
Оглавление:
Часть 1: Введение и лексический анализ
Часть 2: Реализация парсера и AST
Часть 3: Генерация кода LLVM IR
Часть 4: Добавление JIT и поддержки оптимизатора
Часть 5: Расширение языка: Поток управления
Часть 6: Расширение языка: Операторы, определяемые пользователем
Часть 7: Расширение языка: Изменяемые переменные
Часть 8: Компиляция в объектный код
Часть 9: Добавляем отладочную информацию
Часть 10: Заключение и другие вкусности LLVM

Добро пожаловать в главу 6 руководства “Создание языка программирования с использованием LLVM”. К данному моменту у нас есть полнофункциональный язык, хотя и минимальный, но, тем не менее, полезный. Но по-прежнему осталась одна проблема. В нашем языке мало полезных операторов (нет, например, деления, логического отрицания, и даже сравнений, за исключением оператора сравнения «меньше»).
Часть 1: Введение и лексический анализ
Часть 2: Реализация парсера и AST
Часть 3: Генерация кода LLVM IR
Часть 4: Добавление JIT и поддержки оптимизатора
Часть 5: Расширение языка: Поток управления
Часть 6: Расширение языка: Операторы, определяемые пользователем
Часть 7: Расширение языка: Изменяемые переменные
Часть 8: Компиляция в объектный код
Часть 9: Добавляем отладочную информацию
Часть 10: Заключение и другие вкусности LLVM
6.1. Введение
Добро пожаловать в главу 6 руководства “Создание языка программирования с использованием LLVM”. К данному моменту у нас есть полнофункциональный язык, хотя и минимальный, но, тем не менее, полезный. Но по-прежнему осталась одна проблема. В нашем языке мало полезных операторов (нет, например, деления, логического отрицания, и даже сравнений, за исключением оператора сравнения «меньше»).


 На работе в новом проекте используется СУБД PostgreSQL. Так как до сих пор я работал с MySQL, сейчас приходится изучать и открывать для себя Постгри. Первая проблема, которая меня заинтересовала — замена мускулевского
На работе в новом проекте используется СУБД PostgreSQL. Так как до сих пор я работал с MySQL, сейчас приходится изучать и открывать для себя Постгри. Первая проблема, которая меня заинтересовала — замена мускулевского  Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя.
Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя. 
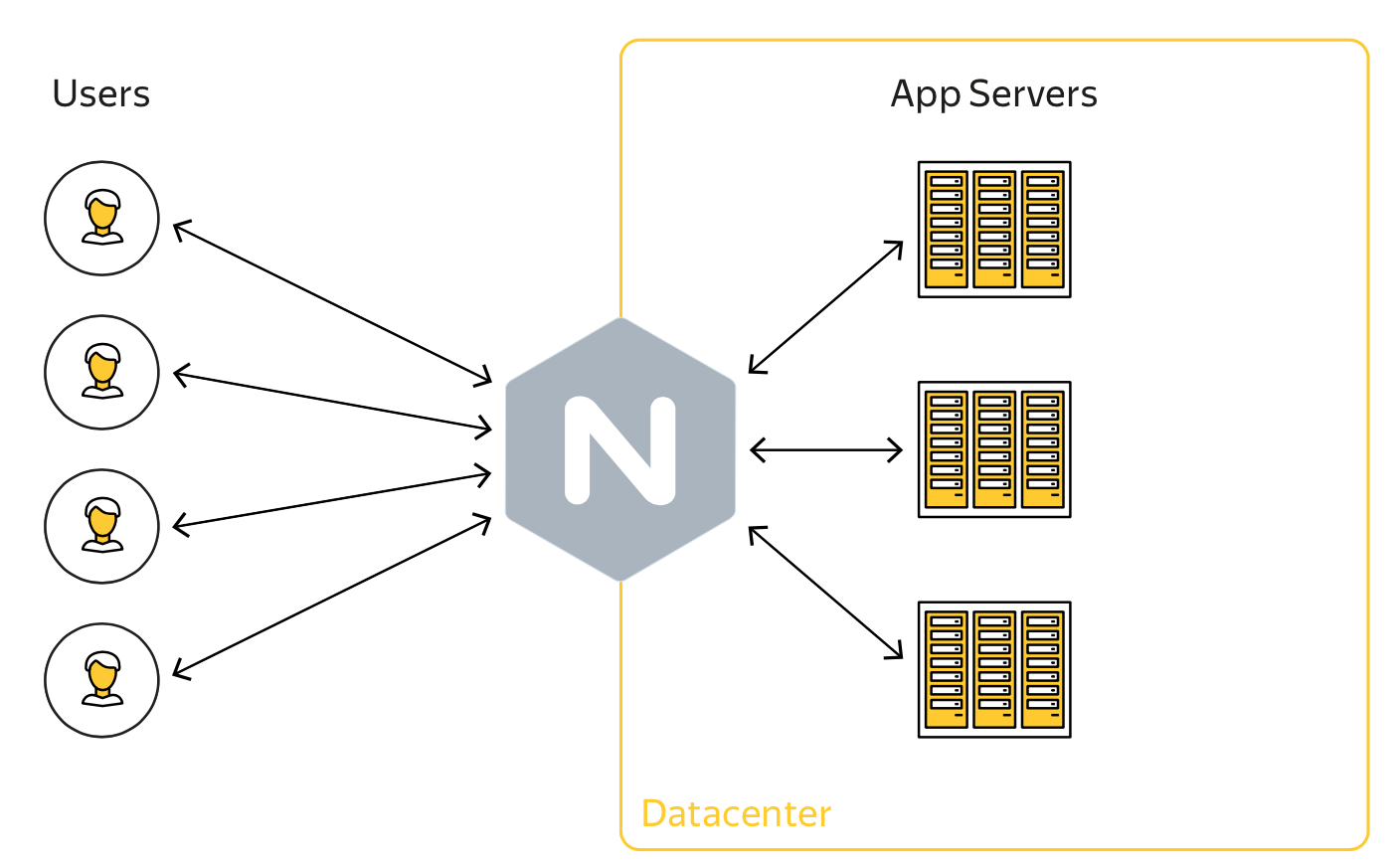


 Что такое хук?
Что такое хук?