Месяц назад я
попытался сосчитать, сколько разных инструкций поддерживается современными процессорами, и насчитал 945 в Ice Lake. Комментаторы
затронули интересный вопрос: какая часть всего этого разнообразия реально используется компиляторами? Например, некто Pepijn de Vos в 2016
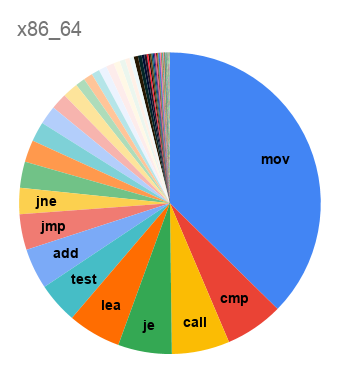
подсчитал, сколько разных инструкций задействовано в бинарниках у него в /usr/bin, и насчитал 411 — т.е. примерно треть всех инструкций x86_64, существовавших на тот момент, не использовались ни в одной из стандартных программ в его ОС. Другая любопытная его находка — что код для x86_64 на треть состоит из инструкций
mov. (В общем-то
известно, что одних инструкций
mov достаточно, чтобы написать любую программу.)
Я решил развить исследование de Vos, взяв в качестве «эталонного кода» компилятор LLVM/Clang. У него сразу несколько преимуществ перед содержимым /usr/bin неназванной версии неназванной ОС:
- С ним удобно работать: это один огромный бинарник, по размеру сопоставимый со всем содержимым /usr/bin среднестатистического линукса;
- Он позволяет сравнить разные ISA: на releases.llvm.org/download.html доступны официальные бинарники для x86, ARM, SPARC, MIPS и PowerPC;
- Он позволяет отследить исторические тренды: официальные бинарники доступны для всех релизов начиная с 2003;
- Наконец, в исследовании компиляторов логично использовать компилятор и в качестве подопытного объекта :-)
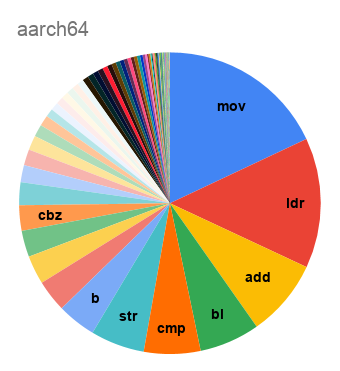
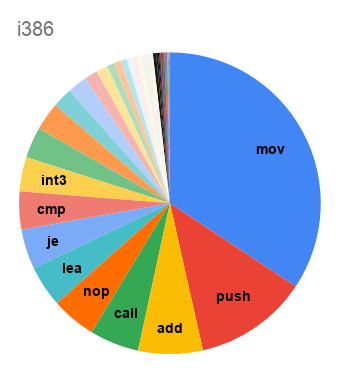
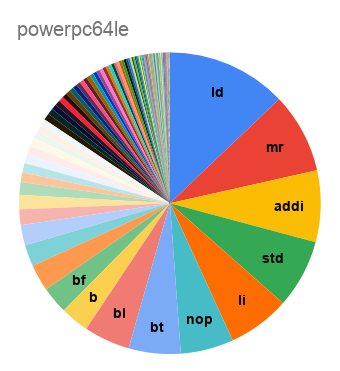
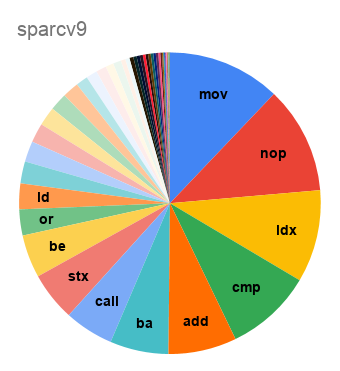
Начну со статистики по мартовскому релизу LLVM 10.0:
В прошлом топике комментаторы
упомянули, что самый компактный код у них получается для SPARC. Здесь же видим, что бинарник для AArch64 оказывается на треть меньше что по размеру, что по общему числу инструкций.
А вот распределение по числу инструкций: