Во втором туре выборов губернатора Приморского края 16 сентября 2018 года встречались действующий и.о. губернатора Андрей Тарасенко и занявший второе место в первом туре коммунист Андрей Ищенко. В ходе подсчета голосов на сайте ЦИК РФ отображалась информационная панель с растущим числом обработанных протоколов и голосов за кандидатов.
Публикация подробных данных по участкам на официальном сайте ЦИК www.izbirkom.ru замерла после ввода 1484 (95.74%) протоколов и не возобновлялась до самого конца. Поэтому когда в трансляции лидер голосования вдруг поменялся с Ищенко на Тарасенко, было неясно, как именно это могло произойти. В СМИ просто писали «после обработки 99,03% протоколов лидер сменился».
Однако, располагая промежуточными суммарными данными из информационной панели, с помощью простой математики и программирования можно подробно установить, что именно происходило с протоколами в ночь после выборов. Используем Python, Colab от Google и Z3 theorem prover от Microsoft Research. Ну и добьём всё обычной дедукцией.
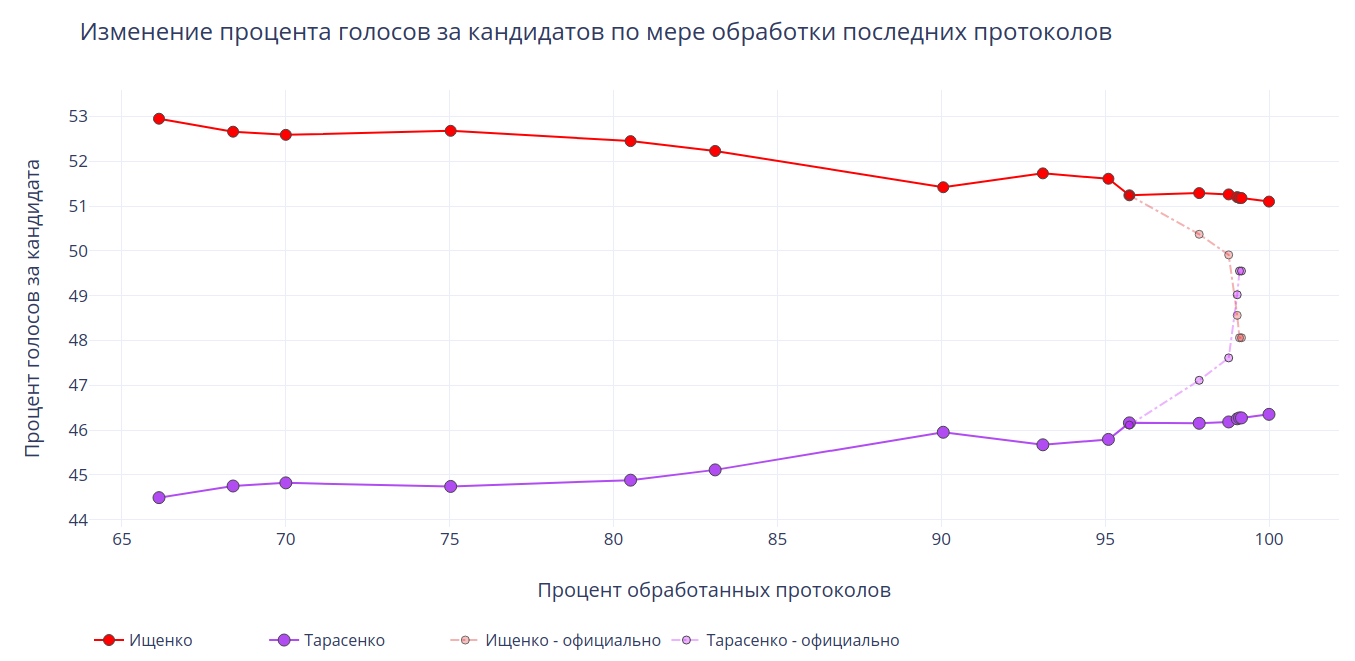
Публикация подробных данных по участкам на официальном сайте ЦИК www.izbirkom.ru замерла после ввода 1484 (95.74%) протоколов и не возобновлялась до самого конца. Поэтому когда в трансляции лидер голосования вдруг поменялся с Ищенко на Тарасенко, было неясно, как именно это могло произойти. В СМИ просто писали «после обработки 99,03% протоколов лидер сменился».
Однако, располагая промежуточными суммарными данными из информационной панели, с помощью простой математики и программирования можно подробно установить, что именно происходило с протоколами в ночь после выборов. Используем Python, Colab от Google и Z3 theorem prover от Microsoft Research. Ну и добьём всё обычной дедукцией.