Биткойн и другие криптовалюты захватили внимание огромного количества людей. Почему бы не воспользоваться этим шансом для популяризации математики и, в частности, Mathcad? В этой статье мы рассмотрим несколько простых широко известных моделей на основе дифференциальных уравнений, а именно, семейства логистических моделей (неограниченного роста, с конкуренцией за ресурс, с промыслом и запаздыванием). Впервые системный фактор, ограничивающий рост биологической популяции, предложил бельгийский математик Ферхюльст, поэтому соответствующая модель (она будет рассмотрена второй по счету) по праву носит его имя.
Поскольку все, что происходит в последнее время с с биткойном, похоже на пирамиду, то и модели будут соответствующие, тем более, что математическому аппарату, благодаря МММ, уже в разное время посвящало свои статьи множество коллег, например, М.Баландин и В.Очков. Основное внимание, как и раньше, мы уделим приемам расчетов в Mathcad, в особенности, в его бесплатной версии Mathcad Express, не настаивая на точности прогноза, каким будет курс биткойна в ближайшее время, и когда именно он рухнет.
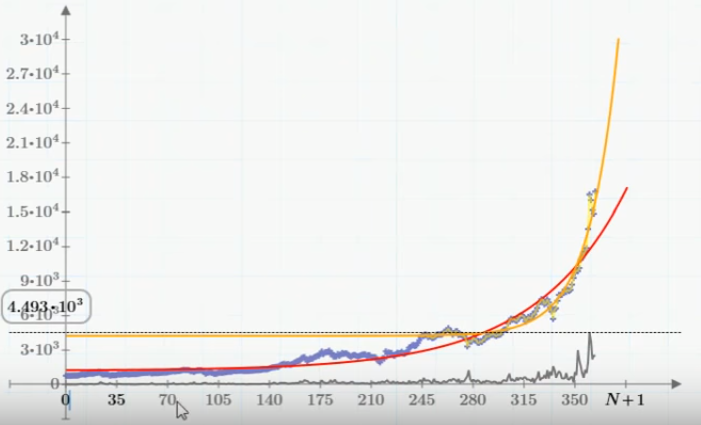
Поскольку все, что происходит в последнее время с с биткойном, похоже на пирамиду, то и модели будут соответствующие, тем более, что математическому аппарату, благодаря МММ, уже в разное время посвящало свои статьи множество коллег, например, М.Баландин и В.Очков. Основное внимание, как и раньше, мы уделим приемам расчетов в Mathcad, в особенности, в его бесплатной версии Mathcad Express, не настаивая на точности прогноза, каким будет курс биткойна в ближайшее время, и когда именно он рухнет.