Я продолжаю изучать MediaPipe — библиотеку с открытым исходным кодом от Google, предоставляющую "кроссплатформенные и кастомизируемые решения на основе машинного обучения для работы с медиа", и в этой статье хочу рассказать вам о 2 инструментах:
Selfie Segmentation, выделяющий людей на сцене, что позволяет осуществлять замену фона на кадрах видео в процессе потоковой передачи соответствующих данных;
Face Mesh, предоставляющий сетку лица человека, состоящую из 468 контрольных точек с координатами в трехмерном пространстве, что позволяет реализовать некоторые интересные визуальные эффекты.
В ходе доработки одного проекта возникала необходимость в кэширование часто запрашиваемых данных. Реализация кэширования возможна разными способами, но хотелось реализовать с минимальными изменениями исходного проекта. Результат, его плюсы и минусы описаны далее.
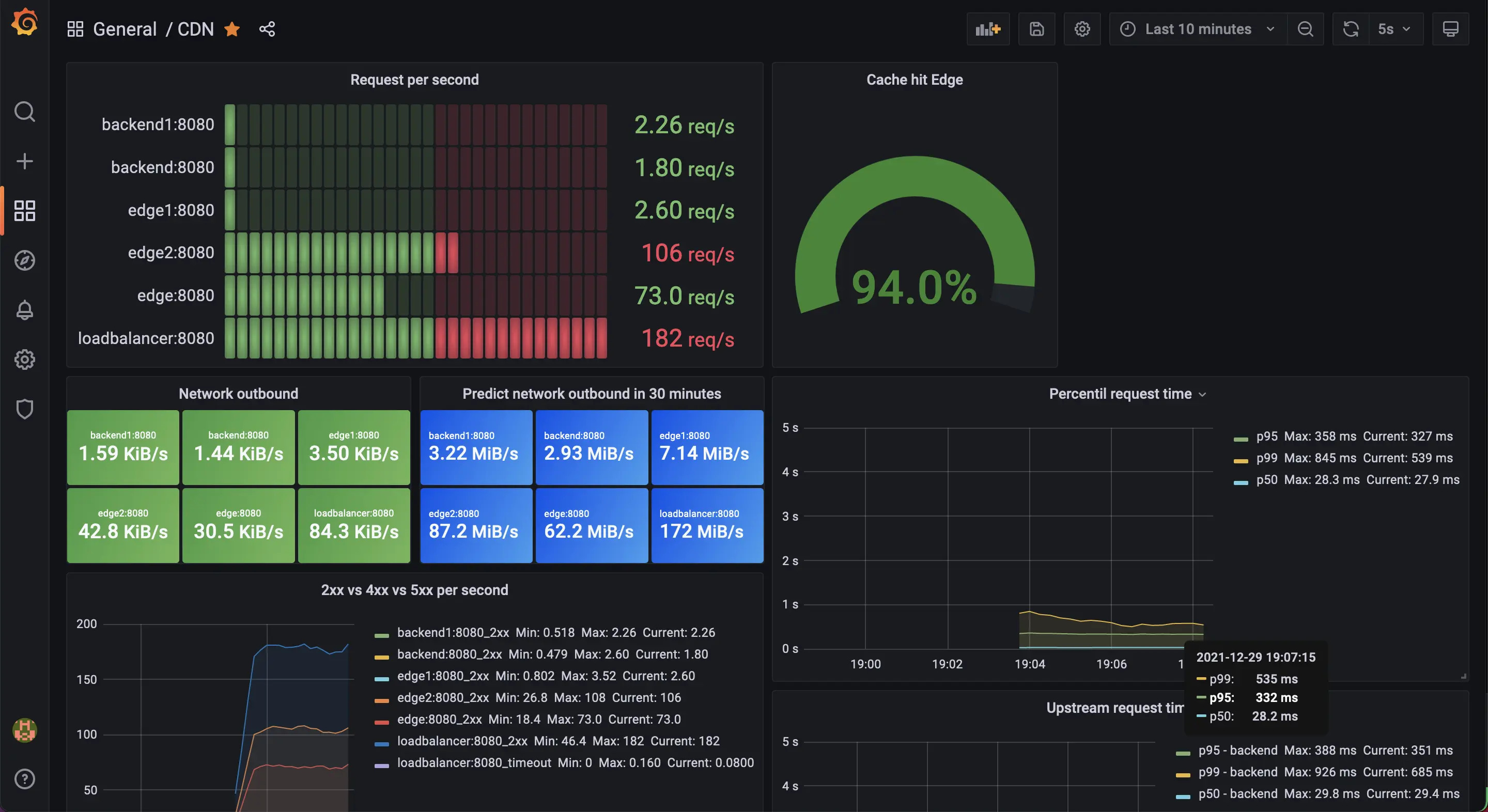
Сборная солянка из существующих best practices по работе с Grafana и немного с Prometheus, проверенных мной лично. Можно просто положить в закладки — когда-нибудь да пригодится.
Задача этого репозитория — создать свод знаний о том, как работают CDN, написав одну из них «с нуля». CDN, которую мы будем проектировать, использует следующие технологии: Nginx, Lua, Docker, docker-compose, Prometheus, Grafana и wrk.
Мы начнём с создания одного бэкенд-сервиса, а затем расширим его до многоузловой CDN с симуляцией задержек, а также возможностью наблюдений и тестирования. В каждом из разделов мы обсудим сложности и компромиссы при создании/управлении/эксплуатации CDN.
Язык Go в последнее время неоднократно обсуждался на хабре — его и критиковали , и хвалили. Мы в Intel любим Go и участвуем в open-source разработке этого проекта. Если вы тоже используете Go, интересуетесь его внутренним строением и вопросами наиболее эффективного программирования на этом замечательном языке, то добро пожаловать под кат. Статья будет о том, каким образом в Go реализован механизм внешних вызовов, и насколько быстро он работает.
Статья Основы мониторинга (обзор Prometheus и Grafana) оборвалась на самом интересном месте. Автор предложил искать и использовать актуальные экспортеры, а читатель такой – окей, где референс? Что ж, давайте рассмотрим топ-10 наиболее полезных экспортеров на начало 2023 года – возможно именно их вам не хватало, чтобы построить свою идеальную систему мониторинга!
Прим. перев.: автор этого материала — Герман Осин, старший архитектор решений в Provectus. Осин сравнивает функциональность восьми UI-инструментов, которые помогают решить проблемы наблюдаемости и мониторинга Apache Kafka. Стоит отметить, что обзор скорее вводный. Он будет полезен для первоначального знакомства с возможностями решений.
Apache Kafka — незаменимый инструмент для обработки данных в реальном времени и отслеживания активности приложений. К сожалению, мониторинг кластеров Apache Kafka и управление ими — непростая задача. Решить ее помогают сторонние коммерческие или Open Source-инструменты с графическим интерфейсом и дополнительными функциями в области администрирования и мониторинга.
В статье представлен краткий обзор таких инструментов.
Я начала пользоваться ClickHouse до того, как это стало мэйнстримом: первый раз я столкнулась c этой базой данных лет 8 назад. C тех пор я уверена, что это лучшая DB для аналитики. Большинство аналитиков, которых я знаю, в восторге от ClickHouse (иногда чтобы проникнуться, требуется немного времени: разобраться и привыкнуть к синтаксису).
В этой статье я расскажу что такое ClickHouse и почему я считаю его идеально подходящим мощным инструментом для аналитики. А также поделюсь tips & tricks из моего опыта. Поехали.
Я как человек измученный различными АСР и сам принимавший участие в разработке АСР регулярно сталкивался с отсутствием какой-то типовой схемы, которую можно было бы посмотреть для оценки АСР, а так же перед созданием своей АСР. В сети есть некоторое количество работ по этой теме к примеру я в свое время при написании диплома изучал вот этот вот труд Методы моделирования и разработки биллинговых систем. Диплом же и есть диплом и тащить из него схемы странное занятие, так-как реалиям он не отвечает.
Когда вы начинаете разрабатывать веб-приложение с применением Go, один из первых вопросов, которым вы, вероятно, зададитесь, — “Какой роутер мне следует использовать?”.
И это не такой простой вопрос, как может показаться сначала. Доступно более 100 различных роутеров с разными API, функциями и поведением. Для этой статьи я оценил 30 самых популярных из них и создал краткий список лучших вариантов вместе с блок-схемой, которую вы можете использовать, чтобы сделать свой выбор.
Данная статья является гайдом по построению REST прокси поверх существующих gRPC сервисов. После прочтения данного материала можно будет вызывать любой из существующих gRPC сервисов используя стандартный REST API, а так же получить полную документацию в swagger формате.
Работая над разными микро (и не очень) сервисами, написанными с помощью Symfony, я каждый раз сталкивался с необходимостью экспорта метрик для Prometheus. Поначалу мы просто копировали один и тот же код между проектами, но когда их стало больше трёх, я посчитал, что дальше так продолжаться не может (не буду вас тут утомлять объяснениями, почему это неудобно; думаю, каждый это и сам понимает).
Часто возникает проблема: одна из таблиц в базе данных сильно выросла и время выполнения запросов к этой таблице увеличилось. Одним из вариантов решения подобной проблемы в PostgreSQL является партицирование. В статье затронем не только техническую реализацию, но и опишем этапы подготовки к партицированию.
Представим, что у нас есть батон хлеба. Порежем его на части. Каждый отрезанный кусочек — часть целого батона, но не сам батон. То есть мы поделили целое на части — это и есть партицирование. Батон как целое соответствует таблице, а кусочки батона как части — партициям этой таблицы.
Мне понравился опыт прошлого расследования по фейсбуку, и я решил организовать очередную серию, теперь про Amazon. Для нетерпеливых — в самом конце статьи описан итоговый вариант архитектуры Amazon S3 и проанализированы его свойства.
Как ни странно, чтобы понять рекурсию, в PostgreSQL не надо понимать рекурсию. Потому что WITH RECURSIVE, который присутствует в посгресе (и в других серьёзных базах) — это скорее вычисление чего-то итерациями до того, как будет выполнено некоторое условие.
Тем не менее это очень полезный функционал базы, который можно использовать, например, чтобы вывести все подкатегории заданной категории, если таблица задана в виде (id, parent_id, ...)
Если ваши микросервисы уже используют общую базу PostgreSQL для хранения данных, или ей пользуются несколько экземпляров одного сервиса на разных серверах, можно относительно «дешево» получить возможность обмена сообщениями (PubSub) между ними без интеграции в архитектуру Redis, RabbitMQ-кластера или встройки в код приложения другой MQ-системы.
В PostgreSQL существует очень удобный механизм рекомендательных блокировок, они же — advisory locks. Мы в «Тензоре» используем их во многих местах системы, но мало кто детально понимает, как конкретно они работают, и какие проблемы можно получить при неправильном обращении.
Фразовые глаголы — это отдельная боль для студента, который изучает английский как второй. Мало того, что каждый отдельный предлог меняет значение глагола полностью, так и еще их просто целая куча.
Мы решили запустить новую рубрику и рассказывать про фразовые глаголы весело. Чтобы не зубрить их, а нормально запоминать на примерах из фильмов и сериалов.
И начнем со слова «get». По нашему опыту, студенты делают во фразовых глаголах с ним огромное количество ошибок. Так что не будем затягивать, поехали!
Команда Kubernetes as a Service в Mail.ru Cloud Solutions перевела контрольный список для запуска Redis внутри кластера Kubernetes. С ним стоит ознакомиться до того, как перейти к использованию Redis под рабочей нагрузкой.
Redis — популярное in-memory хранилище данных и кэш с открытым исходным кодом. Этот продукт стал важным компонентом построения масштабируемых микросервисных систем. Многие облачные провайдеры предлагают полностью управляемые сервисы Redis: Amazon ElastiCache, Azure Cache for Redis, GCP Memorystore (и на платформе MCS тоже есть такой управляемый сервис — прим. переводчика). Однако Redis также можно легко развернуть в Kubernetes, если вам нужно полнее контролировать его конфигурации. Прямо из коробки у него уже достойная производительность, но если вы собираетесь использовать Redis с рабочей нагрузкой, то сначала проверьте, выполняются ли все пункты этого чек-листа.
Почти в самом начале создания платформы (некоего фундамента, фреймворка на котором базируются все прикладные решения) нашего облачного веб-приложения СБИС мы поняли, что без инструмента, позволяющего сообщить пользователю о каком-либо событии с сервера, жить будет довольно-таки трудно. Все мы хотим мгновенно видеть новое сообщение от коллеги (которому лень пройти 10 метров), поднимающую корпоративный дух новость от руководства, очень важную задачу от отдела тестирования или получение поощрения (особенно денежного). Но путь становления был тернист, поэтому расскажем немного про трудности, которые мы встретили при взрослении от 5.0e3 до 1.0e6 одновременных подключений от пользователей.