
Мы русифицировали Mistral и он работает лучше(по бенчмаркам) чем закрытые русскоязычные LLM. Как мы это сделали, ссылки на модели и бенчмарки - в статье.

Аналитик данных
Мы русифицировали Mistral и он работает лучше(по бенчмаркам) чем закрытые русскоязычные LLM. Как мы это сделали, ссылки на модели и бенчмарки - в статье.
Довольно часто программисты и специалисты из области data science сталкиваются с задачей поиска похожих профилей пользователей или подбора схожей музыки. Решения могут сводиться к преобразованию объектов в векторную форму и поиску ближайших.
Мы тоже столкнулись с необходимостью поиска ближайших соседей в задаче распознавания лиц. Там мы формируем векторные представления лиц при помощи нейросети и ищем ближайшие векторы уже известных людей. Изначально для поиска мы выбрали Annoy, как хорошо известный и проверенный алгоритм, используемый в том числе в Spotify. Но быстро поняли, что с его аппетитами по памяти мы либо не вмещаемся в RAM, либо сильно теряем в точности. Это привело к небольшому исследованию. О результатах которого пойдет речь ниже.

В ходе работы над проектами бизнес-аналитик сталкивается с различными маркетинговыми явлениями. Часть из них воспринимается однозначно или достаточно близко друг к другу даже в разных предметных областях, однако есть и такие, подход к анализу которых отличается от отрасли к отрасли. Эффект каннибализации – одно из таких многогранных явлений. О нем и пойдет речь в статье. Сразу оговорюсь, что материал в большей степени будет интересен начинающим аналитикам в сфере банковского маркетинга и информационных технологий ввиду специфики данных отраслей. Тем не менее описанный взгляд на эффект каннибализации может быть полезен и для специалистов других сфер деятельности.
Эффект каннибализации, на первый взгляд, в различных источниках определяется однозначно: как сокращение объема продаж одного продукта компании за счет вывода на рынок другого продукта. Однако, изучая причины возникновения и отношение компаний к данному процессу, становится очевидно, что в практической деятельности присутствуют расхождения в его понимании и, как следствие, методологии анализа.
В статье я попробую агрегировать имеющуюся на текущий момент теоретическую информацию об эффекте каннибализации с целью формирования у читателя, неравнодушного к теме, комплексного понимания данного явления. Но сначала представлюсь: меня зовут Наталья Столбецова, работаю старшим бизнес-аналитиком в GlowByte. Основная моя специализация – автоматизация задач целевого маркетинга. В моем портфолио есть опыт работы как на проектах банковского маркетинга, так и ритейла. И я сама не раз на проектах сталкивалась с тем, что при проведении исследований существует конфликт терминологий и понимания бизнес-процессов, в том числе эффекта каннибализации.
Данная статья открывает цикл, посвященный розничной торговле. Идею использования аналитики в ритейле можно изобразить в виде вот такого маркетингового круга:
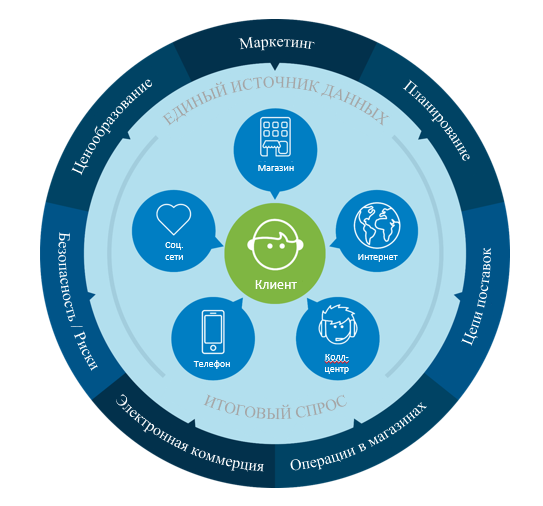
Основная идея, на первый взгляд, бесполезной картинки – показать, что аналитика позволяет предсказать последствия принятия тех или иных бизнес решений, основываясь на последующем изменении покупательского спроса. И чем лучше мы понимаем спрос, агрегируя информацию из разных каналов, тем лучше мы будем предсказывать результат. Короче говоря, картинка идеального мира, и каждый идет к этому миру своим путем.
Сегодня речь пойдет об аналитике ценообразования в офлайн ритейле.

В октябре прошлого года мы выпустили SAGE — библиотеку для генеративной коррекции орфографии, которая включает в себя семейство предобученных трансформерных моделей, хаб с параллельными вручную размеченными датасетами и два алгоритма текстовой аугментации на основе намеренного искажения правописания.
С момента прошлого релиза мы улучшили качество наших моделей более чем на 10%, добавили правку знаков пунктуации и регистра, провели эксперименты по сжатию и ускорению полученных решений, добавили разметку пунктуации в датасеты и новые метрики в библиотеку, а нашу статью взяли на EACL 2024 в Мальте.

Обретите цифрового двойника
Цель этой статьи - показать, как эффективно и с минимальными затратами настроить LLM на пользовательском датасет. Мы рассмотрим использование модели Falcon-7B с адаптерами LoRa, с использованием библиотеки Lit-GPT.

На сегодняшний день созданы разные большие языковые модели (LLM), которые показывают превосходные результаты, но для раскрытия их полного потенциала необходимо дообучение для точного решения конкретных задач. Традиционный метод файнтюнинга, при котором настраиваются все параметры предварительно обученной модели, становится непрактичным и вычислительно дорогостоящим при работе с современными моделями LLM.
PEFT(Parameter-Efficient Fine-Tuning) представляет собой эффективный подход, позволяющий не терять производительность при тонкой настройке модели, снижая при этом требования к памяти и вычислительным мощностям.
В этой статье мы рассмотрим общую концепцию PEFT, его преимущества и основные методы.

Инференсом ML-модели называют процесс её работы на конечном устройстве. Соответственно, чем больше мы разгоняем инференс, тем быстрее работает модель. Скорость может зависеть от разных условий, например, от архитектуры, которую вы выбрали для модели, или от железа, на котором работает устройство. Кроме того, проблема тяжёлого инференса остро ощущается на больших языковых моделях (LLM) так остро, как ни на каких других моделях.
Меня зовут Роман Горб, я старший ML-разработчик в команде YandexGPT. Тема инференса LLM заинтересовала меня, потому что я занимался R&D в квантовании сеток для CV-задач. Сегодня я расскажу, как безболезненно увеличить скорость инференса. Сперва разберёмся, зачем это нужно, а потом рассмотрим разные методы ускорения и фреймворки, которые могут в этом помочь.

С момента выхода первой статьи «Attention is All You Need» я с жадностью и любопытством, присущими любому исследователю, пытаюсь углубиться во все особенности и свойства моделей на базе архитектуры трансформер. Но, если честно, я до сих пор не понимаю, как они работают и почему так хорошо обучаются. Очень хочу разобраться, в чём же причина такой эффективности этих моделей, и есть ли предел их возможностей?
Такому изучению трансформеров «под микроскопом» и посвящена наша научная работа, только что представленная на конференции EACL 2024, которая проходила на Мальте — «The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models». В этой работе мы сфокусировались на наблюдении за пространством эмбеддингов (активаций) на промежуточных слоях по мере обучения больших и маленьких языковых моделей (LM).
С момента выхода оригинальной статьи про трансформер прошло уже больше 7 лет, и эта архитектура перевернула весь DL: начав с NLP архитектура теперь применяется везде, включая генерацию картинок. Но та ли это архитектура или уже нет? В этой статье я хотел сделать краткий обзор основных изменений, которые используются в текущих версиях моделей Mistral, Llama и им подобным.

Мы команда data science Ozon fresh. В этой статье мы расскажем об одной из наших задач - алгоритм, который помогает управлять нашим огромным ассортиментом.
Ozon fresh — это сервис быстрой доставки продуктов, бакалеи, бытовой техники, электроники и других товаров. В нашем ассортименте более 35 000 уникальных позиций (готовая еда, мясо, рыба, фрукты, овощи, товары для гигиены и многое другое). Специфика Ozon fresh заключается в мини-складах, где хранятся товары. Они доставляются клиентам в радиусе нескольких километров.
Управление таким количеством позиций требует много человеческих и технологических ресурсов. У нас этим занимаются более 30 человек. Для упрощения работы мы используем различные группировки товарных позиций. Самая популярная — иерархическая четырёхуровневая группировка (далее мы будем называть её «категорийное дерево»).

Привет, меня зовут Александр Егоров, я MLOps инженер. В статье расскажу о том, как мы в банке выкатываем огромное количество моделей. Разберём не только пайплайн по выкладке отдельных моделей, но и целые каскады.

Привет! Меня зовут Василий Землянов, я занимаюсь разработкой ML-инфраструктуры. Несколько лет я проработал в команде, которая делает споттер — специальную маленькую нейросетевую модельку, которая живёт в умных колонках Яндекса и ждёт от пользователя слова «Алиса». Одной из моих задач в этой команде была квантизация моделей. На пользовательских устройствах мало ресурсов, и мы решили, что за счёт квантизации сможем их сэкономить — так в итоге и вышло.
Потом я перешёл в команду YandexGPT. Вместо маленьких моделей я стал работать с очень крупными. Мне стало интересно, как устроена квантизация больших языковых моделей (LLM). Ещё меня очень впечатляли истории, где люди берут гигантские нейросети, квантизируют в 4 бита и умудряются запускать их на ноутбуках. Я решил разобраться, как это делается, и собрал материал на доклад для коллег и друзей. А потом пришла мысль поделиться знаниями с более широкой аудиторией, оформив их в статью. Так я и оказался на Хабре :)
Надеюсь, погружение в тему квантизации будет интересно как специалистам, так и энтузиастам в сфере обучения нейросетей. Я постарался написать статью, которую хотел бы прочитать сам, когда только начинал изучать, как заставить модели работать эффективнее. В ней мы подробно разберём, зачем нужна квантизация и в какой момент лучше всего квантизовать модель, а ещё рассмотрим разные типы данных и современные методы квантизации.
Ежемесячная аудитория ОК только в России превышает 36 млн человек. Причём это активные пользователи, которые хорошо взаимодействуют с нашим контентом: ставят Классы, комментируют, делают репосты. Залогом активного отклика во многом является формирование новостной ленты с учетом предпочтений каждого конкретного пользователя.
Меня зовут Дмитрий Решетников. Я тимлид команды рекомендаций в Ленте ОК. В этой статье я расскажу, как выглядит наш пайплайн рекомендации в ленте новостей, о месте item2vec в нём и результатах внедрения такого подхода.
Кластеризация — это набор методов без учителя для группировки данных по определённым критериям в так называемые кластеры, что позволяет выявлять сходства и различия между объектами, а также упрощать их анализ и визуализацию. Из-за частичного сходства в постановке задач с классификацией кластеризацию ещё называют unsupervised classification.
В данной статье описан не только принцип работы популярных алгоритмов кластеризации от простых к более продвинутым, но а также представлены их упрощённые реализации с нуля на Python, отражающие основную идею. Помимо этого, в конце каждого раздела указаны дополнительные источники для более глубокого ознакомления.


Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

Разносторонний системный рассказ о том, какими способами можно научить модель работать с длинными последовательностями. Для специалистов, занимающихся обучением LLM, и всех, кто хочет разобраться в теме.
