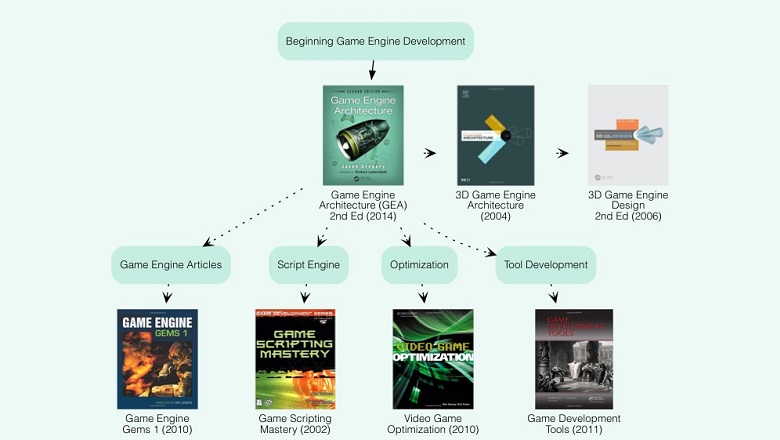
Объём специфичных знаний, которые требуются рядовому программисту игр, даже если он только начал свою карьеру, вызывает у меня «лёгкую» тоску. Это одна из причин, почему большая часть людей, которые «горят делать игры», отсеивается на этапе технических собеседований (обычно их больше одного). Это нормально и грустно. Добавьте сюда, что нефундаментальные знания, вроде инструментов, библиотек и движков, приходится обновлять где‑то раз в 5–7 лет. Не вижу тут, что игрострой сильно отличается от других областей разработки. Если бы лет 15 назад «добрый я» скинул на почту список книг, которые придется прочитать и осмыслить, армия собранных граблей не была бы столь большой и разнообразной, и без ручек половинной длины. Осторожно, в конце статьи будет супердлинная картинка (взята с github отсюда, с разрешения автора).