
Ключевые различия между протоколами MCP от Anthropic и A2A от Google.
Почему функции безопасности, управления задачами и возможности совместной работы A2A могут дать ему преимущество в формирующейся экосистеме агентов.

Продакт-менеджер
Ключевые различия между протоколами MCP от Anthropic и A2A от Google.
Почему функции безопасности, управления задачами и возможности совместной работы A2A могут дать ему преимущество в формирующейся экосистеме агентов.

У меня есть две любимые сестры, которые очень хотели бы иметь дома датчик температуры, влажности и углекислого газа. Представленные на рынке готовые решения меня категорически не устраивали, а как говорится: хочешь сделать хорошо - сделай это сам.
В итоге я получил компактный сенсор стоимостью $24 и массу позитивных эмоций во время его разработки.

Smart_U - студенческий проект по созданию метеодатчиков для контроля микроклимата в различных помещениях. В статье рассказывается о разработке проекта, используемых технологиях, возникших ошибках и т.д. Сразу скажу, что набор компонентов довольно банален: микроконтроллеры Atmegа328(168), датчик температуры и влажности HTU21D, датчик интенсивности света MAX44009/BH1750, LoRa для передачи данных и в качестве эксперимента - ёмкостной датчик влажности почвы.

Если вы занимаетесь сбором данных на обширной территории, да еще не охваченной интернетом, возникает задача передачи данных на расстояния, исчисляемые километрами без использования WiFi и сети Ethernet.
В решении этой задачи вам помогут радиомодули, передающие данные с использованием технологии связи на большие расстояния (Long Range, LoRa). Эта технология запатентована компанией Semtech и реализована в микросхемах приемо‑передатчиков (трансиверов), таких как SX1268, SX1276, SX1278.
В зависимости от выходной мощности передатчика, типа антенны, рабочей частоты, наличия прямой видимости или препятствий для прохождения радиоволн в виде домов, леса, помех со стороны других источников радиоизлучения и других факторов дальность может составлять от сотен метров до десятков километров.
К сожалению, скорость передачи данных LoRa невелика, порядка 2400–19 200 бит/c. Однако этого достаточно, например, для систем телеметрии и удаленного контроля, систем умного дома или других подобных систем.
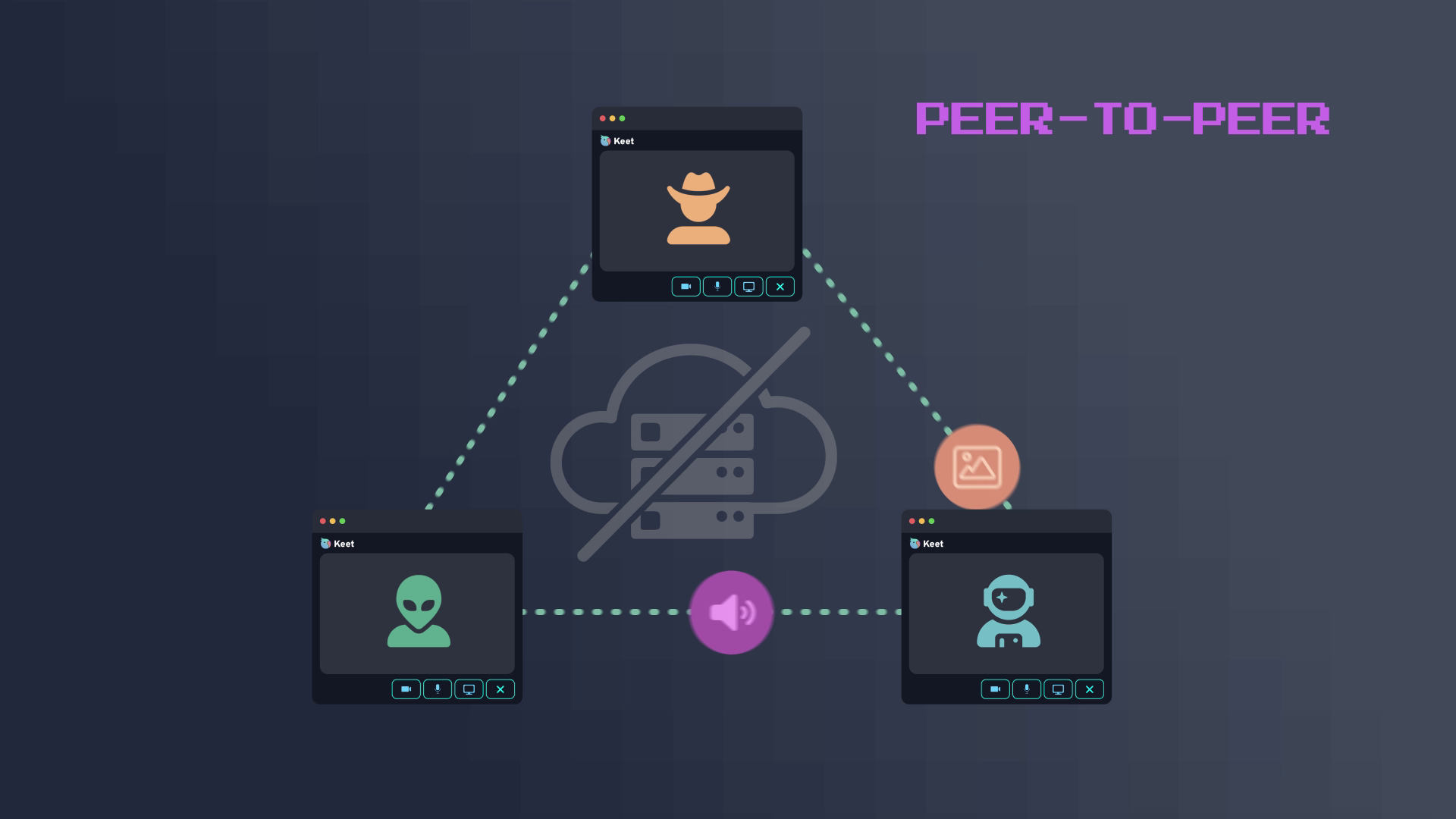

В современном мире IoT, когда связь в отдаленных районах становится все более актуальной, технология LoRa (Long Range) предоставляет нам возможность создать дальнобойный, надежный, энергоэффективный и зашифрованный канал связи без необходимости иметь какую-либо сетевую инфраструктуру.
В этой статье мы рассмотрим, как создать простой LoRa мессенджер с использованием своего протокола обмена и готовых модулей, работающих в режиме P2P (peer-to-peer) – не идеального, но интересного решения для обмена текстовыми сообщениями в условиях ограниченной инфраструктуры.
Для упрощения и автоматизации процесса обмена сообщениями мы воспользуемся Node-RED. Этот инструмент, помимо реализации основной логики обмена сообщениями, также предоставит графический интерфейс для мессенджера, что сделает процесс более доступным и интуитивно понятным.
Выглядеть будет просто, потому что воспользуемся всем готовым :)


Абсолютно легальные инструменты за смешные деньги могут позволить вам: звонить всем активным клиентам ваших конкурентов, построить десяток эффективных мошеннических схем, или даже позвонить предполагаемому любовнику вашей девушки/жены, а заодно проверить где она была вчера вечером! Обнаружил я это в ходе одного из расследований утечек заявок клиентов. И я твердо уверен, что такого быть не должно. Инструмент использующийся в статье эффективнее всех утечек вместе взятых, нашими данными не должны так легко легально торговать практически в режиме онлайн. Можно найти любого и позвонить любому из нас. Почему и как это работает, какие риски это несет и как этому противодействовать?

Как-то мы лежали в кровати с нашим малышом и жена сказала, что фотографий и видео с ним стало больше и она не хочет использовать платное приложение. Примерно так начинается рассказ создателя Immich – бесплатного open-source решения для хранения фотографий и видео.
Надо сказать, в последние годы я тоже регулярно пытался найти бесплатную self-hosted альтернативу Google Photos и iCloud, однако до сегодняшнего дня функциональных и вместе с тем простых в настройке решений я не встречал. Тот же Nextcloud всегда казался чересчур громоздким. Immich же, напротив, сразу завоевал моё сердце, и вот, после нескольких недель его использования, с радостью делюсь своим рабочим примером.

Вчера вечером, 10 января 2024 г., OpenAI официально запустили GPT Store.
Давайте разберемся, что это такое, и что оно дает. А затем создадим свой собственный GPT и добавим его в GPT Store.
Концепция "custom GPT" в терминах OpenAI - это кастомный набор инструкций (custom prompt), который может быть создан любым пользователем ChatGPT с подпиской Plus. Каждый такой custom GPT за счет своего набора инструкций хорошо заточен под решение своей конкретной задачи. Есть custom GPT, которые хорошо пишут код, есть custom GPT, которые играют роль репетитора или психотерапевта и т.д.
Таким образом, GPT store - это большая библиотека инструкций для разных задач внутри ChatGPT. Она создается и поддерживается комьюнити и очень сильно напоминает google play market или apple app store.
Процесс создания Custom GPT заключается в том, что в интерфейсе ChatGPT пользователь составляет подробные инструкции, что и как его GPT должен делать, дает описание, придумывает название, примеры использования и т.д. - всё это сохраняется на серверах OpenAI.

Этот материал посвящён тому, как добавлять собственные данные в предварительно обученные LLM (Large Language Model, большая языковая модель) с применением подхода, основанного на промптах, который называется RAG (Retrieval‑Augmented Generation, генерация ответа с использованием результатов поиска).
Большие языковые модели знают о мире многое, но не всё. Так как обучение таких моделей занимает много времени, данные, использованные в последнем сеансе их обучения, могут оказаться достаточно старыми. И хотя LLM знакомы с общеизвестными фактами, сведения о которых имеются в интернете, они ничего не знают о ваших собственных данных. А это — часто именно те данные, которые нужны в вашем приложении, основанном на технологиях искусственного интеллекта. Поэтому неудивительно то, что уже довольно давно и учёные, и разработчики ИИ‑систем уделяют серьёзное внимание вопросу расширения LLM новыми данными.
До наступления эры LLM модели часто дополняли новыми данными, просто проводя их дообучение. Но теперь, когда используемые модели стали гораздо масштабнее, когда обучать их стали на гораздо больших объёмах данных, дообучение моделей подходит лишь для совсем немногих сценариев их использования. Дообучение особенно хорошо подходит для тех случаев, когда нужно сделать так, чтобы модель взаимодействовала бы с пользователем, используя стиль и тональность высказываний, отличающиеся от изначальных. Один из отличных примеров успешного применения дообучения — это когда компания OpenAI доработала свои старые модели GPT-3.5, превратив их в модели GPT-3.5-turbo (ChatGPT). Первая группа моделей была нацелена на завершение предложений, а вторая — на общение с пользователем в чате. Если модели, завершающей предложения, передавали промпт наподобие «Можешь рассказать мне о палатках для холодной погоды», она могла выдать ответ, расширяющий этот промпт: «и о любом другом походном снаряжении для холодной погоды?». А модель, ориентированная на общение в чате, отреагировала бы на подобный промпт чем‑то вроде такого ответа: «Конечно! Они придуманы так, чтобы выдерживать низкие температуры, сильный ветер и снег благодаря…». В данном случае цель компании OpenAI была не в том, чтобы расширить информацию, доступную модели, а в том, чтобы изменить способ её общения с пользователями. В таких случаях дообучение способно буквально творить чудеса!



Несмотря на то, что я считаю себя криптографом, меня не особенно привлекает слово "крипто". Не думаю, что я уже староват, но я гораздо чаще кликаю на мемы в духе "Интернет всё помнит" о том, как "крипто" раньше означало "криптография", чем на последние новости об NFT.
Но учитывая всё то внимание, которое в последнее время уделяется тому, что сейчас называют web3, я решил более тщательно изучить всё происходящее в этой сфере, чтобы точно ничего не упустить...

Расскажем о проекте, который используют орнитологи-любители и ученые, и библиотеках с записями тысяч песен пернатых — в том числе для коммерческого использования.



При постройке домашней солнечной электростанции, очень многие владельцы наступают на одни и те же грабли, совершают однотипные ошибки. Цена этих ошибок может быть порой очень высокой - как минимум потеря генерации за довольно длительный период, как максимум - потеря станции и самого дома, на котором стоит СЭС. Вы точно готовы заглянуть по ту сторону солнечной энергетики? Тогда прошу под кат!



Последние месяцы ознаменовались бурными баталиями в отечественной индустрии разработки микроэлектроники и причастных. Государство, наконец-то пристально обратив своё око на данную, мягко скажем крайне проблемную отрасль, посулив крупные инвестиции на её развитие, в первую очередь на разработку мозга любой вычислительной техники - процессора. Прения по поводу , как правильно потратить выделенные средства, из тишины министерских кабинетов выплеснулись наружу и дошли до прессы. Не вдаваясь в политические моменты, всегда присущие такого рода дебатам, хотелось бы сконцентрироваться на технической стороне вопроса и обрисовать позицию, почему ставка на легендарный микропроцессор Эльбрус - это тупик для развития отечественного процессоростроени
