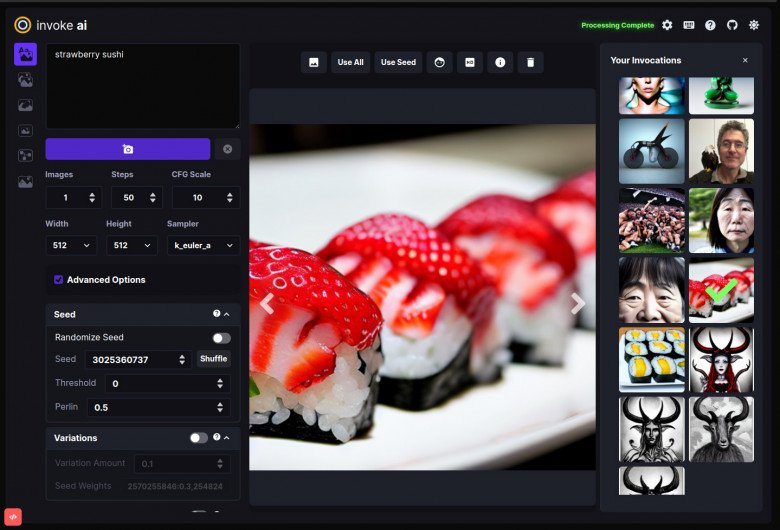
В Кремниевой долине есть очень особенный ресторан фаст-фуда, который всегда открыт. Там имеется один столик, за ним может разместиться лишь один посетитель, которому дадут совершенно фантастический гамбургер. Когда туда приходишь — ждёшь до тех пор, пока не настанет твоя очередь. Потом хозяин ресторана подведёт тебя к столику, и, это же Америка, тебе зададут, кажется, бесконечное количество вопросов о том, как приготовить и как подать твой гамбургер.
Сегодня, правда, мы не собираемся говорить о кулинарных изысках. Мы говорим о системе очередей, которую используют рестораны. Если вам повезло и вы прибыли в ресторан тогда, когда столик пуст, и когда никого в очереди нет, вы можете прямо сразу за него сеть. В противном случае хозяин даст вам специальный пейджер (из бескрайней кучи таких пейджеров!) и вы можете бродить вокруг ресторана до тех пор, пока этот пейджер не подаст сигнал. Дело хозяина ресторана — обеспечить, чтобы посетители попадали бы за столик в порядке их прибытия. Когда настанет ваша очередь, хозяин отправит сигнал на ваш пейджер, а вы вернётесь в ресторан, где сможете усесться за столик.
Если вы передумали — можете вернуть пейджер хозяину, а он, ни слова не сказав, спокойно его заберёт. Если ваш пейджер уже сработал, то хозяин, если на вас очередь не оканчивается, вызовет следующего посетителя. Посетители этого ресторана всегда вежливы, они, получив пейджер, не уходят украдкой, никого не предупредив. А хозяин всегда честен и не усадит за столик кого-то, кто стоит в очереди за вами, даже если вам, чтобы вернуться в ресторан после срабатывания пейджера, нужно некоторое время.