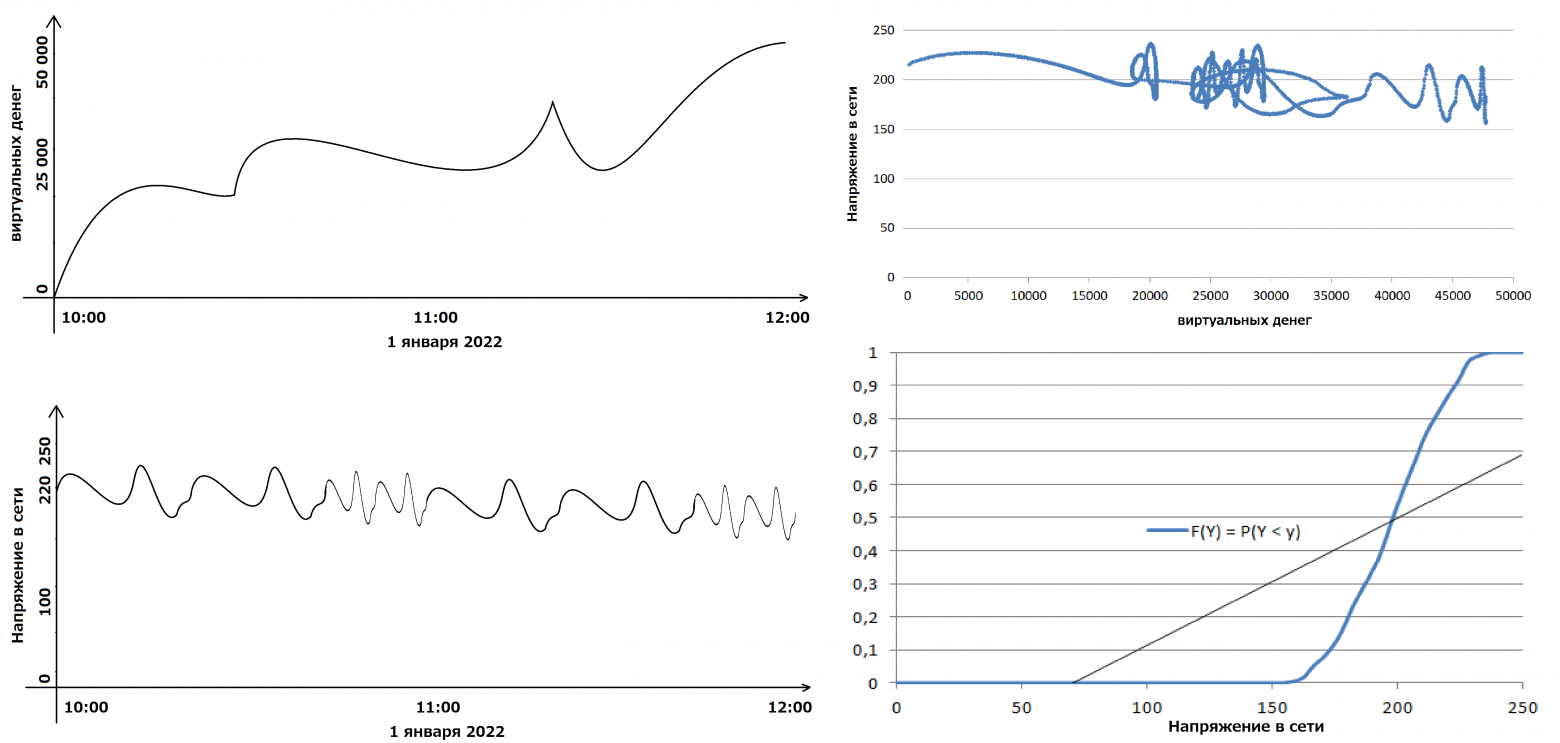
Функциональные зависимости – концепция, которой уже много десятков лет, её преподают практически в каждом курсе баз данных. Их классическое применение – нормализация схемы данных. В последние годы у концепции появилось множество иных приложений в контексте data science, касающиеся эксплорации и очистки данных.
В статье мы расскажем о функциональных зависимостях (точных и приближенных), опишем, что с ними можно делать в контексте работы с данными, и покажем, что с ними умеет делать наш профайлер Desbordante. Статья является продолжением нашей прошлой статьи, в которой мы рассказали о профилировании данных.