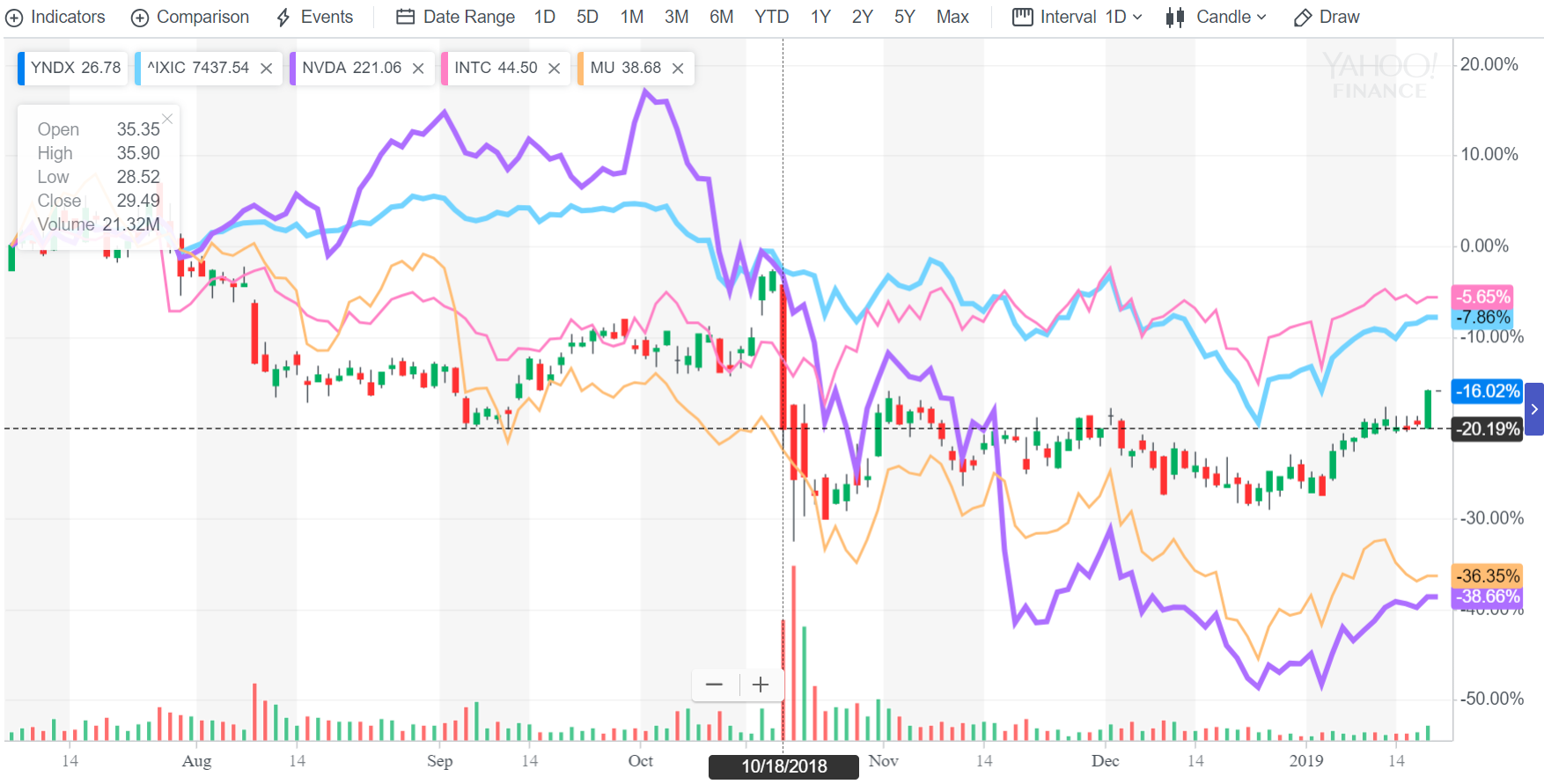
Сегодня не будет никаких сложных кейсов и мудреных алгоритмов на SQL. Все будет очень просто, на уровне Капитана Очевидность — делаем
просмотр реестра событий с сортировкой по времени.
То есть вот лежит в базе табличка
events, а у нее поле
ts — ровно то самое время, по которому мы хотим эти записи упорядоченно показывать:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);
Понятно, что записей у нас там будет не десяток, поэтому нам потребуется в каком-то виде
постраничная навигация.
#0. «Я у мамы погроммист»
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
Даже почти не шутка — редко, но встречается в дикой природе. Иногда после работы с ORM бывает тяжело перестроиться на «прямую» работу с SQL.
Но давайте перейдем к более распространенным и менее очевидным проблемам.







 Реализация инфраструктуры 1С на базе Linux тема древняя, но до сих пор актуальная. Мы недавно публиковали статью
Реализация инфраструктуры 1С на базе Linux тема древняя, но до сих пор актуальная. Мы недавно публиковали статью