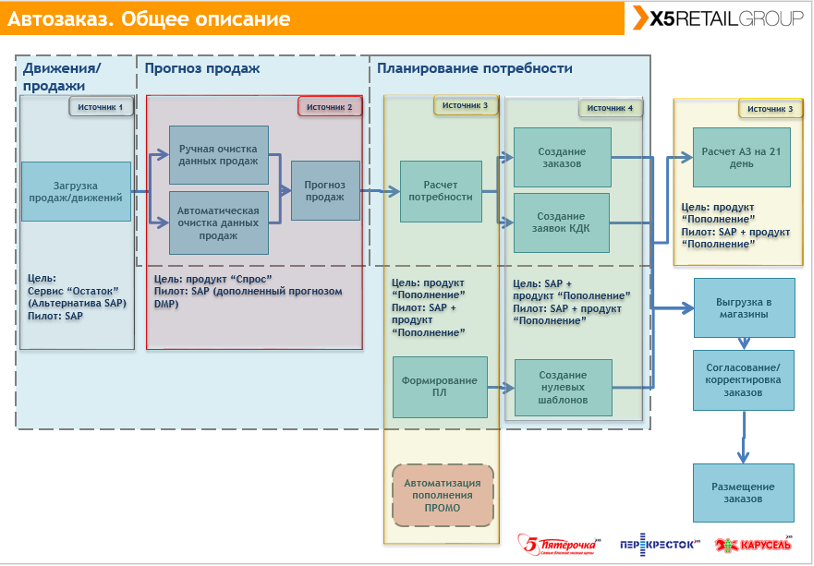
Всем привет! Меня зовут Константин Измайлов, я руководитель направления Data Science в Delivery Club. Мы работаем над многочисленными интересными и сложными задачами: от формирования классических аналитических отчетов до построения рекомендательных моделей в ленте приложения.
Сегодня я расскажу про одну из задач, которую мы решали: про автоматизацию построения зон доставки ресторанов. Зона доставки — это область вокруг заведения, и когда вы в ней находитесь, этот ресторан отображается в списке доступных для заказа. Несмотря на всю простоту формулировки, построение зон доставки ресторанов достаточно непростая задача, в которой встречается много подводных камней не только со стороны технической реализации, но и на этапе внедрения. Я расскажу про предпосылки появления этой задачи, подходы (от более простого к сложному) и подробно рассмотрю алгоритм построения зоны доставки.
Статья будет полезна не только техническим специалистам, которые могут вдохновиться нашими подходами по работе с геоданными, но и менеджерам, которые смогут прочитать про процесс интеграции нашей модели в бизнес, увидев «грабли», а самое главное — результаты, которых удалось добиться.
Статья написана по мотивам выступления с Евгением Макиным на конференции
Highload++ Весна 2021. Для тех, кто любит видео, — ищите его в конце статьи.