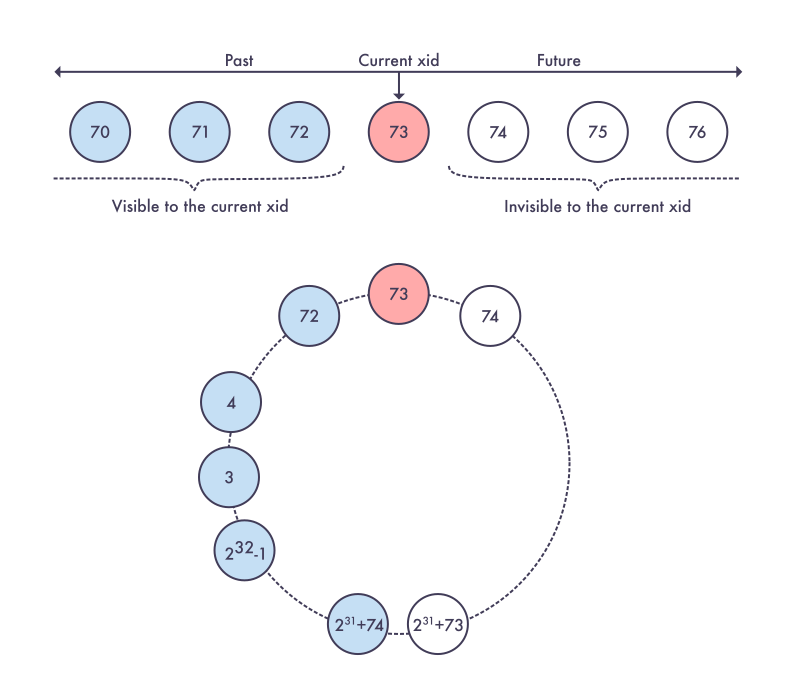
Эта статья описывает реализацию 64–битных счётчиков транзакций (XID, ксидов) в СУБД Postgres Pro Enterprise, которая создана на основе свободной, опенсорсной объектно–реляционной СУБД Postgres. Она ориентирована на тех, кто имеет практический опыт в работе с СУБД Postgres Pro Enterprise, но будет интересна и тем, кто интересуется развитием СУБД Postgres, так как описывает сравнение этих двух систем. Статья также описывает устройство таблиц на диске и организацию формата хранения данных отношений.
Postrges старается быть максимально гибким в конфигурации, чтобы удовлетворить запросы как можно большего числа своих пользователей. Большинство параметров, например, таких, как: размер страницы BLCKSZ (по умолчанию 8 кБ), размер сегмента SEGSIZE (по умолчанию 1 Гб), могут быть изменены при сборке Postgres.
Хотелось бы сразу обозначить, что мы будем рассматривать 64–битный вариант сборки Postrges, в котором все параметры имеют значение по умолчанию. Также мы не будем углубляться в мультитранзакции. Для целей этой статьи будет достаточным предположения, что они в данном контексте аналогичны "обычным" транзакциям.
Мы выложили наш вариант реализации в сообщество, а также занимаемся активным продвижением его в сообществе разработчиков Postgres. Он не на 100% идентичен коду, используемому в Postgres Pro Enterprise (в частности, там ксиды всё ещё образуют кольцо), но общая идея такая же, как изложена в статье. На текущий момент патч ожидает ревью. Мы верим, что этот патч положительно скажется на удобстве использования и устойчивости Postgres, надеемся, что он будет принят сообществом в ближайшем будущем. Тем не менее по этому вопросу предстоит ещё много работы. Поэтому мы будем благодарны всем желающим и небезразличным за посильное участие в его развитии.


Возможность горизонтального масштабирования это одно из важнейших нефункциональных требований индустрии в последнее время. Рост бизнеса со стороны IT выглядит чаще всего как рост нагрузки и цены отказа системы. Нам всем хочется создавать такие приложения, которые будут одинаково быстро и стабильно работать как с сотней, так и с сотней тысяч клиентов. Для этого необходимо еще на стадии проектирования закладывать потенциал для масштабирования, одним из способов которого является шардирование.
Мы на пальцах рассмотрим что такое шардирование, как оно помогает в масштабировании и даже рассмотрим тот самый этап «роста».

Представим, что у вас есть некоторая табличка статистики, куда вы периодически скидываете таймстамп последнего "текущего" состояния в паре координат - например, (ID организации, ID сотрудника).
Как больно наступить на грабли в совсем простом, казалось бы, запросе?

Навскидку многим кажется, что они знакомы с поведением NULL-значений в PostgreSQL, однако иногда неопределённые значения преподносят сюрпризы. Предлагаем вашему вниманию расшифровку доклада Алексея Борщева с PGConf.Russia 2022 — он был полностью посвящён особенностям NULL-значений в Postgres.
NULL простыми словами
Что такое SQL база данных? Согласно одному из определений, это просто набор взаимосвязанных таблиц. А что такое NULL? Обратимся к простому бытовому примеру: все мы задаём друг другу дежурный вопрос: «Как дела?». Часто мы получаем в ответ: «Да ничего...» Вот это «ничего» нам и нужно положить в базу данных — NULL, неопределённое, некорректное или неизвестное значение.

Наверняка, многие из вас пользуются explain.tensor.ru - нашим сервисом визуализации PostgreSQL-планов или уже даже развернули его на своей площадке. Но визуализация конкретного плана - это лишь небольшая помощь разработчику, поэтому в "Тензоре" мы создали сервис, который позволяет увидеть сразу многие аспекты работы сервера: медленные или гигантские запросы, возникающие блокировки и ошибки, частоту и результаты проходов [auto]VACUUM/ANALYZE.
И сегодня мы, наконец, готовы представить вам демо-режим этого сервиса, куда вы самостоятельно можете загрузить лог своего PostgreSQL-сервера и наглядно увидеть, чем он у вас занимается.

Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.

Писать SQL руками или использовать ORM — тема очень спорная, и я опишу, как использовать первый подход максимально эффективно. А какой из подходов выбрать, думаю, каждый сам для себя уже решил.
Японцы уже в 2018 году научили немецкий GraphHopper строить маршруты по дорогам хранящимся в PostgreSQL.
Как кастомизировать источник данных, и сохранять новые дороги в таблицу правильно?