
 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).По долгу работы я примерно 3 года занимаюсь разработкой и поддержкой нескольких проектов, которые используют MongoDB в качестве основной БД, и в этой статье хочу рассказать, почему на мой взгляд с MongoDB далеко не все так просто, как написано в мануалах, и к чему вы должны быть готовы, если вдруг решите взять MongoDB в качестве основной БД в ваш новый модный стартап :-)
Все что описано ниже можно воспроизвести с использованием библиотеки PyMongo для работы с MongoDB из языка программирования Python. Однако скорее всего с аналогичными ситуациями вы можете столкнуться и при использовании других библиотек для других языков программирования.









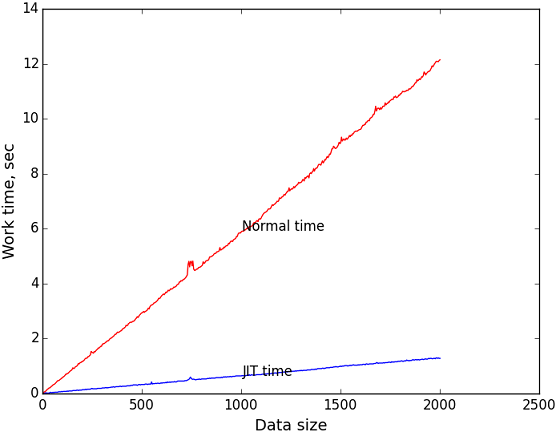
 Ранее я опубликовал две статьи (
Ранее я опубликовал две статьи (
 Eric Ligman, Директор по партнерским программам компании Microsoft, опубликовал в блоге ссылки на большую бесплатную коллекцию книг Microsoft по самым разным направлениям: SharePoint, Visual Studio, Windows Phone, Windows 8, Office 365, Office 2010, SQL Server 2012, Azure, Cloud, Lync, Dynamics CRM и т.д.
Eric Ligman, Директор по партнерским программам компании Microsoft, опубликовал в блоге ссылки на большую бесплатную коллекцию книг Microsoft по самым разным направлениям: SharePoint, Visual Studio, Windows Phone, Windows 8, Office 365, Office 2010, SQL Server 2012, Azure, Cloud, Lync, Dynamics CRM и т.д.