В этой статье я опишу что из себя представляет технология доступа в Интернет IPoE, которой на самом деле не существует. А также расскажу про схему Client-VLAN и про опцию 82 DHCP (DHCP Option 82), которые стали неотъемлемой частью этой несуществующей технологии. Все это, конечно же, с технической точки зрения и с примерами конфигов.

Y @Sinka
Пользователь
Миф о бесполезности QoS без перегрузки сети
5 мин
По работе я несколько раз сталкивался с мнением, что настраивать QoS в не перегруженной ethernet сети не нужно для успешного функционирования таких сервисов, как IPTV и VoIP. Это мнение стоило мне и моим коллегам многих нервных клеток и часов на диагностику фантомных проблем, поэтом постараюсь как можно проще рассказать о том, почему это мнение неверно.
Большие данные мертвы. Это нужно принять
Средний
17 мин
Мнение
Перевод
Уже более десяти лет тот факт, что люди с трудом извлекают из своих данных полезную информацию, сбрасывают на чересчур большой размер этих данных. «Объем собираемой информации слишком велик для ваших хилых систем», — такой нам ставили диагноз. А лекарство, соответственно, заключалось в том, чтобы купить какую‑нибудь новую причудливую технологию, которая сможет работать в больших масштабах. Конечно, после того, как целевая группа по Big Data покупала новые инструменты и мигрировала с устаревших систем, компании снова обнаруживали, что у них по‑прежнему возникают проблемы с пониманием своих данных.
В результате постепенно некоторые начинали понимать, что размер данных вообще не был проблемой.
Мир в 2023 году выглядит иначе, чем когда зазвенели первые тревожные звоночки по поводу Big Data. Катаклизм обработки информации, который все предсказывали, не состоялся. Объемы данных, возможно, немного возросли, но возможности аппаратного обеспечения росли еще быстрее. Поставщики услуг все еще продвигают свои возможности масштабирования, но люди, которые сталкиваются с ними на практике, начинают задаваться вопросом, как они вообще связаны с их реальными проблемами.
А дальше будет и того интереснее.
KVM: Что такое Kernel-based Virtual Machine?
Средний
17 мин
Начнем с простого вопроса:
Что означает QEMU/KVM или QEMU-KVM?
Можно ответить - это QEMU + KVM или qemu-system, запущенный с kvm в качестве ускорителя. Но в какой-то степени это еще и анахронизм, так как с появлением KVM его разработчики для интеграции с QEMU поддерживали отдельный форк qemu-kvm, но начиная с QEMU версии 1.3 (декабрь 2012) все основные изменения из qemu-kvm были перенесены в главную ветку QEMU, а qemu-kvm объявлен устаревшим.
В разных дистрибутивах до сих пор еще можно встретить исполняемый файл qemu-kvm или просто kvm, но это лишь обертки над qemu-system:
exec qemu-system-x86_64 -enable-kvm "$@"
или симлинки:
/usr/bin/kvm -> qemu-system-x86_64
А в самом qemu существует проверка:
Telegram Bot с подключением OpenAI GPT-3.5-turbo
Простой
4 мин

Поскольку мир становится все более цифровым, люди постоянно ищут новые способы общения друг с другом. Одним из самых популярных приложений для обмена сообщениями сегодня является Telegram, который позволяет пользователям отправлять друг другу сообщения, фотографии и видео. Но что, если бы вы могли делать больше, чем просто отправлять сообщения? Что, если бы вы могли поговорить с ботом, который использует искусственный интеллект, чтобы понимать ваши сообщения и отвечать на них?
Это именно то, что я намеревался сделать, когда создавал телеграмм-бота ChatGPT. Этот бот использует OpenAI GPT-3.5, чтобы предоставить пользователям более естественный и похожий на человеческий опыт общения. Но я не остановился на достигнутом. Я также включил контекст, рисование ИИ и парсинг Google, чтобы сделать бота еще более мощным и универсальным.
Как создать CDN в отдельно взятой стране
10 мин

Тема задержки доступа и скорости извлечения сетевых ресурсов никогда не перестанет быть актуальной. Максимально близкое расположение источника влияет не только на скорость загрузки и пользовательский опыт, но и на эффективность работы глобальной сети в целом, поскольку позволяет локализовать трафик и сократить загрузку магистральных каналов, предпочитая использовать кэшированные или расположенные локально реплики сетевых ресурсов. Не случайно Google реализует модель сохранения локальных кэшей на оборудовании крупных региональных провайдеров (Google Global Cache) и интеллектуальные алгоритмы в маршрутизации на ближайшую реплики. В этой статье мы обсудим различные подходы к реализации распределенной сети доставки контента (Content Delivery Network, он же CDN), а также акцентируем возможные решения для создания CDN в масштабах отдельно взятой страны или города.
Тюнинг сетевого стека Linux для ленивых (v2.5.0)
2 мин
Представлен выпуск проекта netutils-linux 2.5.0, набора утилит для мониторинга и тюнинга производительности сетевого стека Linux. Всё написано на Python (поддерживаются python 2.6+ и 3.4+) и доступно под MIT-лицензией.
Цель проекта — упростить и унифицировать процесс тюнинга сетевого стека и сетевых карт, снизив необходимость разбираться в устройстве сетевого стека для сисадминов и освободить их головы от рутинных вычислений и написания с нуля кучи одинаковых bash-скриптов.
Рекомендации для использования — наличие канала с 200+ Мбит/с, обрабатываемого Linux-based машиной, и требований к минимизации задержек и потерь.
С прошлого (и первого) публичного релиза было исправлено несколько неприятных ошибок, связанных с совместимостью с архитектурами, дистрибутивами Linux, версиями Python и зависимостей проекта, приводивших к невозможностям запуска некоторых утилит.
Обучаемый Telegram чат-бот с ИИ в 30 строчек кода на Python
6 мин
Туториал

Сегодня мне в голову пришла мысль: «А почему бы не написать Telegram чат-бота с ИИ, которого потом можно будет обучать?»
Занимательная 40-гигабитность
5 мин

Мой самый первый пост, который я три года назад написал на Хабр, был посвящен 10G Ethernet и 10G сетевым картам Intel, что, в принципе, не случайно, ведь сетевые технологии – это моя профессия. Далее посты на данную тему почти не появлялись в блоге Intel – как говорится, не было повода. И вот теперь он появился, и вполне весомый. Ведь выход нового поколения сетевых карт Intel на контроллере X/XL710 принес с собой не только улучшение характеристик и новые возможности, но и появление принципиально нового для компании продукта – 40G Ethernet сетевых карт для серверов. Самое время поговорить о текущей ситуации в области 40-гигабитности.
Использование python библиотеки Exscript для работы с оборудованием Cisco и Huawei по SSH
2 мин
В работе Python приложения встала задача получать данные с сетевого оборудования и проводить его настройки удалённо, по SSH. Можно воспользоваться Paramiko, а можно не выдумывать велосипед и использовать основанную на нём библиотеку Exscript. Под катом — примеры кода для подключения и получения информации из команд. Ввиду отсутствия документации к Exscript этот материал может кому-нибудь здорово пригодиться.

Tracert vs Traceroute
5 мин
В чем отличие маршрута пакета от его пути?
Стандартный механизм маршрутизации пакетов в интернете — per hop behavior — то есть каждый узел в сети принимает решение куда ему отправить пакет на основе информации, полученной от протоколов динамической маршрутизации и статически указанных администраторами маршрутов.
Маршрут — это интерфейс, в который нам надо послать пакет для достижения какого то узла назначения и адрес следующего маршрутизатора (next-hop):
Что такое путь? Путь — это список узлов, через которые прошел (пройдет) пакет:
Путь пакета можно посмотреть с помощью утилит tracert в OC Windows и traceroute в GNU/Linux и Unix-подобных системах. (другие команды, типа tracepath мы не рассматриваем).
Многие считают что этих утилит один и тот же принцип работы, но это не так. Давайте разберемся.
Стандартный механизм маршрутизации пакетов в интернете — per hop behavior — то есть каждый узел в сети принимает решение куда ему отправить пакет на основе информации, полученной от протоколов динамической маршрутизации и статически указанных администраторами маршрутов.
Маршрут — это интерфейс, в который нам надо послать пакет для достижения какого то узла назначения и адрес следующего маршрутизатора (next-hop):
R1#sh ip rou | i 40.
40.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
O 40.0.0.0/31 [110/3] via 20.0.0.0, 00:01:54, FastEthernet0/0
O 40.1.1.1/32 [110/4] via 20.0.0.0, 00:00:05, FastEthernet0/0
Что такое путь? Путь — это список узлов, через которые прошел (пройдет) пакет:
1 10.0.0.1 16.616 ms 16.270 ms 15.929 ms
2 20.0.0.0 15.678 ms 15.157 ms 15.071 ms
3 30.0.0.1 26.423 ms 26.081 ms 26.744 ms
4 40.0.0.0 48.979 ms 48.674 ms 48.384 ms
5 100.0.0.2 58.707 ms 58.773 ms 58.536 ms
Путь пакета можно посмотреть с помощью утилит tracert в OC Windows и traceroute в GNU/Linux и Unix-подобных системах. (другие команды, типа tracepath мы не рассматриваем).
Многие считают что этих утилит один и тот же принцип работы, но это не так. Давайте разберемся.
Traceroute: про умение читать вывод
4 мин
- Почему в трейсроуте после узла X идут звездочки?
- Сервис не работает, а трейсроут обрывается на узле X — значит проблема в узле X?
- Почему одинаковые трейсроуты с Windows и Unix показывают разные результаты?
- Почему трейсроут показывает большие задержки на определенном узле?
- Почему трейсроут показывает «серые» адреса при трассировке через интернет?
- Почему маршрутизатор отвечает на трейсроут не тем адресом, каким я хочу?
- Почему трейсроут показывает какие-то «не такие» доменные имена?
- Почему вообще вывод трейсроута отличается от интуитивно ожидаемого чаще, чем хотелось бы?
Сетевые инженеры и администраторы в отношениях с трейсроутом делятся на две категории: регулярно задающие себе и окружающим эти вопросы и заколебавшиеся на них отвечать.
Сей топик не дает ответов на вышепоставленные вопросы. Или почти не дает. Но предлагает подумать, нужно ли их вообще задавать, и если да, то когда и кому.
FDB-таблицы коммутаторов. Приключения в зоопарке. Часть 1 — SNMP
5 мин
В течении многих лет мы, ввиду специфики работы, постоянно сталкиваемся с необходимостью съема FDB-таблиц (Forwarding DataBase) управляемых коммутаторов с данными о коммутации MAC-адресов абонентов и устройств. За это время мимо нас прошли несколько сотен различных моделей устройств многих производителей, а количество версий их прошивок сложно сосчитать. Накопив опыт – можно им и поделиться.
В данном случае затронем лишь тему съема требуемых данных по SNMP-протоколу.
Заранее отмечу, что мы не лоббируем и не стараемся принизить какого-то вендора или модель. Приведённые для примера модели указаны в информационных целях и были в момент написания статьи под рукой.
В данном случае затронем лишь тему съема требуемых данных по SNMP-протоколу.
Заранее отмечу, что мы не лоббируем и не стараемся принизить какого-то вендора или модель. Приведённые для примера модели указаны в информационных целях и были в момент написания статьи под рукой.
Обновление Cumulus Linux до 2.5
3 мин

В мире компьютерного железа традиционно принято подгадывать обновления продуктов так, чтобы их появление на рынке совпадало с весенним или осенним всплеском продаж. А вот в мире ПО такого нет — тут новые версии и обновления приходят равномерно в любое время года.
Так, компания Cumulus Networks решила представить обновление своей операционной системы Cumulus Linux до версии 2.5 буквально пару дней назад, 19 января.
Вкратце напомним, что Cumulus Linux — это одна из сетевых ОС, предназначенная для установки на совместимые коммутаторы с загрузочной средой ONIE (Bare Metal Switch). Мы уже довольно много писали о возможностях этой ОС, поскольку считаем концепцию «BMS+открытая ОС» весьма перспективным направлением развития сетевой инфраструктуры с точки зрения стоимости итогового решения, совместимости и предоставляемых возможностей.
Интересно, что появилось в новой версии? Тогда добро пожаловать под кат.
Почему по мере заполнения SSD падает скорость записи в RAID, или зачем нужен TRIM
7 мин
Эта проблема наиболее актуальна для аппаратных RAID или firmware RAID (таких как Intel RST RAID 1/10/5/6) с непромышленными SSD.
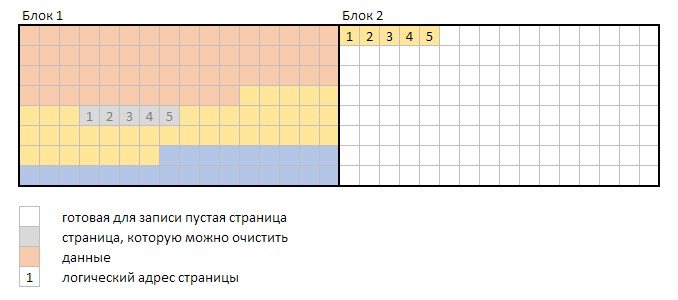
SSD пишут и читают данные страницами, записать можно только на очищенные страницы, а очистить страницы можно только большими блоками. Например, у диска размер страницы 8 КБ, в блоке находится 128 страниц, таким образом, размер блока — 1024 КБ (здесь и далее, если не указано иного, КБ и МБ двоичные).
Например, если изменить 40 КБ в одном файле, то на физическом уровне это будет выглядеть так:
Особенность SSD
SSD пишут и читают данные страницами, записать можно только на очищенные страницы, а очистить страницы можно только большими блоками. Например, у диска размер страницы 8 КБ, в блоке находится 128 страниц, таким образом, размер блока — 1024 КБ (здесь и далее, если не указано иного, КБ и МБ двоичные).
Например, если изменить 40 КБ в одном файле, то на физическом уровне это будет выглядеть так:
Контроль исправности сервера под управлением гипервизора VMware vSphere ESXi v5
2 мин
Туториал
Встала необходимость организовать мониторинг исправной работы контроллеров семейства LSI MegaRAID на серверах, работающих под управлением гипервизора VMware vSphere ESXi v5.5. И соответственно автоматически получать уведомления при наличии какого-либо сбоя, например отказе одного из HDD. В процессе проработки оказалось, что найденное решение не ограничивается только хранилищами данных гипервизора.
SSD + raid0 — не всё так просто
6 мин
Вступление
Коллеги с соседнего отдела (UCDN) обратились с довольно интересной и неожиданной проблемой: при тестировании raid0 на большом числе SSD, производительность менялась вот таким вот печальным образом:
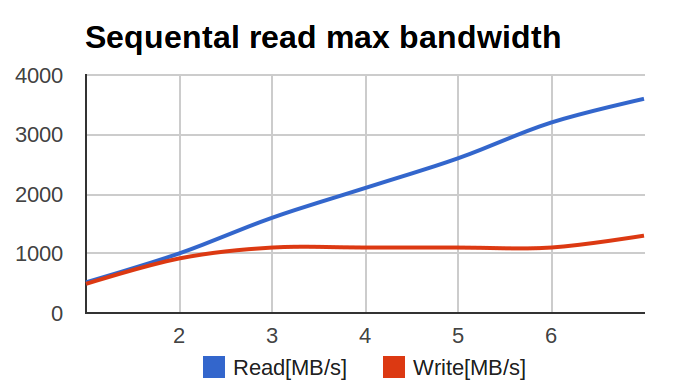
По оси X — число дисков в массиве, по оси Y — мегабайтов в секунду.
Я начал изучать проблему. Первичный диагноз был простой — аппаратный рейд не справился с большим числом SSD и упёрся в свой собственный потолок по производительности.
После того, как аппаратный рейд выкинули и на его место поставили HBA, а диски собрали в raid0 с помощью linux-raid (его часто называют 'mdadm' по названию утилиты командной строки), ситуация улучшилась. Но не прошла полностью -цифры возросли, но всё ещё были ниже рассчётных. При этом ключевым параметром были не IOPS'ы, а многопоточная линейная запись (то есть большие куски данных, записываемых в случайные места).
Ситуация для меня была необычной — я никогда не гонялся за чистым bandwidth рейдов. IOPS'ы — наше всё. А тут — надо многомногомного в секунду и побольше.
Адские графики
Я начал с определения baseline, то есть производительности единичного диска. Делал я это, скорее, для очистки совести.
Вот график линейного чтения с одной SSD.
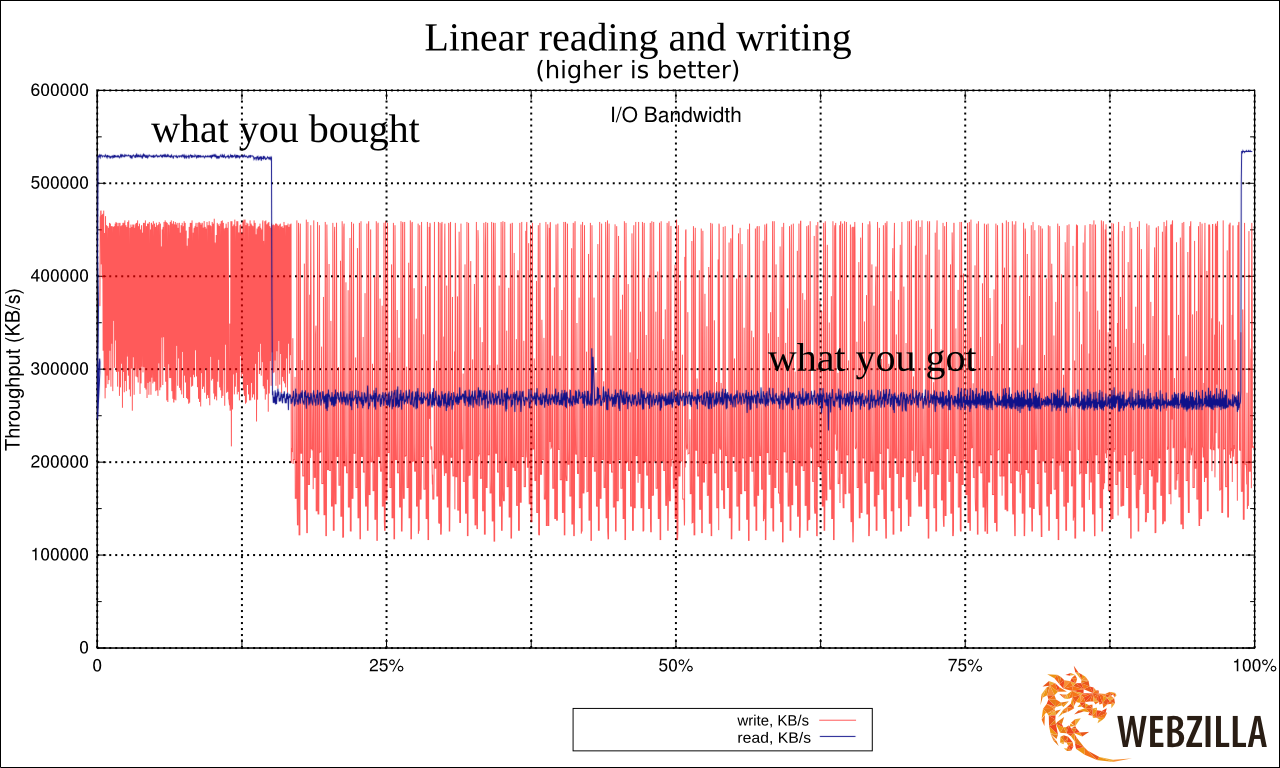
Увидев результат я реально взвился. Потому что это очень сильно напоминало ухищрения, на которые идут производители дешёвых USB-флешек. Они помещают быструю память в районы размещения FAT (таблицы) в FAT32 (файловой системе) и более медленную — в район хранения данных. Это позволяет чуть-чуть выиграть по производительности при работе с мелкими операциями с метаданными, при этом предполагая, что пользователи, копирующие большие файлы во-первых готовы подождать, а во вторых сами операции будут происходить крупными блоками. Подробнее про это душераздирающее явление: lwn.net/Articles/428584
Немного о Iptables, Iproute2 и эмуляции сетевых проблем
4 мин
Однажды мне понадобилось в Zabbix сделать мониторинг потери пакетов между мастером и репликами (репликация плохо себя чувствует если канал не очень хороший). Для этого, в Zabbix есть встроенный параметр icmppingloss, на удаленный хост отправляется серия ICMP пакетов и результат фиксируется в системе мониторинга. И вот параметр добавлен, триггер настроен. Казалось бы задача выполнена, однако как говорится «Доверяй, но проверяй». Осталось проверить что триггер сработает когда потери действительно будут. Итак, как сэмулировать потерю пакетов? Об этом, да и не только, пойдет речь под катом.

Использование DSP звуковой платы SB Live! на пользу радиолюбителей (KX Driver's) — Часть [1/2]
24 мин

Эксперименты по обработке звука аппаратными средствами SB Live и их возможное применение для работы в эфире. Заметка включает в себя инструкцию по применению альтернативных драйверов KX-Project, примеры применения и выводы по возможности реального применения. Период написания статьи 2006-2007 год, размещена была на страничке ныне уже не существующей коллективной радиостанции (RK3MXH). Авторство мое.
Статья может быть полезна не только радиолюбителям, но и меломанам, музыкантам и другим не равнодушным к качеству звука людям.
Под катом очень много текста и рисунков.
BGP: некоторые особенности поведения трафика
6 мин

В этой небольшой заметки хочу коснуться некоторых интересных моментов и особенностей управления трафиком (или попыток управления трафиком) в случае использования протокола BGP. Статья не даст ответ на вопрос о том, как сделать счастье в сети!
Изложенная информация носит познавательный характер и будет похожа на легкое чтиво для специалистов в области телекоммуникаций. Сведения будут изложены в достаточно свободной форме, без излишнего насыщения спецификой. Попробуем ответить на вопрос: «почему трафика нет там, где он должен быть, и есть там, где быть его не должно».