
Сборка OpenCV с поддержкой OpenVINO
Средний
3 мин

В статье мы соберём OpenCV с поддержкой OpenVINO, а также узнаем отличия в скорости инференса модели машинного зрения на C++ и Python при прочих равных.
В статье мы соберём OpenCV с поддержкой OpenVINO, а также узнаем отличия в скорости инференса модели машинного зрения на C++ и Python при прочих равных.
Этот блокнот познакомит вас с основами Petals — системы логического вывода и точной настройки языковых моделей с сотнями миллиардов параметров без необходимости использования высокопроизводительных GPU. С помощью Petals вы можете объединять вычислительные ресурсы с другими людьми и запускать большие языковые модели с миллиардами параметров, например BLOOM-196B или BLOOMZ того же размера, что и GPT-3.

Небольшой рассказ с картинками о проведении тематического моделирования для массива документов, на примере датасета анекдотов на русском языке. В работе применены библиотеки Gensim, Sklearn. Рассмотрены разные способы векторизации токенов bag of words, tf-idf. Получены результаты для обсуждения и продолжения.
Велком...

Делай красиво, а некрасиво не делай.
Python — это язык программирования, уделяющий много внимания тому, как мы пишем код. Самый первый пункт Zen of Python, принципов разработки на Python от его BDFL: «Beautiful is better than ugly». Красивое лучше уродливого. Это само по себе простое и понятное утверждение, вынесенное на первое место в дзэне, напоминает нам простую истину — мы пишем код для людей, а не для машин. Машине для исполнения программы хватит нулей и единиц в бинарном файле, человек же куда более требователен.
Именно поэтому в разработке кода мы стараемся использовать все доступные средства, для того чтобы сделать его удобным для чтения и понятным человеку. В Python множество инструментов, которые могут помочь улучшить читаемость кода, и Context manager, о котором дальше пойдет речь, один из них.

Приветствую, читатели. Думаю, что для каждого, кто хоть раз в жизни интересовался темой программирования, знаком такой язык, как Python. Все-таки он самый популярный в мире на данный момент.
И это неспроста, способствовали его популяризации универсальность и относительная простота в изучении. А изучить базовый курс и получить звание младшего разработчика так и вовсе можно за несколько месяцев.
Также будет правильно подметить, что использование именно этого языка достаточно популярно в кругах злоумышленников и львиная доля вредоносных программ написаны именно на Python.
Но на этот раз злодеи зашли куда дальше, нацелившись на самих Python разработчиков. Ещё в ноябре 2022 года многие исследователи обнаружили более 400 вредоносных пакетов, загруженных в официальный репозиторий Python Package Index (PyPI)...

Вообще я, как правило, нормально программирую. Иногда даже такое заворачиваю, что сам тащусь весь день.
Но если б я писал, какой я красавчик, то никому не было бы интересно. Поэтому сегодня — очередная партия программистских историй от меня любимого, с косяками, багами и болью. Иногда это происходило по запарке, или когда я торопился, или после нудной работы, когда мозг уже плавился, а иногда просто я тупил, потому что я человек. В общем, такие вот типичные будни кодера. Наслаждайтесь!

Развитие искусственного интеллекта сейчас переживает бурный рост, и сфера его применения постоянно расширяется, проникая в области, ранее никак не связанные с ИТ.
Хорошим примером такой экспансии является спорт.
Не так давно появился термин Sport tech и количество проектов значительно выросло за последние несколько лет.
Волейбол — перспективное направление в спортивной аналитике. Один из самых массовых видов спорта, распространен в очень многих странах.
Итак, у нас есть видеозапись волейбольной игры. С какой целью она обычно делается? Возможно, чтобы показать друзьям или пересматривать лучшие моменты долгими зимними вечерами. Но наверное, в сыром виде, запись не очень годится для этого. Ведь скорее всего, первые минут десять игроки будут переодеваться и разминаться, а после каждого розыгрыша будет проходить минута‑другая, пока кто‑то сбегает за мячом.
В общем, мы подходим к очевидной цели — избавиться от всего скучного и оставить только самое интересное. Ок, стратегия ясна, переходим к тактике.
Для стороннего зрителя (которым конечно является искуственный интеллект) есть несколько маркеров для привлечения внимания: игроки, мяч, судья, табло. Любой из этих объяектов может быть подвергнут аналитике. Но сегодня мы поговорим о мяче.
Связь зрительского интереса и мяча вполне очевидна: мяч летает — мы смотрим. Нет мяча — некуда смотреть. В общем, понятно, что нам надо вырезать все кадры, где мяч не летает и тогда это можно будет смотреть без зевоты.

В данной статье поэтапно расскажу, как подключится к Jira используя Python и выгрузить историю изменений статуса.

В программных продуктах для работы с STL, таких как Geomatix Design X, Wrap, NX и др., функционал обязательно включает сегментацию STL модели на отдельные грани. В свободно распространяемом ПО, однако, инструменты для сегментации зачастую отсутствуют. В данной статье хочу рассказать о реализованном мной на Python алгоритме разбиения STL на отдельные грани.
Мне часто приходится пользоваться PowerShell. Конечно, его создатели не имели никакого представления о прекрасном и эстетике. Уродливость PowerShell особенна видна при его сравнении, например, с Python. С другой стороны, как говорится, c лица не воду пить - работает и хорошо? Но нет, мне кажется в PowerShell есть по крайней мере пара моментов, которые фатально влияют на его практическое применение.

А почему бы не использовать возможности chatGPT и попросить его делать что-то за нас?
Например, давайте попробуем настроить его так, чтобы он мог забронировать нам столик в наш любимый ресторан.

Введение
У меня была задача «Собирать статистику постов в vk каждый час». Я не являюсь разработчиком или DevOps специалистом. Поэтому мой способ решения задачи сложился из поисковых запросов, личного опыта, советов друзей и коллег.
Решение я разбил на 2 части.

В процессе автоматизации часто появляются интересные задачи, к которым, на первый взгляд, абсолютно непонятно как подступиться. Об одной из таких задач сегодня и пойдёт речь.
Статья об автоматизации тестирования веб-приложения в связке с telegram ботом с использованием Telethon и очереди сообщений.

Предположим у вас есть сайт на котором вы хотите в автоматическом режиме консультировать посетителей. Само собой сейчас это уже хочется делать с использованием chatGPT.

Привет, уважаемый читатель!
Пришла пора внедрить систему аутентификации от Apple в проект на Django DRF, ведь система входа от Google была реализована давно и по идее проблем не должно было возникнуть, но как сказал один известный гном: "Я ещё никогда так не ошибался..." А теперь по порядку.
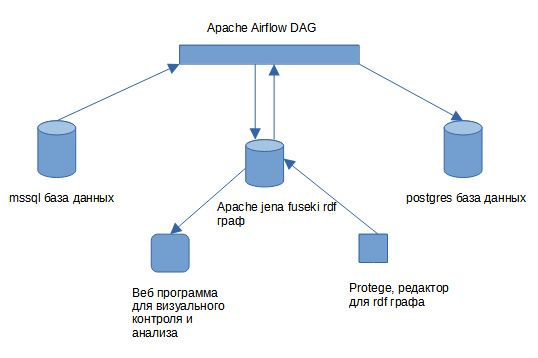
Хочется поделиться опытом преображения одного представления кода в другой с помощью ETL процесса и графовой базы данных на актуальном в наши дни примере.
Вкратце есть база на mssql сервере есть хранимые процедуры. Есть база на postgres. Есть ETL процесс на Apache Air Flow. Запускаем процесс, по окончании в базе postgres появляются процедуры и данные.
Скажу сразу данный подход не является полным автоматом, который перенесет любую mssql базу на postgres. Это попытка систематизировать подобный переход, разбить переход на управляемые небольшие части, которые типизируются и над которыми выполняются преобразования с возможностью контроля результата.
Допустим у нас есть зарегистрированные пользователи и какая-то модель, например "Компании", которую пользователь может добавлять в избранное. Обычно такая задача решается путем создания третьей таблицы Favorite, являющейся связующим звеном, для реализации ManyToManyField связи между пользователем и компанией

Саша начинает свой карьерный путь в качестве аналитика. Директор ставит задачу: подготовить отчёт по эффективности сотрудников. Саша решает выполнять задачу с помощью Python. У аналитика есть минимальный опыт программирования.
Саша выгружает данные по первому отделу из таск трекера и пишет код для обработки данных. Код работает, хоть и состоит на 70% из неуниверсальных полуавтоматизированных фрагментов. При выгрузке данных по другим подразделениям формат файла меняется. Код требует постоянных ручных изменений, а срок сдачи отчёта поджимает.
Эта статья о том, какие ошибки допускает Саша при написании кода и как исправляет их. Расскажем, как сделать код более универсальным, чтобы он подходил к меняющимся файлам. Статья подойдёт для начинающих аналитиков, которые только знакомятся с Python.

В статье вы узнаете про мой подход к реализации mapper SQLAlchemy <-> Strawberry (GraphQL). Значительная часть статьи состоит из кода!
