Привет, Хабр!
Сегодня я хочу рассказать о нашем опыте автоматизации резервного копирования больших данных хранилищ Nextcloud в разных конфигурациях. Я работаю СТО в «Молния АК», где мы занимаемся конфигурационным управлением IT систем, для хранения данных используется Nextcloud. В том числе, с распределенной структурой, с резервированием.
Проблемы вытекающие из особенностей инсталляций в том, что данных много. Версионирование которое дает Nextcloud, резервирование, субъективные причины, и другое создает много дублей.
Предыстория
При администрировании Nextcloud остро встает проблема организации эффективного бэкапа который нужно обязательно шифровать, так как данные ценны.
Мы предлагаем варианты хранения бэкапа у нас или у заказчика на его отдельных от Nextcloud машинах, что требует гибкого автоматизированного подхода к администрированию.
Клиентов много, все они с разными конфигурациями, и все на своих площадках и со своими особенностями. Тут стандартная методика когда вся площадка принадлежит тебе, и бэкапы делаются из крона подходит плохо.
Для начала посмотрим на вводные данные. Нам нужно:
- Масштабируемость в плане одна нода или несколько. Для крупных исталляций мы используем в качестве хранилища minio.
- Узнавать о проблемах с выполнением бэкапа.
- Нужно хранить бэкап у клиентов и/или у нас.
- Быстро и легко разбираться с проблемами.
- Клиенты и установки сильно отличаются один от другого — единообразия добиться не получается.
- Скорость восстановления должна быть минимальна по двум сценариям: полное восстановление (дизастер), одна папка — стерто по ошибке.
- Обязательна функция дедупликации.
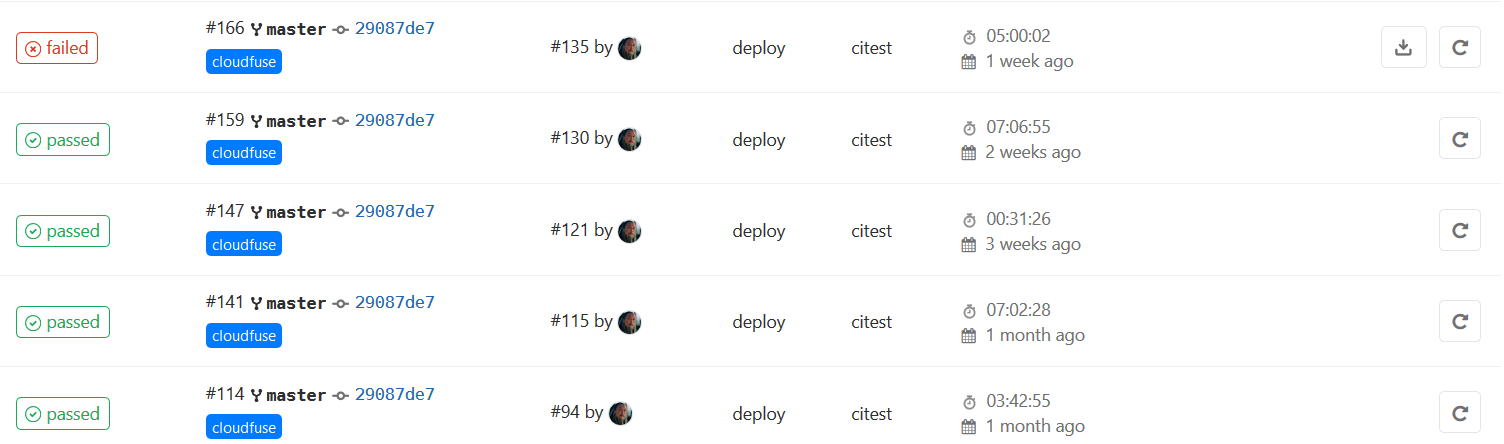
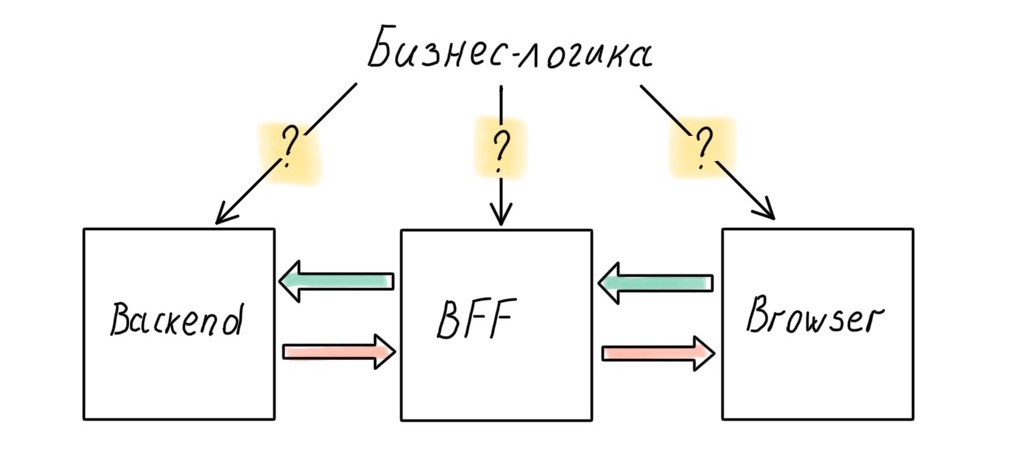
Для решения задачи управления бекапами мы прикрутили GitLab. Подробнее подкатом.












{kind=link}