Январь 2008 года — Калифорния, США.
Инженер Ян Кум нанимается на работу в Facebook* — получает отказ.
Это был не конец — он продолжил двигаться дальше.
В следующем году он покупает iPhone и сразу же понимает огромный потенциал нового App Store.
С несколькими бывшими коллегами из Yahoo он решает создать программу мгновенного обмена сообщениями. Программе дают имя WhatsApp. Предназначение WhatsApp — стать заменой дорогостоящим SMS.
Рост популярности WhatsApp поражает воображение — каждый день в него заходит один миллион людей.
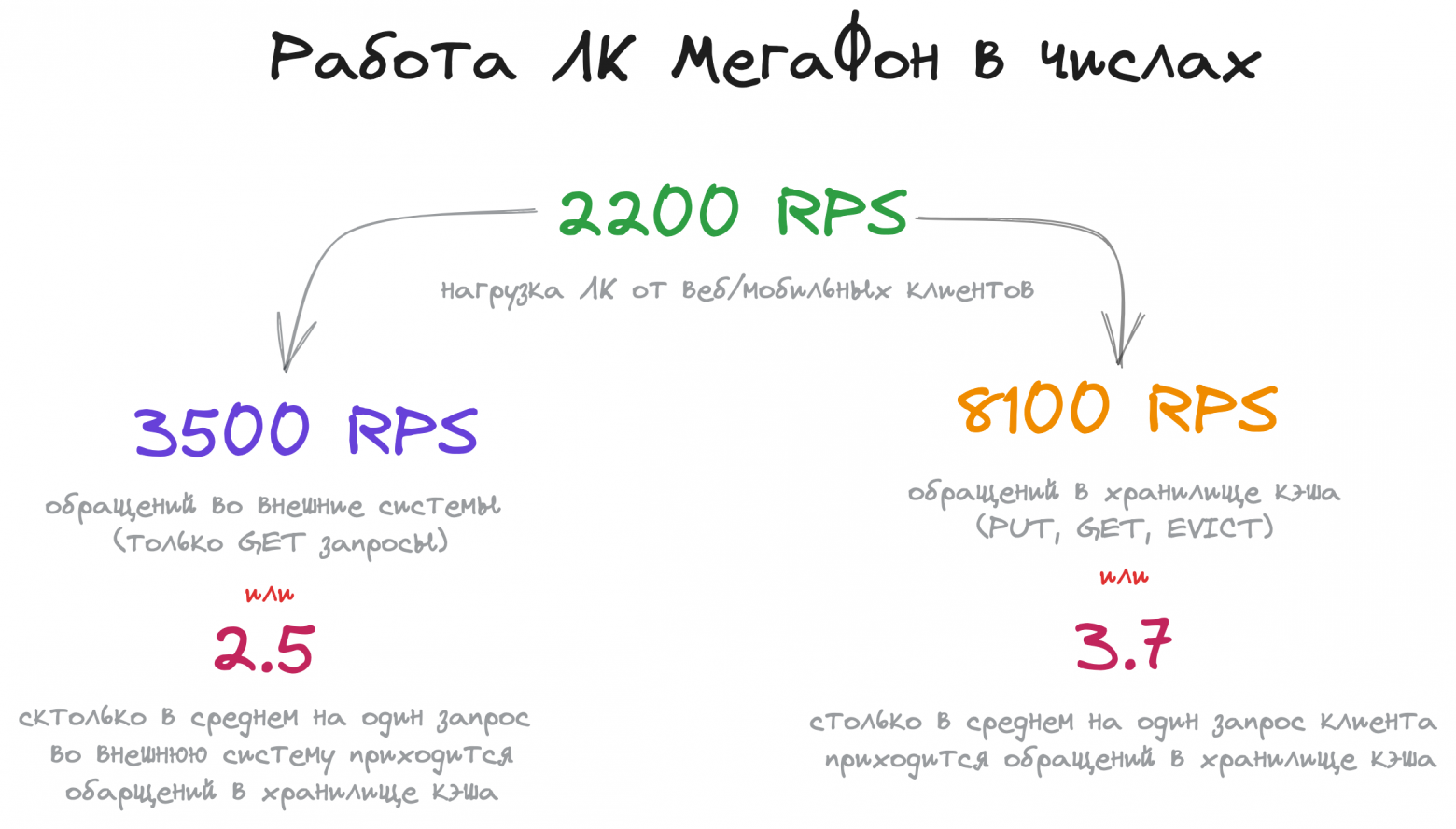
WhatsApp мог справляться с
50 миллиардами сообщений в день от
450 миллионов активных пользователей, имея в штате всего
32 инженера.
Хотя взрывной рост продукта — это приятная проблема, для её решения Яну Куму и команде разработчиков WhatsApp пришлось применить самые передовые технологии проектирования.