Константин Осипов (kostja )

Как родилась идея доклада? Я не очень люблю выступать и рассказывать про фичи, особенно про будущие фичи. Выясняется, что и люди не особо любят это слушать. Они любят слушать про то, как все устроено. Это доклад о том, как все устроено или должно быть, с моей точки зрения, устроено в современной СУБД.
Я попробую сделать так, чтобы мы смогли с макроуровня спуститься на микроуровень, т.е. каким образом, сначала отбрасывая макропроблемы, мы можем создать себе пространство для выбора на среднем уровне и микроуровне.

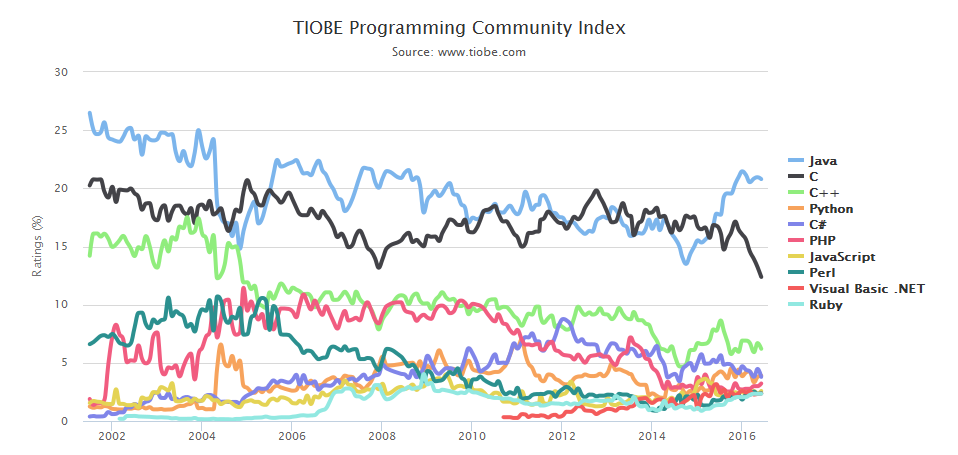
На макроуровне – это то, как должна быть устроена современная СУБД. Почему у нас сегодня есть возможность создавать новые базы данных, почему нельзя взять текущую и удовлетвориться ее производительностью, подтюнить или написать для нее патч? Просто взять и написать патч, который бы ее ускорил, если она медленная? Из какого пространства решений мы выбираем?








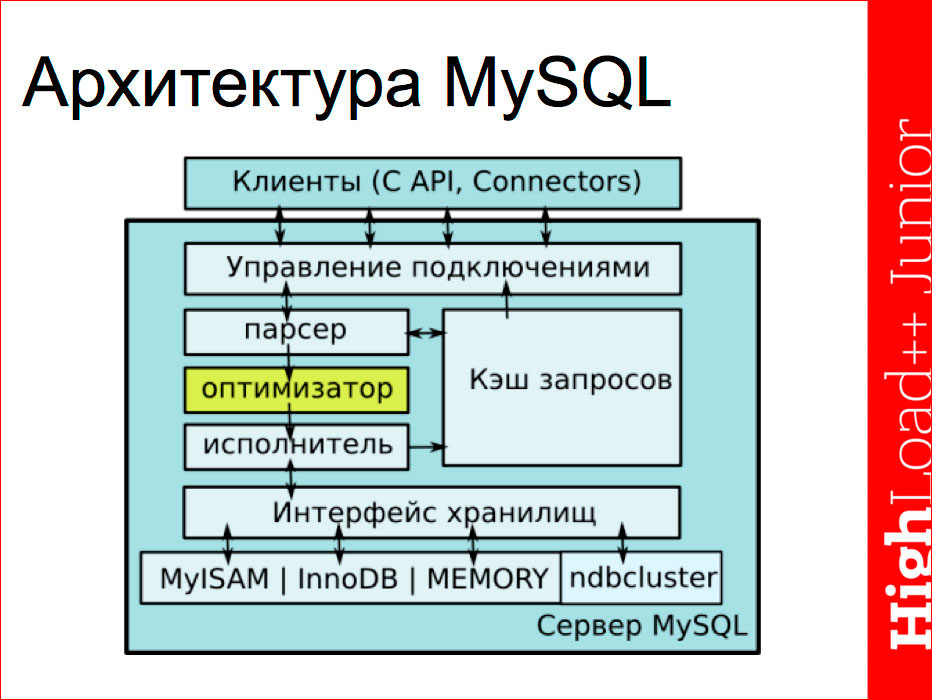


 Сегодня
Сегодня  Кто-то считает музыку уделом избранных талантов, кто-то — набором физических закономерностей. Автор материала делает попытку объяснить знакомые каждому музыкальные термины, такие как тон, интервал, амплитуда, нота, октава, партитура, аккорд и так далее с помощью расчетов и технических обоснований. Ниже перевод оригинального текста.
Кто-то считает музыку уделом избранных талантов, кто-то — набором физических закономерностей. Автор материала делает попытку объяснить знакомые каждому музыкальные термины, такие как тон, интервал, амплитуда, нота, октава, партитура, аккорд и так далее с помощью расчетов и технических обоснований. Ниже перевод оригинального текста. 

 В начале июня в Берлине прошла одна из самых продвинутых конференций по PHP — International PHP Conference 2016. В качестве докладчиков в ней приняли участие такие специалисты, как Себастьян Бергман, Арне Бланкертс, Стефан Прибш и еще более 50 человек, которые вносят свой постоянный вклад в развитие PHP. Конференция проводилась в шикарном 4-х звездочном отеле Маритим Проарте. Доклады читались в несколько параллельных потоков на английском и немецком и затрагивали как непосредственно PHP-разработку, так и околодевелоперские темы: инфраструктуру, серверное ПО, open source-разработку и многое другое. Отдельно хочется отметить ключевые доклады, которые зажигали то искрометным юмором, то глубиной затрагиваемых тем. В этой статье мы собрали свои впечатления от самых крутых докладов, с ссылками на презентации и примеры.
В начале июня в Берлине прошла одна из самых продвинутых конференций по PHP — International PHP Conference 2016. В качестве докладчиков в ней приняли участие такие специалисты, как Себастьян Бергман, Арне Бланкертс, Стефан Прибш и еще более 50 человек, которые вносят свой постоянный вклад в развитие PHP. Конференция проводилась в шикарном 4-х звездочном отеле Маритим Проарте. Доклады читались в несколько параллельных потоков на английском и немецком и затрагивали как непосредственно PHP-разработку, так и околодевелоперские темы: инфраструктуру, серверное ПО, open source-разработку и многое другое. Отдельно хочется отметить ключевые доклады, которые зажигали то искрометным юмором, то глубиной затрагиваемых тем. В этой статье мы собрали свои впечатления от самых крутых докладов, с ссылками на презентации и примеры.