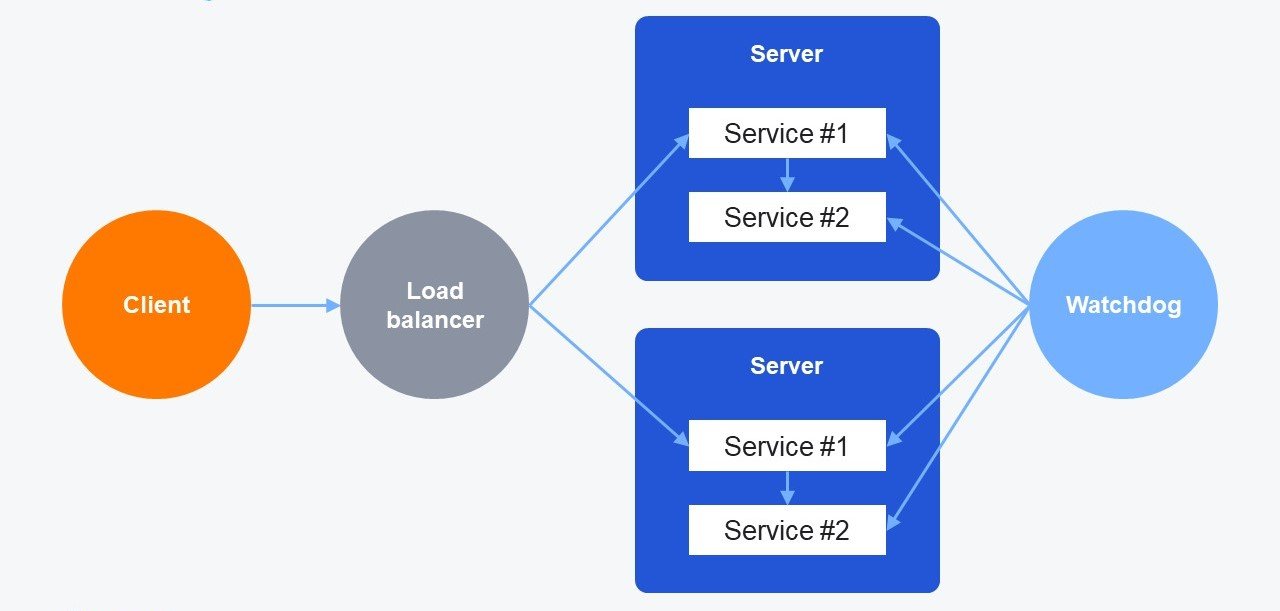
Балансировщики падают, контроллеры зависают, а дата-центры атакуют экскаваторы. Это нормальная история. Мы живём в мире, где нет ничего надёжного на 100 %, а любой бит в планке оперативной памяти может внезапно перещёлкнуться из-за пролетевшей космической частицы.
Другое дело, что даже в условиях постоянных рисков отказа отдельных элементов нам нужно обеспечить работоспособность инфраструктуры в целом. Клиент не должен заметить, что где-то отказал контейнер с php-fpm или одна из серверных стоек выпала из сети.
По роду деятельности мне постоянно приходится сталкиваться с проблемами отказоустойчивости, так как я руководитель разработки в отделе Газпромбанка, обеспечивающем эксплуатацию ML и Big Data-решений. Поэтому сегодня я хочу рассказать о нескольких паттернах отказоустойчивости и типовых решениях при эксплуатации приложения в кластере Kubernetes. Разберём основные паттерны, ну и, конечно, рассмотрим варианты, при которых неправильные настройки прострелят вначале одну ногу, а потом — другую, потому что она слишком медленно стала шагать.