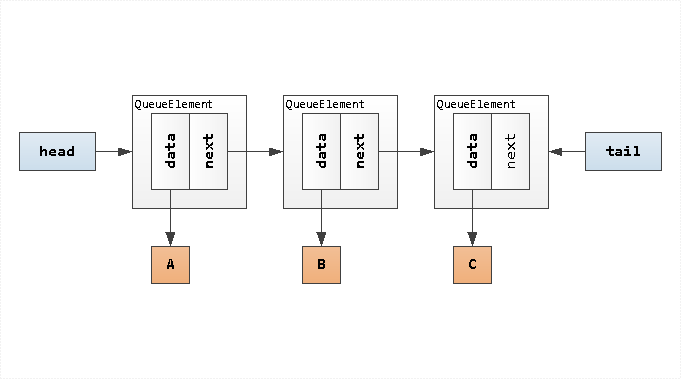
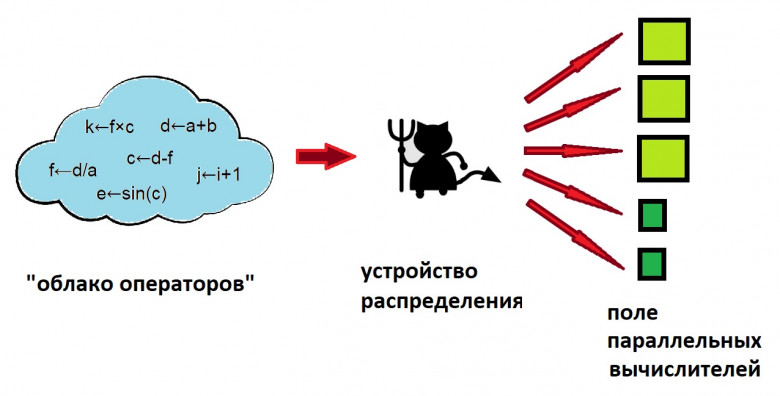
С тех пор как мир возник во мгле
Нет ничего на свете более интересного лично для
Исследователя и одновременно полезного для
Человечества, чем позна́ние окружающего Мира.
Валерий Баканов. Крым, Щёлкино/Казантип, август 2022.
Данная публикация предназначена для Исследователей, которым не жаль с пользой употребить своё время для практического количественного углу́бленного понимания свойств внутреннего (скрытого) параллелизма в алгоритмах и его, на́йденного параллелизма, рационального использования в вычислительных практиках. Рациональное использование имеющегося в алгоритмах параллелизма определяется набором приёмов, позволяющих получить наиболее приемлемый (по разумным параметрам) план (расписание) выполнения рассматриваемого алгоритма (программы) на заданном поле параллельных вычислителей. Т.к. конечная (реализуемая в процессе собственно вычислений) последовательность выполнения команд неминуемо я́вится всё же несколько иной относительно разработанного на данном этап ие плана вычислений, логично назвать результат данного анализа каркасом плана (расписания) параллельных вычислений.
Алгоритм является результатом разумной деятельности человечества и отражает в себе (в опосредованном виде, конечно) наиболее глуби́нные, фундаментальные законы развития Природы. Одно это является вполне обоснованной необходимостью исследования характеристик алгоритмов.
Ряд лет интересом пользовалось изучение параметров вычислительной трудоёмкости (фактически зависимости числа вычислительных операций от размерности обрабатываемых данных) для различных алгоритмов. Параметры параллелизма в алгоритмах – очередная сторона многогранной сущности “алгоритм”. В современной ситуации отечественным разработчикам придётся самостоятельно исследовать и решать все связанные с автоматизированной обработкой данных вопросы – время “неограниченной халявы” (когда можно было десятилетиями бездумно копировать западные разработки в области архитектуры и готовых решений аппаратной и программной частей) закончилось.
Ещё никто на всей земле
Не предава́лся сожаленью
О том, что о́тдал жизнь ученью.
Абу Абдалла́х Рудаки́, Бухара, около 860÷941.