
Одним из популярных оркестратором задач является Apache Airflow. Он, как и все инструменты, имеет свои преимущества и недостатки, о которых пойдет речь в данной статье.

Devops
Одним из популярных оркестратором задач является Apache Airflow. Он, как и все инструменты, имеет свои преимущества и недостатки, о которых пойдет речь в данной статье.
Приветствую тебя, хаброжитель!
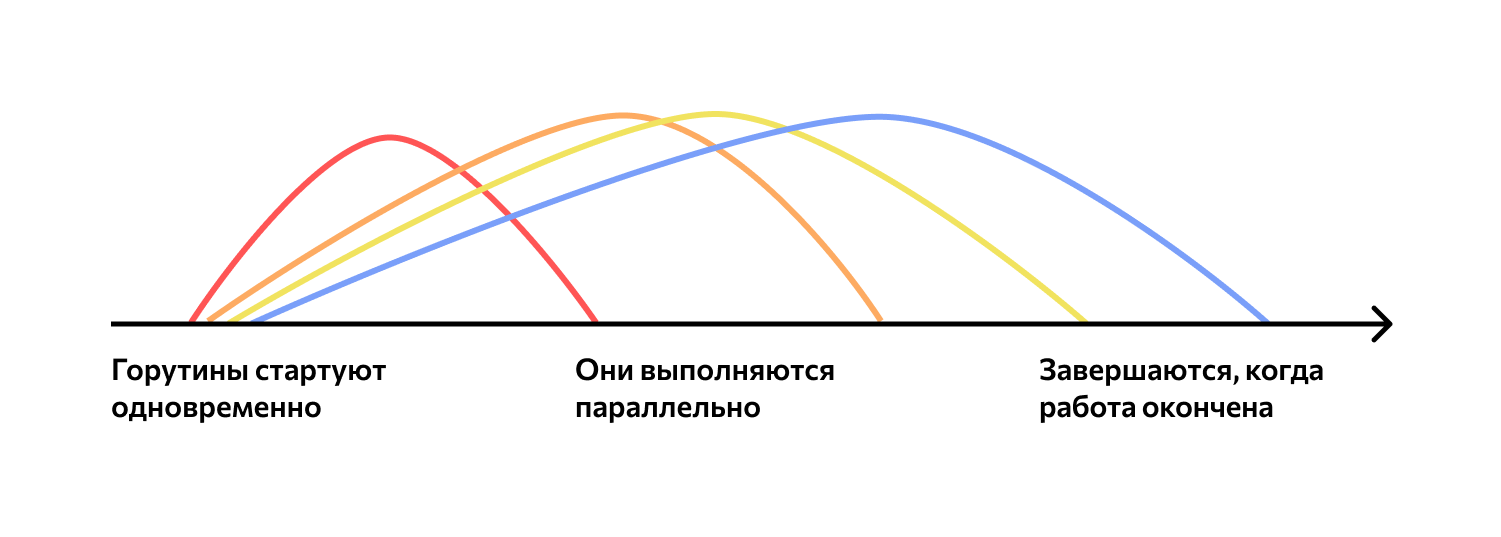
В этой статье разберём 100 вопросов, они покрывают львиную долю того, что могут спросить на собеседовании джуниор Go-разработчика с практически любой специализацией. Конечно же, в реальной работе на Go требуются немного другие скиллы, чем умение быстро ответить на любой вопрос. Однако сложилась добрая традиция делать из собеседования викторину с главным призом в виде трудоустройства — к этому нужно быть готовым.

Data science - это область, которая занимается изучением и анализом больших объемов данных, чтобы находить в них полезные закономерности, делать прогнозы или принимать решения на основе фактов. Самым популярным языком программирования для data science является Python. Библиотеки pyhton, о которых пойдет речь: NumPy, SciPy, Pandas, Matplotlib. Статья написана для новичков, которые хотят узнать о python стеке для data science.

Привет! Меня зовут Дима Вагин, я бэкенд-инженер в Авито. Сегодня расскажу, как мы работаем с БД PostgreSQL из Go. Покажу, какие библиотеки и пулеры соединений мы используем для доставки в код параметров подключения и как мы их настраиваем. А ещё расскажу про проблемы, к которым приводит отмена контекста, и о том, как мы с ними справляемся.

Данных становится все больше. Важно уметь эффективно хранить и обрабатывать их для решения сложных бизнес-задач. Одним из первых шагов на пути к успешной стратегии является выбор технологии хранения, поиска, анализа и отчетности по данным. Как выбрать между базой данных, Data Warehouse и Data Lake? Рассмотрим ключевые различия и когда следует использовать каждое.

Привет, Хабр!
В Kubernetes принято разделение хранилищ на два основных типа: постоянные и временные.
Постоянные хранилища (PV) представляют собой сегменты дискового пространства, которые могут быть подключены к подам и сохранять данные даже после перезапуска или удаления контейнеров. Эти объемы предоставляются через механизм Persistent Volume Claims, который позволяет юзерам и приложениям запрашивать хранилище определенного размера и класса, абстрагируясь от физической реализации хранилища.
А вот временные хранилища связаны с жизненным циклом контейнера и используются для хранения данных, актуальных только во время работы контейнера.
Классификация хранилищ в Kubernetes не ограничивается только этим разделением. Существуют различные StorageClasses, которые позволяют определять классы хранилищ с разными характеристиками.
Также в Kubernetes реализован контейнерный интерфейс хранения.
Основы всего из этого рассмотрим в этой статье.

В этой статье, посвященной Python streaming с использованием Spark и Kafka мы рассмотрим основные шаги по настройке окружения и запуску первых простых программ


Трейдеры на финансовом рынке обрабатывают большие объемы информации и принимают решения максимально быстро, чтобы не упустить возможность и избежать рисков. Получить преимущество можно, если умеешь хотя бы немного программировать. Это особенно важно там, где время — деньги.
Я Александр Парфенов, бэкенд-разработчик в Тинькофф Инвестициях и автор InvestAPI SDK для языка Go. Расскажу о том, как автоматизировать торговые стратегии при помощи Tinkoff INVEST API и языка Go.

Хладнокровная машина, не знающая печали и жалости. Неумолимо и прямолинейно выполняющая поставленную ей задачу до конца. Таким запомнился зрителю терминатор из одноимённого фильма. Согласно его сценарию, бездушная машина прибыла к нам из будущего. И вот, именно сейчас мы подходим к тому времени, когда в мире из фильма машины берут верх над людьми.
Если обратить свое внимание на техническую сторону этого робота, то то, что удивляло в 1984 году, сейчас кажется чем-то знакомым, и уже маячит на горизонте. На каких же технологиях эти роботы построены там, глубоко внутри своего стального черепа?
Давайте всего на один день предположим, что Джеймс Кэмерон уже в 1984 году что-то знал и снял не фантастический фильм, а попытался послать нам предупреждение. Что если режиссёр фильма попробовал нас оградить от того, к чему может привести злоупотребление новыми технологиями и насколько мы смогли с их помощью приблизиться к созданию таких машин? Предлагаю сегодня, 1 Апреля 2024 года, провести глубокий и вдумчивый анализ механизмов работы терминатора и вместе найти ответ на этот животрепещущий вопрос.

Привет! Меня зовут Алексей Карпов, я DevOps-инженер (MLOps) отдела ML разработки в OKKO. Хочу поделиться опытом в работе с Apache Airflow в связке с Kubernetes. Расскажу, как установить Airflow в Kubernetes, настроить автоматическую синхронизацию DAG'ов с удалённым репозиторием, а также как отладить его работу. Всё это — на примере запуска простейшего DAGа.
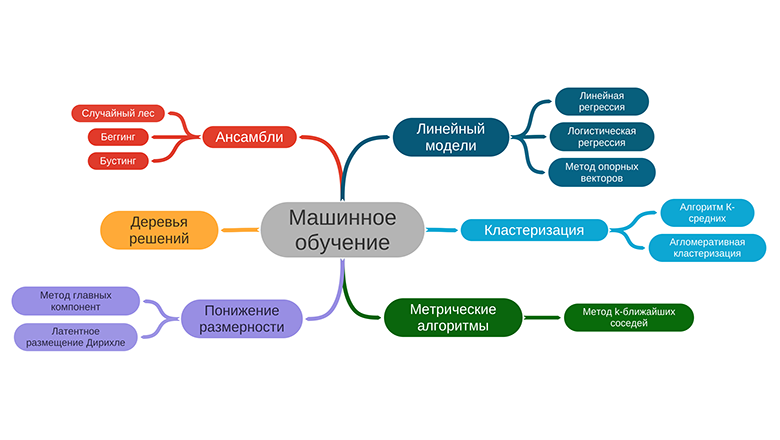
Краткий обзор курса, который я недавно закончил пилить на степике. Курс хардкорный :) В нем необходимо с нуля писать алгоритмы машинного. Наверное это один из лучший способов досконально разобраться в алгоритме.
Курс бесплатный: https://stepik.org/course/68260/promo

Привет, меня зовут Александр Егоров, я MLOps инженер. В статье расскажу о том, как мы в банке выкатываем огромное количество моделей. Разберём не только пайплайн по выкладке отдельных моделей, но и целые каскады.

SQL — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.

Иногда возникают проблемы с развертыванием среды разработки в облаке, ведь бесплатных сервисов с большими облачными вычислительными мощностями почти нет. Тот же Google Collab имеет свои лимиты по использованию GPU, после израсходования всей памяти необходимо ждать сутки. А цена платной версии порой не совсем оправдана... Если у вас есть своя неплохая видеокарта, всегда можно отказаться от облачной разработки и перейти к домашнему варианту.
Напоминаем, что GPU выполняет вычислительную работу быстрее из-за возможности параллельного выполнения процессов. Если вы хотите использовать много видеокарт? то следует подключить ее к одной системе, сформировав своеобразную ферму.
Итак, как же контейнизировать собственную виртуальную среду и развернуть ее с использованием своего GPU?

Коллеги, здарова! Часто бывает что нужно отправить сообщение в мессенджер к разработчикам, в случае возникновения различных проблем.
Представляю небольшое решение, которое позволит отправить сообщение в Telegram с информацией о состоянии DAG`а Apache Airflow

Эта статья рассчитана в большинстве своём на новичков. Тут мы поговорим о том, как не упереться в лимиты подключений к базе, и чтобы приложение в продакшн не упало.


В этой статье мы рассмотрим концепцию Python-оберток и приведем пять примеров, которые могут улучшить процесс разработки на Python.