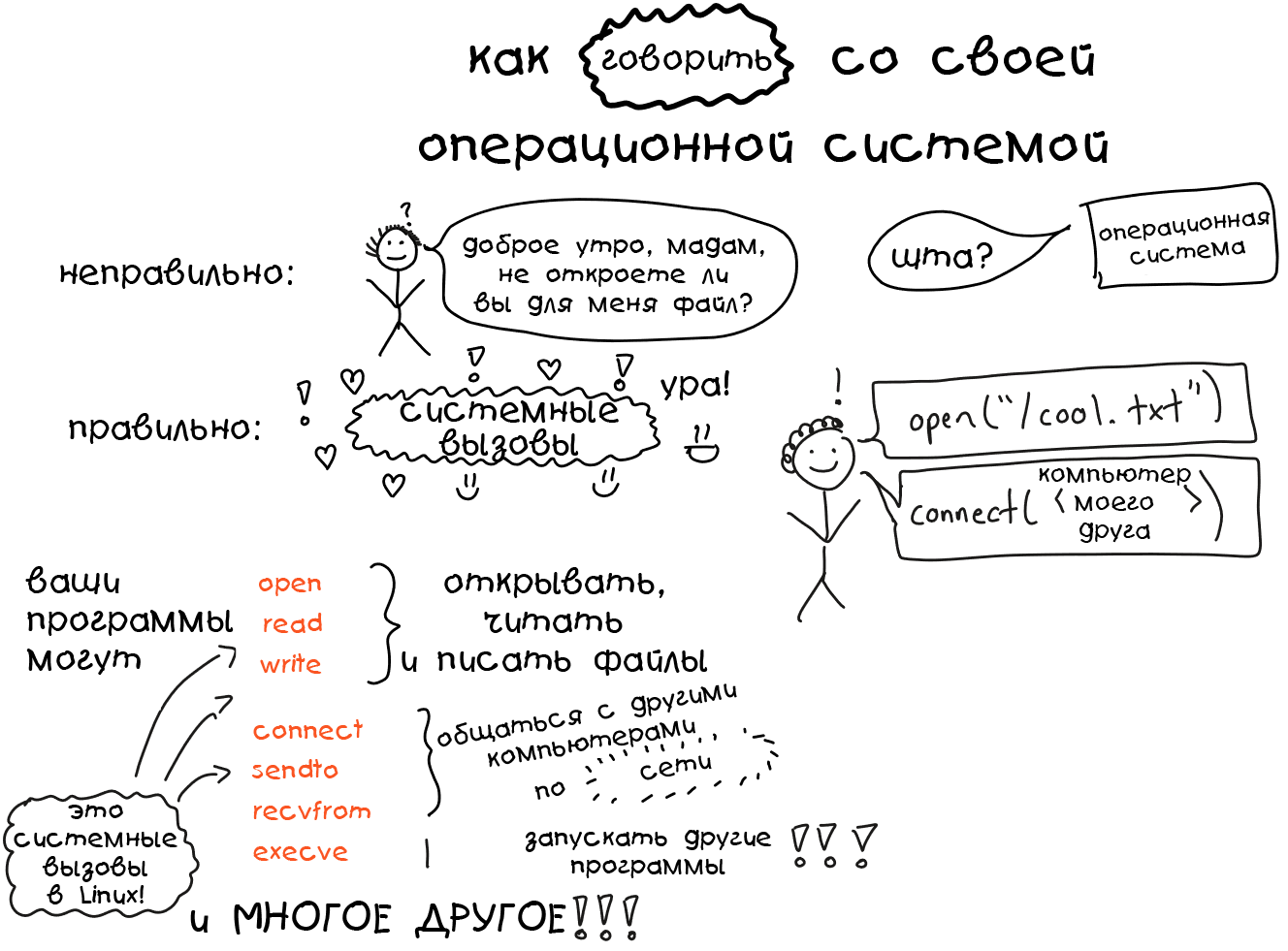
Приветствуем! Мы продолжаем публиковать лекции Стэнфордского университета. Рады представить вторую лекцию курса 2010 г. «Биология поведения человека» профессора Роберта Сапольски.
Мой рекорд скорости написания кода «на C» был в консоли Quake II. Причем абсолютно без ошибок. В темноте, не глядя, трясущимися руками надо было набрать примерно такое:
bind SHIFT "+snipe"
alias +snipe "sensitivity 2.5; fov 30"
alias -snipe "fov 90; sensitivity 4"
Боги умели прописывать RocketJump.
RocketJump
bind t "superrjr"
bind a "superrjn"
alias superrjr "echo SuperRocketJump enabled; bind a +srj; bind t superrjc"
alias superrjn "echo SuperRocketJump disabled"
alias superrjc "echo SuperRocketJump disabled; bind a superrjn; bind t superrjr"
alias +srj "lookdown1;hand 2;rjump"
alias -srj "lookdown2"
alias lookdown1 "cl_pitchspeed 999999;+lookdown"
alias lookdown2 "-lookdown;cl_pitchspeed 200;-attack;-moveup;wait;wait;wait;centerview;hand 2;cl_maxfps 80"
alias rjump "+moveup;+attack;wait;wait;wait;wait;cl_maxfps 0"
alias +QLD "+lookdown;cl_pitchspeed 999"
alias -QLD "-lookdown;cl_pitchspeed 200"
alias +RocketJump "hand 2;+QLD;wait;wait;+attack;+moveup"
alias -RocketJump "hand 2;-QLD;-attack;-moveup"
alias SuperRocketJump "hand 2;+QLD;wait;wait;wait;wait;+attack;+moveup;wait;cl_maxfps 0;LWX3;cl_maxfps 90;-QLD;-attack;-moveup;hand 2"
Под катом — подборка дюжины проектов, которые заточены на то, чтобы играючи повысить кодерское мастерство.
Недавно мы опубликовали перевод журнала про инструменты отладки для Linux, а теперь предлагаем подборку полезных слайдов для начинающих Linuxоводов от того же автора.
Привет, Хабр! Последнее время все больше и больше достижений в области искусственного интеллекта связано с инструментами глубокого обучения или deep learning. Мы решили разобраться, где же можно научиться необходимым навыкам, чтобы стать специалистом в этой области.
Язык — лишь малая часть того, что вам нужно знать. Может быть около 5%, а то и меньше.
Эта статья повторяет и дополняет содержание моего выступления «Что отличает джуниора от сеньора или как питонисту не иметь проблем с поиском работы» на последнем MoscowPython Meetup 39. Многие обращались ко мне после выступления с вопросами и я обещал опубликовать статью на Хабре и обсудить в комментариях.
Под катом вы найдете ответ на тему статьи и немного оффтопа. Имейте ввиду, что эта статья написана мной лично, по моему практическому опыту, так как у меня редко когда-либо возникали трудности с поиском работы. Она может отличаться от опыта других людей и я буду очень рад любым дополнениям и исправлениям, если я в чем-нибудь неправ.
«A change in perspective is worth 80 IQ points»
— Alan Kay
Алан Кей — крутой мужик, мы его на Хабре поздравляли с днюхой.
Напомню заслуги Алана.
Работал в легендарном Xerox PARC, Atari, Apple, Disney, HP.
Предложил концепцию Dynabook (в 1968 году), которая определила концептуальную базу для ноутбука, планшетного компьютера и электронной книги.
Один из «отцов-основателей» объектно-ориентированного программирования (SmallTalk, 1969).
Участвовал в создании первого персонального компьютера Xerox Alto (1973).
Инициатор полезной движухи «Каждому ребенку по ноутбуку».
в 2001 году, он основал исследовательский Институт Viewpoints, некоммерческую организацию посвящённую детям, обучению и передовым разработкам программного обеспечения.
В 2006 бросил дерзкий вызов индустрии — заявил о возможности создания операционной системы с графическим интерфейсом из 20.000 строчек кода.
Решили мы перевести его самую концептуальную статью и тут бац, оказывается, что в оригинальной статье нет куска текста. Написали мы в Viewpoints Research Institute, мол, опечатка у вас. Ответила нам Kim Rose, все объяснила, исправила и благославила.
(Поскольку люди спрашивали: Sublime Text 3 с «Spacegray Light» («платиново-серый светлый») из Materialize и гарнитура Ubuntu Mono Bold)
Как и большинство других студентов, обучавшихся по программе компьютерных наук в Калифорнийском университете в Сан-Диего, я в течение нескольких лет шёл через различные курсы просто «накатом». Я никогда не был ни хорошим, ни плохим по успеваемости, и мой средний балл был «не очень». Я любил курсы программирования с их чрезвычайно сложными заданиями; математический анализ же был мне не по душе.
В этом нетехническом посте я хотел бы (для разнообразия) поделиться моим опытом работы с проектами с открытым исходным кодом. Эти проекты оказали мне огромную помощь в дальнейшем при получении места для стажировки (в т.ч. в Amazon, которое превратилось позднее в постоянное рабочее место).
Если вы сейчас изучаете компьютерные науки или предполагаете делать это, то надеюсь, что вам будет полезен мой опыт.
Один из аспектов профессии разработчика — посвящение профанов в особенности процесса разработки ПО. С. Макконнелл, Совершенный код
Цель этой публикации — поделиться опытом работы над проектом со сложной историей и тяжёлым наследием. После ухода из очередного т.н. «стартапа», я решил что хочу попробовать новых ощущений: enterprise, legacy, etc. Для этого взялся за работу над корпоративным приложением для транснационального концерна. Разработка на тот момент шла уже третий год, приложение пережило несколько поколений разработчиков, но стабильного релиза так и не было.
Полагаю публикация будет полезной:
разработчикам принимающим аналогичное решение, чтобы взвесить за и против
менеджерам «непростых» проектов, чтобы лучше понять причины и следствия технических проблем
и, конечно, просто любопытствующим
Затрагиваемые в статье вопросы:
Низкая компетенция разработчиков, и что с этим можно поделать?
Какие аргументы убедительны в глазах заказчика для нефункциональных изменений в проекте?
Почему работа аналитиков и QA очень важна с точки зрения разработки в частности и для проекта в целом?
Доброго времени суток! Приближается сезон подачи заявок на стажировку в зарубежные компании и поэтому я хотел бы представить вниманию Хабрахабра статью Эрика Янга «How to Get an Internship». Она охватывает довольно большой объем подготовки к стажировке в рамках одного поста. Я старался снизить количество ошибок и опечаток, но таковые наверняка найдутся, поэтому пишите в личные сообщения.
Где-то год назад я написал в блог заметку о моем опыте участия в различных стажировках. Благодаря этому посту я стал заметнее для рекрутеров и устроился на работу в Google.
Я также стал получать много писем на email от студентов, у которых были вопросы по поводу стажировок. Каждый раз, когда я получаю такое письмо, мое эго увеличивается примерно в два раза. Спасибо вам.
В этом посте я поделюсь своей стратегией по прохождению интервью для стажировки. Я давненько хотел написать что-то подобное, но боялся, что пост будет похож на "универсальный ответ", потому что большАя часть моего успеха — это удача.
Этим постом я начну цикл «Нейронные сети для новичков». Он посвящен искусственным нейронным сетям (внезапно). Целью цикла является объяснение данной математической модели. Часто после прочтения подобных статей у меня оставалось чувство недосказанности, недопонимания — НС по-прежнему оставались «черным ящиком» — в общих чертах известно, как они устроены, известно, что делают, известны входные и выходные данные. Но тем не менее полное, всестороннее понимание отсутствует. А современные библиотеки с очень приятными и удобными абстракциями только усиливают ощущение «черного ящика». Не могу сказать, что это однозначно плохо, но и разобраться в используемых инструментах тоже никогда не поздно. Поэтому моей первичной целью является подробное объяснение устройства нейронных сетей так, чтобы абсолютно ни у кого не осталось вопросов об их устройстве; так, чтобы НС не казались волшебством. Так как это не математический трактат, я ограничусь описанием нескольких методов простым языком (но не исключая формул, конечно же), предоставляя поясняющие иллюстрации и примеры.
Цикл рассчитан на базовый ВУЗовский математический уровень читающего. Код будет написан на Python3.5 с numpy 1.11. Список остальных вспомогательных библиотек будет в конце каждого поста. Абсолютно все будет написано с нуля. В качестве подопытного выбрана база MNIST — это черно-белые, центрированные изображения рукописных цифр размером 28*28 пикселей. По-умолчанию, 60000 изображений отмечены для обучения, а 10000 для тестирования. В примерах я не буду изменять распределения по-умолчанию.
В далеком для меня 2010 году я писал статью для начинающих про сокеты в Python. Сейчас этот блог канул в небытие, но статья мне показалась довольно полезной. Статью нашел на флешке в либровском документе, так что это не кросспост, не копипаст — в интернете ее нигде нет.
Что это
Для начала нужно разобраться что такое вообще сокеты и зачем они нам нужны. Как говорит вики, сокет — это программный интерфейс для обеспечения информационного обмена между процессами. Но гораздо важнее не зазубрить определение, а понять суть. Поэтому я тут постараюсь рассказать все как можно подробнее и проще.
Существуют клиентские и серверные сокеты. Вполне легко догадаться что к чему. Серверный сокет прослушивает определенный порт, а клиентский подключается к серверу. После того, как было установлено соединение начинается обмен данными.
Мы продолжаем рассказывать о системе адаптивного обучения на Stepic.org. Первую вводную часть этой серии можно почитать здесь.
В данной статье мы расскажем о построении рекомендательной системы (которая и лежит в основе адаптивности). Расскажем о сборе и обработке пользовательских данных, о графах переходов, хендлерах, оценке реакции пользователя, формировании выдачи.
Вспомним про линейную регрессию, регуляризацию и даже поймём, почему в нашем случае лучше использовать гребневую регрессию, а не какую-нибудь там ещё.
Этот материал будет полезен в первую очередь тем, кто много занимался программированием и вдруг внезапно стал вынужден заниматься управлением проектами и людьми. С год назад я рассказал про наказания на конференции, а солнышки из Битрикса сделали текстовую версию для #habr. К сожалению, потеряв в точности, четкости и правильности акцентов. За год материала добавилось. В конце — чеклист для ленивых :)
Итак. Если вы не садист или моральный урод, а ваши сотрудники — не мазохисты, то сомневаюсь, что кому-то из вас наказания доставляют удовольствие. Мне — нет.
Кажется, не проходит и дня, чтобы на Хабре не появлялись посты о нейронных сетях. Они сделали машинное обучение доступным не только большим компаниям, но и любому человеку, который умеет программировать. Несмотря на то, что всем кажется, будто о нейросетях уже всем все известно, мы решили поделиться обзорной лекцией, прочитанной в рамках Малого ШАДа, рассчитанного на старшеклассников с сильной математической подготовкой.
Материал, рассказанный нашим коллегой Константином Лахманом, обобщает историю развития нейросетей, их основные особенности и принципиальные отличия от других моделей, применяемых в машинном обучении. Также речь пойдёт о конкретных примерах применения нейросетевых технологий и их ближайших перспективах. Лекция будет полезна тем, кому хочется систематизировать у себя в голове все самые важные современные знания о нейронных сетях.
Константин klakhman Лахман закончил МИФИ, работал исследователем в отделе нейронаук НИЦ «Курчатовский институт». В Яндексе занимается нейросетевыми технологиями, используемыми в компьютерном зрении.
Мы собрали интересные лекции, которые помогут понять, как работает машинное обучение, какие задачи решает и что нам в ближайшем будущем ждать от машин, умеющих учиться. Первая лекция рассчитана скорее на тех, кто вообще не понимает, как работает machine learning, в остальных много интересных кейсов.
Всем привет. Хочу сегодня затронуть одну душещипательную тему — почему многие стартапы проваливаются, даже не успев запуститься. В этом году я столкнулся, как минимум, с тремя очень крупными проектами, которые были действительно интересны. Но все они умерли, так и не успев начаться.
Хочу поделиться с вами горячими клавишами, которыми пользуюсь или к которым пытаюсь привыкнуть в своей повседневной работе. В современных средах их количество может просто зашкаливать, но постепенное добавление новых сочетаний в копилку, способно значительно повысить вашу продуктивноть. Приведенные сочетания относятся к редактированию, навигации, рефакторингу и справедливы только для раскладки Default for XWin (Linux).
На StackOverflow часто задают вопросы, подробно освещённые в документации. Ценность их в том, что на некоторые из них кто-нибудь даёт ответ, обладающий гораздо большей степенью ясности и наглядности, чем может себе позволить документация. Этот — один из них.
Вот исходный вопрос:
Как используется ключевое слово yield в Python? Что оно делает?
Например, я пытаюсь понять этот код (**):
def _get_child_candidates(self, distance, min_dist, max_dist):
if self._leftchild and distance - max_dist < self._median:
yield self._leftchild
if self._rightchild and distance + max_dist >= self._median:
yield self._rightchild
Вызывается он так:
result, candidates = list(), [self]
while candidates:
node = candidates.pop()
distance = node._get_dist(obj)
if distance <= max_dist and distance >= min_dist:
result.extend(node._values)
candidates.extend(node._get_child_candidates(distance, min_dist, max_dist))
return result
Что происходит при вызове метода _get_child_candidates? Возвращается список, какой-то элемент? Вызывается ли он снова? Когда последующие вызовы прекращаются?
** Код принадлежит Jochen Schulz (jrschulz), который написал отличную Python-библиотеку для метрических пространств. Вот ссылка на исходники: http://well-adjusted.de/~jrschulz/mspace/