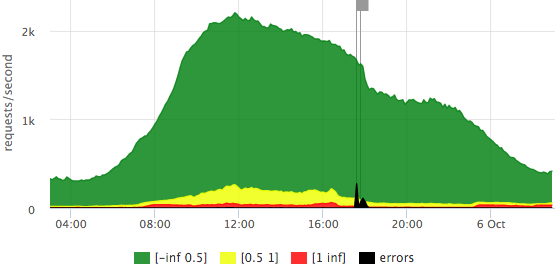
Как-то я посчитал, что 1 минута простоя hh.ru в будни днем затрагивает около 30 000 пользователей. Мы постоянно решаем задачу снижения количества инцидентов и их длительности. Снизить количество проблем мы можем правильной инфраструктурой, архитектурой приложения — это отдельная тема, ее мы пока не будем брать во внимание. Поговорим лучше о том, как быстро понять, что происходит в нашей инфраструктуре. Тут как раз нам и помогает мониторинг.
В этой статье на примере hh.ru я расскажу и покажу, как покрыть мониторингом все слои инфраструктуры:
- client-side метрики
- метрики с фронтендов (логи nginx)
- сеть (что можно добыть из TCP)
- приложение (логи)
- метрики базы данных (postgresql в нашем случае)
- операционная система (cpu usage тоже может пригодиться)