Читать дальше →

Андрей Евдокимов @kraamis
Пользователь

Напишем и поймем Decision Tree на Python с нуля! Часть 3. Библиотека для анализа данных Pandas
5 мин
Туториал
Перевод
Привет, Хабр! Представляю вашему вниманию перевод статьи "Pythonで0からディシジョンツリーを作って理解する (3. データ分析ライブラリPandas編)".
Это третья статья из серии. Ссылки на предыдущие статьи: первая, вторая
В данной статье я объясню, как работать с библиотекой Pandas, чтобы создавать Decision Tree.
В pandas используются такие структуры, как Data frame и Series.
Рассмотрим их на примере следующей таблицы, напоминающей Excel.
Одна строка данных называется Series, столбцы — атрибутами этих данных, а вся таблица целиком — Data frame-ом.

Это третья статья из серии. Ссылки на предыдущие статьи: первая, вторая
В данной статье я объясню, как работать с библиотекой Pandas, чтобы создавать Decision Tree.
3.1 Импортируем библиотеку
# импортируем pandas и прописываем, что далее мы будем ее указывать как pd
import pandas as pd3.2 Data frame и Series
В pandas используются такие структуры, как Data frame и Series.
Рассмотрим их на примере следующей таблицы, напоминающей Excel.
Одна строка данных называется Series, столбцы — атрибутами этих данных, а вся таблица целиком — Data frame-ом.
Напишем и поймем Decision Tree на Python с нуля! Часть 2. Основы Python, необходимые для генерации Decision Tree
8 мин
Туториал
Перевод
Привет, Хабр! Представляю вашему вниманию перевод статьи "Pythonで0からディシジョンツリーを作って理解する (2. Pythonプログラム基礎編)".
Данная статья — вторая в серии. Первую вы можете найти здесь.
Данная статья — вторая в серии. Первую вы можете найти здесь.
2.1 Комментарии обозначаются # или ''' (три одинарные кавычки)
# Комментарий
a = 1 # Комментарий
''' Это тоже комментарий
b = c
c = d
'''2.2 Использование динамической типизации (тип определяется автоматически)
# динамическая типизация переменных
# = копирование значения справа налево
i = 1 # целое число (int)
f = 2.1 # число с плавающей запятой (float)
s = "a" # строковый тип (string)
b = True # логический тип (boolean)
l = [0,1,2] # массив,список (array)
t = (0,1,2) # кортеж (tuple)
d = {"a":0, "b":1} # словарь, ассоциативный массив
print(i,f,s,b,l,t,d)
# 1 2.1 a True [0, 1, 2] (0, 1, 2) {'a': 0, 'b': 1}
# Когда хотим определить тип, используем type
print(type(i)) # Вывод <class 'int'>
# Переменная не сохраняет, а содержит фактическое значение
# Это, своего рода, переменная-ссылка, указывающая на местоположение значения
# Можно получить идентификатор актуального значения через id
print(id(l)) # 00000000000000 (меняется от исполнения к исполнениюц)
l2 = l # Приведу в пример копию массива, где ссылаюсь на 2 его элемента, а фактический массив - 1.
print(id(l2)) # 00000000000000 (то же значение, что у вышеуказанного id(l))
# Поскольку существует только один фактический массив, кажется, что он был добавлен в массив l, даже если вы добавили элемент со ссылкой на l2.
l2.append(1)Напишем и поймем Decision Tree на Python с нуля! Часть 1. Краткий обзор
8 мин
Перевод
Привет, Хабр! Представляю вашему вниманию перевод статьи "Pythonで0からディシジョンツリーを作って理解する (1. 概要編)".
Например, у нас есть следующий набор данных (дата сет): погода, температура, влажность, ветер, игра в гольф. В зависимости от погоды и остального, мы ходили (〇) или не ходили (×) играть в гольф. Предположим, что у нас есть 14 сложившихся вариантов.

Из этих данных мы можем составить структуру данных, показывающую, в каких случаях мы шли на гольф. Такая структура из-за своей ветвистой формы называется Decision Tree.
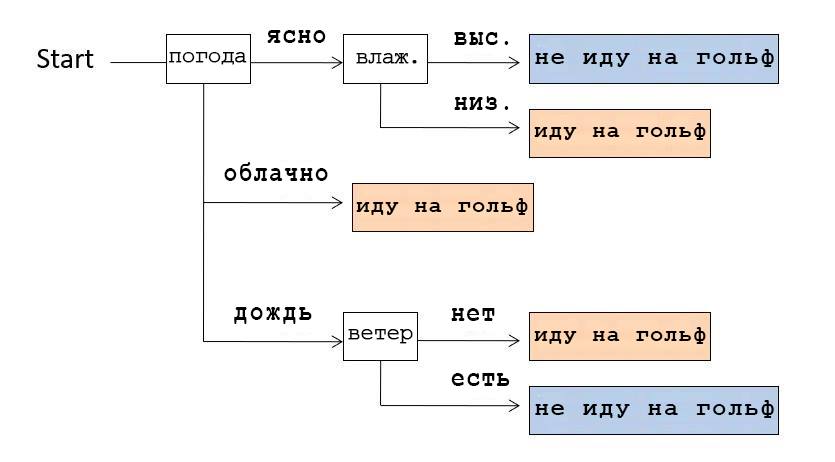
Например, если посмотреть на Decision Tree, изображенный на картинке выше, мы поймем, что сначала проверяли погоду. Если было ясно, мы проверяли влажность: если она высокая, то не шли играть в гольф, если низкая — шли. А если погода была облачная, то шли играть в гольф вне зависимости от других условий.
1.1 Что такое Decision Tree?
1.1.1 Пример Decision Tree
Например, у нас есть следующий набор данных (дата сет): погода, температура, влажность, ветер, игра в гольф. В зависимости от погоды и остального, мы ходили (〇) или не ходили (×) играть в гольф. Предположим, что у нас есть 14 сложившихся вариантов.
Из этих данных мы можем составить структуру данных, показывающую, в каких случаях мы шли на гольф. Такая структура из-за своей ветвистой формы называется Decision Tree.
Например, если посмотреть на Decision Tree, изображенный на картинке выше, мы поймем, что сначала проверяли погоду. Если было ясно, мы проверяли влажность: если она высокая, то не шли играть в гольф, если низкая — шли. А если погода была облачная, то шли играть в гольф вне зависимости от других условий.
Как разобраться в дереве принятия решений и сделать его на Python
5 мин
Туториал
Перевод
Совсем скоро, 20 ноября, у нас стартует новый поток «Математика и Machine Learning для Data Science», и в преддверии этого мы делимся с вами полезным переводом с подробным, иллюстрированным объяснением дерева решений, разъяснением энтропии дерева решений с формулами и простыми примерами, вводом понятия «информационный выигрыш», которое игнорируется большинством умозрительно-простых туториалов. Статья рассчитана на любящих математику новичков, которые хотят больше разобраться в работе дерева принятия решений. Для полной ясности взят совсем маленький набор данных. В конце статьи — ссылка на код на Github.

Пишем на языке С/C++ в Linux под KolibriOS
3 мин
Туториал
Вступление
KolibriOS – миниатюрная операционная система, ядро и большинство программ которой написано на ассемблере. Это, конечно же, не значит, что на других языках программирования писать для KolibriOS нельзя.
Данная статья — инструкция по настройке toolchain'а для Linux.
Факторизация и эллиптическая кривая. Часть V
14 мин

Прочие статьи цикла
К тем сведениям об эллиптических кривых (ЭК), которые доступны читателям Хабра и Интернета в целом, а также из бумажных книг, предлагаю дополнительные, уточняющие важные детали, опущенные в некоторых статьях. Например, в работе приводится изображение тора (рис. 4), но никаких оговорок не делается. Откуда он взялся, почему тор? Другие авторы вообще не упоминают эту фигуру. В чем здесь дело?
Не могу назвать публикацию на Хабре и других сайтах, где автор говорил бы о полях многочленов, хотя обозначение ) таких полей некоторыми авторами и используются, но делается это неправильно. Неприводимый многочлен и примитивный элемент поля и не задаются, что не позволяет читателю построить такое поле и работать с ним, проверить вычислением приводимый результат, если числовой пример вообще приводится. От таких публикаций остается ощущение зря потраченного времени. Такие поля расширения используются в стандартах цифровой подписи и шифрования рядом государств.
Факторизация чисел и сумма неизвестных делителей. Часть IV
14 мин
Прочие статьи цикла
Факторизация чисел и методы решета. Часть I
Факторизация чисел и методы решета. Часть II
Факторизация чисел и эллиптическая кривая. Часть III
Факторизация чисел и сумма неизвестных делителей. Часть IV
Факторизация и эллиптическая кривая. Часть V
Факторизация чисел и методы решета. Часть II
Факторизация чисел и эллиптическая кривая. Часть III
Факторизация чисел и сумма неизвестных делителей. Часть IV
Факторизация и эллиптическая кривая. Часть V
Возможность единственного представления составного нечетного натурального числа (СННЧ) N в виде произведения степеней простых (кроме 2) чисел составляет существо основной теоремы арифметики (ОТА). Для больших чисел, содержащих в своей записи и более цифр, эта возможность, а точнее задача не получила приемлемого для практики (за обозримое время) решения до наших дней. Кратко эту задачу называют задачей факторизации больших чисел(ЗФБЧ). Ее формулировка проста и известна уже несколько тысячелетий: для заданного натурального числа N = pq найти все его нетривиальные делители.
Факторизация и эллиптическая кривая. Часть III
21 мин
Прочие статьи цикла
Факторизация чисел и методы решета. Часть I
Факторизация чисел и методы решета. Часть II
Факторизация и эллиптическая кривая. Часть III
Факторизация чисел и сумма неизвестных делителей. Часть IV
Факторизация и эллиптическая кривая. Часть V
Факторизация чисел и методы решета. Часть II
Факторизация и эллиптическая кривая. Часть III
Факторизация чисел и сумма неизвестных делителей. Часть IV
Факторизация и эллиптическая кривая. Часть V
Использование эллиптических кривых (ЭК) для решения разнообразных задач криптологии коснулось каким-то боком и факторизации чисел. Здесь будем рассматривать вопрос, касающийся ЭК и не только в связи с проблемой факторизации составного нечетного натурального числа (СННЧ), но несколько шире.
Если пройтись по Интернету и по статьям об ЭК на Хабре, то после этого возникает мысль, что существует определенный пробел всех без исключения публикаций, включая и объемные бумажные книги. Авторы почему-то считают само-собой разумеющимся понимание природы ЭК и ее аддитивной группы, ее появление. На самом деле ЭК и ее группа (мое мнение) — это чудо!
Группа точек плоскости, множество которых замкнуто по операции сложения, оказалась каким-то образом встроена в ЭК и мы об этом до сего дня не знали бы, не располагая теорией групп, и даже при наличии теории групп, без гения Эйлера и Пуанкаре, которые нам эту группу открыли. В свое время Иоганн Кеплер открыл человеку законы движения Планет и качественно описал их траектории, но только гений Ньютона смог объяснить природу этих законов.
Правда для этого ему пришлось открыть свои законы движения/тяготения и изобрести дифференциальное и интегральное исчисления. Задача взятие двукратного интеграла от второго закона Ньютона, в котором ускорение — вторая производная пути, решением имеет плоскую кривую второго (не третьего, не путать эллипсы — траектории планет, спутников и эллиптические кривые в криптологии) порядка, что до И. Ньютона было открыто И.Кеплером.
Факторизация чисел и методы решета. Часть II
11 мин
Прочие статьи цикла
Задается N — большое составное нечетное натуральное число (СННЧ), которое требуется факторизовать. Математическая теория метода решета числового поля (NFS) строится на основе теории делимости в алгебраических числовых полях. Перед любым автором, как и передо мной, возникает трудность сжатого изложения весьма обширного материала, касающегося методов SNFS и GNFS. Так как 2-й возник из 1-го я не привожу их отличий, хотя об этом много сказано.
О методах написаны целые книги. Но, помня о собственных затруднениях в изучении методов и преодолении их, считаю, что даже «куцее» урезанное изложение будет способствовать ознакомлению читателей с методами и идеями, лежащими в их основе. Надеюсь, что понимание этих идей их ограниченности (что практика подтверждает многократно), позволит более трезво подойти к тому, что предлагается мной в проблеме факторизации.
Можно сказать читатели принудили меня доносить до них чужие идеи, которые я не разделяю, так как свои считаю более обоснованными и прогрессивными, более здравыми. Они пока не получили завершенного вида, но время еще есть. Хочу изменить у читателей отношение к своим идеям и получить поддержку, а не минусы в комментариях, не подкрепляемые доводами. Личную неприязнь или «ничего не понял» доводом для минусования публикации считать не могу.
Неоправданное усложнение (матрица СЛАУ для имеет размер 6000000×6000000) задачи факторизации больших чисел (ЗФБЧ) подвигло меня серьезно заняться этой проблемой. Уже удалось вскрыть закон распределения делителей СННЧ в НРЧ, т.е. понять где и как прячутся делители в натуральном ряде чисел, что конечно же упростит их поиск и обнаружение.
Факторизация чисел и методы решета. Часть I
12 мин
Прочие статьи цикла
В работе рассматривается традиционный подход, который автором в ряде статей критикуется.
Здесь я воздержусь от критики, и направлю свои усилия на разъяснение сложных моментов в традиционном подходе. Весь арсенал существующих методов не решает задачу факторизации в принципе, так как почти все решеточные и другие алгоритмы построены на жесткой связи и зависимости времени их выполнения от разрядности факторизуемого числа N. Но замечу, что у чисел имеются и другие свойства кроме разрядности, которые можно использовать в алгоритмах факторизации.
Оценки сложности — эвристические опираются на рассуждения ограниченные авторским пониманием проблемы. Пора бы уже понять, что факторизация чисел в глубоком тупике, а математикам (не только им) пересмотреть свое отношение к проблеме и создать новые модели.
Простая идея факторизации целого нечетного числа N исторически — состоит в поиске пары квадратов чисел разной четности, разность которых кратна kN, при k =1 разложение успешно реализуется так как в этом случае сразу получаем произведение двух скобок c сомножителями N. При k>1 случаются тривиальные разложения.
Таким образом, проблема факторизации преобразуется в проблему поиска подходящих квадратов чисел. Понимали эти факты многие математики, но П. Ферма первым в 1643 году реализовал идею поиска таких квадратов в алгоритме, названном его именем. Перепишем иначе приведенное соотношение .
Если разность слева от равенства не равна квадрату, то изменяя х, можно подобрать другой квадрат, чтобы и справа получался квадрат. Практически все нынешние алгоритмы используют эту идею (поиска пары квадратов), но судя по результатам, похоже, что идея себя исчерпала.
Windows: достучаться до железа
11 мин

Меня всегда интересовало низкоуровневое программирование – общаться напрямую с оборудованием, жонглировать регистрами, детально разбираться как что устроено... Увы, современные операционные системы максимально изолируют железо от пользователя, и просто так в физическую память или регистры устройств что-то записать нельзя. Точнее я так думал, а на самом деле оказалось, что чуть ли не каждый производитель железа так делает!
Как будет выглядеть реалистичный бой в космосе?
8 мин
Перевод

У научно-фантастических фильмов про космос очень слабая образовательная составляющая. В фильмах крутые пилоты во время дуэлей ведут свои космические корабли сквозь космическое пространство так, будто находятся в атмосфере. Они меняют крен, делают повороты, петли и бочки, иногда применяют переворот Иммельмана – будто бы зависят от гравитации Земли. Реалистично ли это?
Нет.
На самом деле, бой в космосе, скорее всего, будет выглядеть совершенно по-другому. И поскольку в космос выходит всё больше техники, и конфликты в будущем вполне возможны, пора задуматься: как на самом деле будет выглядеть бой в космосе?
От складных телефонов к растягивающимся экранам
8 мин
Перевод
Сегодня можно купить смартфон со складным экраном. Завтра, возможно, у нас будет уже растягивающийся экран

Motorola показала первый портативный мобильный телефон почти полвека назад. Он был размером с кирпич, и весил как половина кирпича. Через десять лет на его основе появился первый коммерческий мобильный телефон. Он тоже выглядел неуклюже, однако позволял владельцу на ходу отправлять и принимать звонки, что в ту пору было в новинку. С тех пор мобильные телефоны приобрели множество иных функций. Теперь они обрабатывают текстовые сообщения, выходят в веб, играют музыку, делают фотографии и видео, выводят их на экран, показывают своё местоположение на карте – всего не перечесть. Возможности их применения вышли за пределы любых мечтаний, существовавших в момент их появления.
Но при всей их универсальности смартфоны до сих пор борются с фундаментальным недостатком: у них слишком маленькие экраны. Да, некоторые телефоны делают побольше, чтобы увеличить экран. Однако если телефон станет слишком большим, он перестанет влезать в карман, что будет нежелательно для многих.
Очевидное решение – сделать так, чтобы дисплей можно было складывать на манер бумажника. Много лет мы в Сеульском национальном университете занимались разработкой подходящей технологии. Этим же занимались и производители смартфонов, которые только в последние пару лет смогли вывести эту технологию на рынок.
О понимании в искусственном интеллекте
5 мин
Искусственный интеллект сейчас представляется различными системами, но о понимании можно говорить только в диалоговых системах Искусственного Интеллекта (ИИ). И сама тема понимания в ИИ сводится к нескольким аспектам диалогового взаимодействия искусственного агента с человеком:
Понимания смысла в полной мере нельзя отнести к теме понимания контекста диалога, так как смысл высказывания собеседника может быть по-разному интерпретирован, и какой интерпретации должно соответствовать состояние понимания, не ясно. Можно ли «ошибки» по мнению собеседника (человека) интерпретировать как иное понимание смысла выражения системой? В большей степени понимания смысла относится к пониманию намерений и целей высказывания, а это отдельная тема theory of mind. «Здравый смысл» как критерий понимания можно интерпретировать точнее. В общем смысле это соответствие ответа картине мира, что поддается проверке. И на сегодня это является лучшим критерием понимания искусственными агентами, такими как диалоговые боты, контекста диалога. Но пока в этом боты не демонстрируют успехи.
Релевантный ответ является самым простым критерием понимания ботом собеседника (человека). Но этот критерий легко «подделать», что ни раз демонстрировалось участниками Премии Лёбнера. Он достигается закладыванием большого числа вариативных шаблонов ответов на распознаваемые нейронной сетью «интентов». Это трудно назвать пониманием. Но и успехи таких ботов скромны – смешанные интенты они распознают крайне плохо. Один вопрос вне тем шаблонов и система проваливается. Это легко проверить на таких ботах как Алиса от Яндекс и Siri от Apple. Можно сказать, что знания мира у таких систем фрагментарны.
- Порождаемые диалоговой системой тексты отвечают «здравому смыслу».
- Ответы системы соответствуют контексту диалога и ожиданиям человека.
- Понимание целей, намерений высказываний человека в диалоге.
Понимания смысла в полной мере нельзя отнести к теме понимания контекста диалога, так как смысл высказывания собеседника может быть по-разному интерпретирован, и какой интерпретации должно соответствовать состояние понимания, не ясно. Можно ли «ошибки» по мнению собеседника (человека) интерпретировать как иное понимание смысла выражения системой? В большей степени понимания смысла относится к пониманию намерений и целей высказывания, а это отдельная тема theory of mind. «Здравый смысл» как критерий понимания можно интерпретировать точнее. В общем смысле это соответствие ответа картине мира, что поддается проверке. И на сегодня это является лучшим критерием понимания искусственными агентами, такими как диалоговые боты, контекста диалога. Но пока в этом боты не демонстрируют успехи.
Анализ подходов
Релевантный ответ является самым простым критерием понимания ботом собеседника (человека). Но этот критерий легко «подделать», что ни раз демонстрировалось участниками Премии Лёбнера. Он достигается закладыванием большого числа вариативных шаблонов ответов на распознаваемые нейронной сетью «интентов». Это трудно назвать пониманием. Но и успехи таких ботов скромны – смешанные интенты они распознают крайне плохо. Один вопрос вне тем шаблонов и система проваливается. Это легко проверить на таких ботах как Алиса от Яндекс и Siri от Apple. Можно сказать, что знания мира у таких систем фрагментарны.
Красота, которая не спасла программиста
8 мин
«За что тебя приняли, за то тебя и уволят», гласит старинная мудрость. Меня позвали на этот завод для аудита учета, информационной системы, кода, процессов и т.д. Но начали с того, что у них – плохой программист. Стандартный, заводской, ужасный.
Завод создавал красивые продукты. И сам был красивый. Реально красивый – видимо, в проектировании здания участвовали те же дизайнеры, что рисуют продукцию. В цехах – тоже красота и гармония. Чистота, порядок, всё на своих местах. А главное – весь производственный процесс красиво автоматизирован.
Завод создавал красивые продукты. И сам был красивый. Реально красивый – видимо, в проектировании здания участвовали те же дизайнеры, что рисуют продукцию. В цехах – тоже красота и гармония. Чистота, порядок, всё на своих местах. А главное – весь производственный процесс красиво автоматизирован.
Как принять сигналы немецкого ВМФ с помощью звуковой карты, или изучаем радиосигналы сверхнизких частот
4 мин
Туториал
Привет, Хабр.
Тема приема и анализа сверхдлинных волн весьма интересна, но на Хабре она упоминается весьма редко. Попробуем восполнить пробел, и посмотрим как это работает.

Передатчик VLF в Японии (с) en.wikipedia.org/wiki/Very_low_frequency
Тема приема и анализа сверхдлинных волн весьма интересна, но на Хабре она упоминается весьма редко. Попробуем восполнить пробел, и посмотрим как это работает.
Передатчик VLF в Японии (с) en.wikipedia.org/wiki/Very_low_frequency
Ethernet – 40 лет: от наброска на салфетке до гигабитных линий связи
5 мин
Перевод
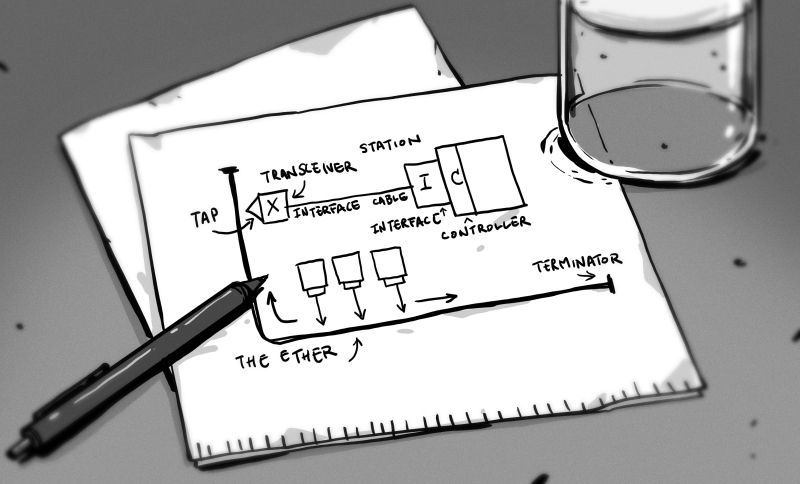
Коммерческая жизнь Ethernet началась 30 сентября 1980 года – следовательно, в этом году ему исполнилось ровно 40 лет. Впервые его определил патент, поданный на рассмотрение компанией Xerox в 1975-м. В нём был описан сетевой протокол передачи данных на скорости 10 Мб/с. На рынок протокол вышел в 1980-м, а в 1983-м IEEE подредактировал его, сделав стандартом IEEE 802.3. Следующие 37 лет этот стандарт множество раз обновлялся и пересматривался.
В современном стандарте Ethernet есть не только разные градации скорости, от изначальных 10 Мб/с до сегодняшних максимальных 400 Гб/с, но и бессчётное множество изменений, внесённых в основной протокол. Эти изменения позволяют как использовать современные скорости, так и новые применения Ethernet – например, электропитание и маршрутизация объединительной платы [backplane routing]. Надёжность и экономичность Ethernet в 1990-м году позволили создать стандарт 10BASE-T (802.3i-1990), который постепенно проник в настольные компьютеры.
История Open Source кратко: от калькулятора до миллиардных сделок
17 мин

Когда говорят «Open Source», обычно первые ассоциации — это Ричард Столлман и Линус Торвальдс. Но Open Source начался не с них, а зародился в 50-х, когда учёные и инженеры писали ПО и безвозмездно обменивались результатами своего труда. Мы попробовали разобраться в истории Open Source, какие события способствовали его развитию и почему без Open Source IT не был бы таким, какой он есть: программы для «Оборонного калькулятора», коммерциализация UNIX, письмо Билла Гейтса, манифест GNU, Linux и миллиардные сделки покупок Open Source компаний.
Россия готовится к радиоэлектронной борьбе в космосе Часть 2. The Space Review
18 мин
Перевод

Барт Хендрикс, понедельник, 2 ноября 2020 г.
Первоисточник:
[Часть 1 была опубликована на прошлой неделе]