
В свете исследования "Веб-разработчики пишут небезопасный код по умолчанию" мне подумалось, что именно так может звучать один из базовых вопросов на собеседовании с точки зрения проверки знания web-разработчика от уровня Junior до Senior.
Тема с одной стороны в общем-то простая, а с другой - многогранная. Можно сделать “на коленке”, а можно и “по-взрослому” - зависит от знаний конкретного девелопера и технического задания. Ну и не привязывается к конкретному языку. Что nodejs, что .net, что PHP - на ответы это не влияет. Ну и отлично же! Давайте попробуем.
Я попытался разбить вопросы на три уровня. Каждый следующий уровень обязан включать все вопросы выше, т.е. уровни и вопросы отсортированы от простых к более сложным.
Как бы вы ответили на конкретный вопрос? Попробуйте проверить себя и потратить пару минут на обдумывание прежде чем читать ответ.
Восклицательным знаком ⚠ помечены вопросы, на которых можно "засыпаться" и оставить плохое впечатление о себе у интервьюера. Так же я позволил себе добавить еще пункты, которые подразумевают "Регистрацию", но по касательной. Многие ответы обрамил ссылками, которые помогут разобраться чуть глубже в конкретном вопросе, думаю будет полезно.
Итак, за вёсла!





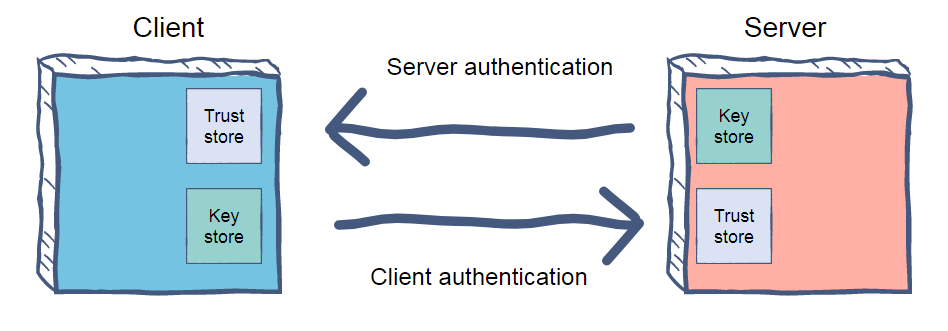
 Оригинал картинки взят у deviniti.com/atlassian
Оригинал картинки взят у deviniti.com/atlassian




