Медицинские исследования играют важную роль в понимании различных заболеваний и разработке эффективных методов лечения. Одним из инструментов, используемых в кардиологии, является фонокардиограмма (ФКГ).
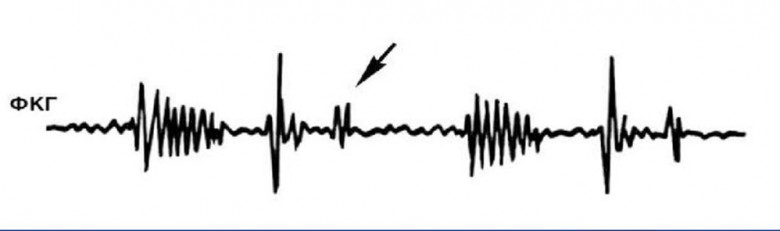
Фонокардиограмма - это метод диагностики сердечно-сосудистой системы, который основывается на записи звуков, производимых сердцем. Она может быть полезной в определении различных заболеваний сердца, таких как стеноз клапана, митральный стеноз, митральную недостаточность, перикардит и другие.
ФКГ может использоваться для оценки эффективности лечения сердечных заболеваний и для наблюдения за состоянием сердца в течение времени. Если у вас есть симптомы, такие как боль в груди, одышка, учащенный пульс, упадок сил, обратитесь к кардиологу, который посоветует, нужна ли вам ФКГ [1].
Объектом исследования выпускной квалификационной работы является список файлов формата .csv, содержащих разделенные знаком ";" смещенные целочисленные значения амплитуды шумов сердца, записанные в течение нескольких секунд, частота дискретизации – 1000 гц (числа в записи обозначают амплитуду сигнала, временной промежуток между соседними значениями - 1 миллисекунда).
Цель работы состоит в создании алгоритма автоматической интерпретации снятых данных, который пытается по форме кривых делать выводы, аналогичные тем, которые по этим же кривым умеет делать эксперт и создание собственного алгоритма. Необходимо определить и выделить точку максимальной амплитуды, начало и окончание тона 1 для каждого из сердечных циклов. Ответ необходимо вывести в виде списка списков [t1, t2, t3], где t1 – начало тона 1, t2 – точка максимальной амплитуды, t3 – окончание тона 1. Также, для проверки результата, необходимо визуализировать полученный результат на графике. Данную процедуру необходимо произвести для каждого файла.
Ссылка на github: medical_date/script.py at main · ReshetnikovDmitrii4918/medical_date (github.com)