Небольшой модуль для работы с массивами в Python без использования сторонних библиотек (клон NumPy, но только на чистом Python).

В поиске интересного и простого ДатаСета я набрёл этого красавца.
В нём есть данные о росте и весе 10 000 мужчин и женщин. Никакого описания. Ничего «лишнего». Только рост, вес и метка пола. Эта таинственная простота мне понравилась.
Что ж, начнём!
Погнали!

В первой статье о структуре QVD-файла я описал общую структуру и достаточно подробно остановился на метаданных, во второй — на хранении колонок (символов). В этой статье я опишу формат хранения информации о строках, подытожу, расскажу о планах и достижениях.
Итак (вспоминаем) QVD-файл соответствует реляционной таблице, в QVD файле таблица хранится в виде двух косвенно связанных частей:
Таблицы символов (термин мой) содержат уникальные значения каждой колонки исходной таблицы. О них я рассказывал во второй статье.
Таблица строк содержит строки исходной таблицы, каждая строка хранит индексы значений колонки (поля) строки в соответствующей таблице символов. Именно об этои и будет эта статья.
В первой статье о структуре QVD файла я описал общую структуру и достаточно подробно остановился на метаданных. В этой статье я опишу формат хранения информации о колонках, поделюсь своим опытом трактовки этих данных.
Итак (вспоминаем) QVD файл соответствует реляционной таблице, которая, как известно состоит из строк. Каждая строка таблицы в свою очередь состоит из колонок (или полей), причем строки имеют одинаковую структуру, которая может быть описана, например, SQL оператором (create table).
В QVD файле таблица хранится в виде двух косвенно связанных частей:
Таблицы символов (термин мой) содержат уникальные значения каждой колонки исходной таблицы. Именно о них пойдет речь ниже.
Таблица строк содержит строки исходной таблицы, каждая строка хранит индексы значений колонки (поля) строки в соответствующей таблице символов. О таблице строк более подробно я расскажу в третьей части этой серии.

from PIL import Image, ImageDraw image = Image.open('test.jpg') # Открываем изображение
draw = ImageDraw.Draw(image) # Создаем инструмент для рисования
width = image.size[0] # Определяем ширину
height = image.size[1] # Определяем высоту
pix = image.load() # Выгружаем значения пикселейdef rep(token,login,date_from,date_to):

Здравствуй, читатель сегодня поговорим о том почему не надо открывать непроверенные файлы скачанные с неизвестных источников и создадим такой файл чтобы понять что он может наделать на вашем ПК. Создавать мы будем стиллер который соберет все наши пароли и отправит их нам по почте.
def memo_square(a, cache={}):
if a not in cache:
cache[a] = a*a
return cache[a]
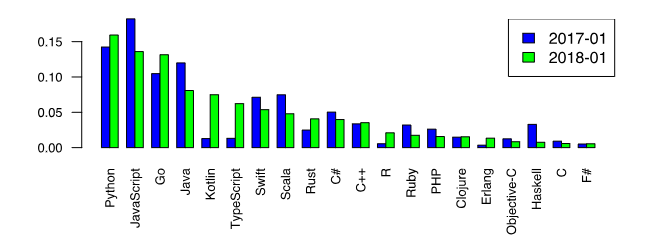
Сегодня в Сети можно найти огромное количество разнородной информации о наиболее востребованных языках программирования, библиотеках, фреймворках, операционных системах и прочих сущностях — назовём их технологиями. Число этих технологий постоянно растёт и становится ясно, что каждому, желающему пойти путём разработчика, необходимо фокусироваться на изучении некоторого наиболее востребованного стека, связанного с какой-либо ключевой технологией.


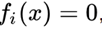 , возвести их в квадрат и сложить.
, возвести их в квадрат и сложить.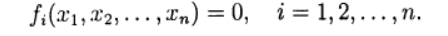 (1)
(1)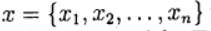 вектор неизвестных и определим вектор-функцию
вектор неизвестных и определим вектор-функцию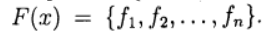 Тогда система (1) записывается в виде уравнения:
Тогда система (1) записывается в виде уравнения: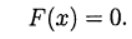 (2)
(2)